なぜTransformerがRNNやLSTMに取って代わったのか
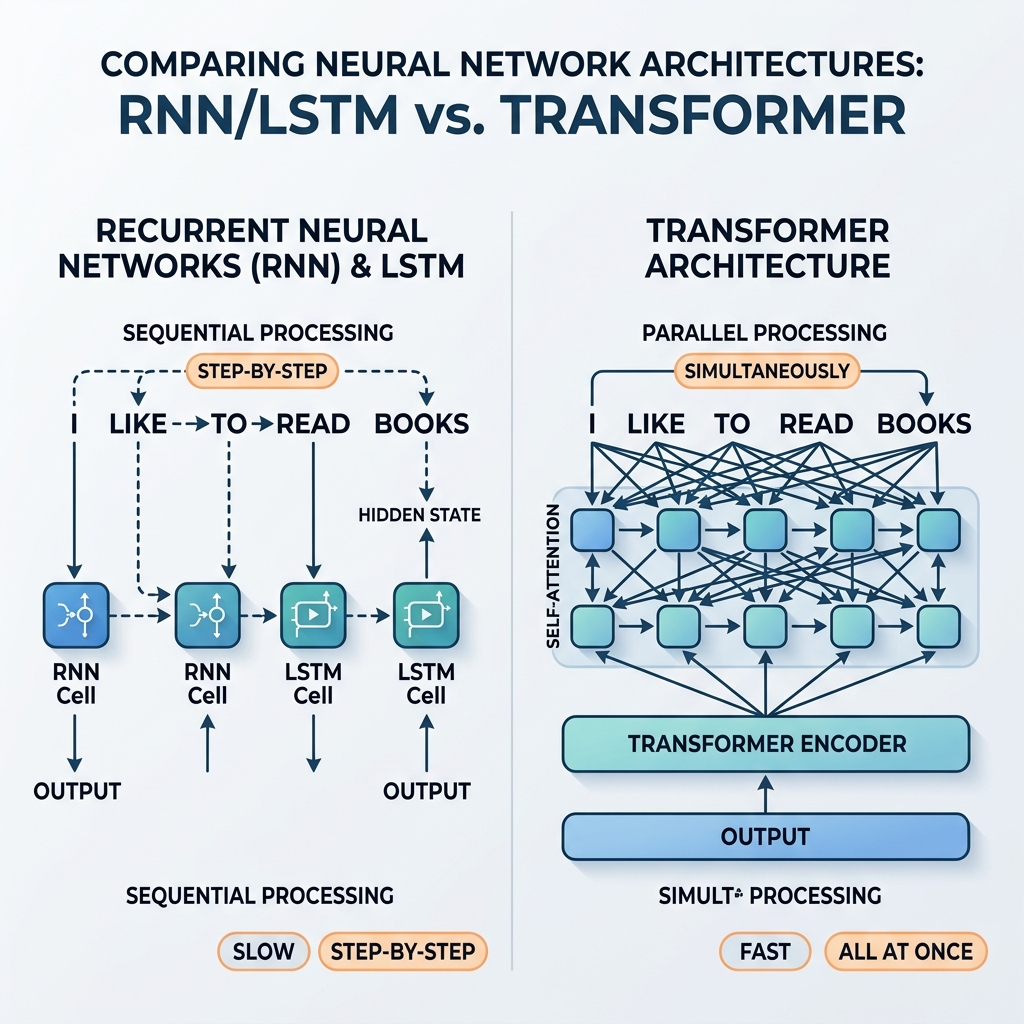
長年にわたり、リカレントニューラルネットワーク(RNN)と長短期記憶(LSTM)ネットワークは、シーケンシャルデータ処理の絶対的な王者でした。これらは、最先端の翻訳システム、音声アシスタント、およびテキスト生成モデルを支えていました。しかし、2017年に発表された画期的な論文 「Attention Is All You Need」(Vaswaniら)によって、Transformerアーキテクチャが導入されました。その後数年で、RNNやLSTMは主流のAIモデルからほぼ完全に姿を消しました。
なぜこれほど急速な移行が起こったのでしょうか?Transformerがリカレント構造に対して構造的に優れている理由は何でしょうか?この記事では、RNN/LSTMの数学的およびアーキテクチャ的なボトルネックと、Transformerがそれらをどのように克服したかを探ります。
1. 核心的なボトルネック:シーケンシャル処理の限界
RNNを定義する最大の特徴は、その再帰的な状態遷移です。入力シーケンスを処理するために、ネットワークは各トークンを一度にステップずつ処理し、現在の入力 $x_t$ と直前の隠れ状態 $h_{t-1}$ に基づいて、内部の隠れ状態 $h_t$ を更新します。
数学的な再帰関係は次のように表されます。
$$h_t = \tanh(W_{hh} h_{t-1} + W_{xh} x_t + b)$$
並列化の問題
$h_t$ は直接 $h_{t-1}$ に依存するため、処理を並列化することができません。文の中の100番目の単語の状態を計算するには、ネットワークは最初の99個の状態を順番に計算しなければなりません。
GPUやTPUが大規模な並列行列計算をサポートするように進化するにつれて、このシーケンシャルな依存関係は重大なボトルネックになりました。大規模なWebデータセットで深いRNNモデルをトレーニングするのには何週間もかかりましたが、計算が独立していれば、ハードウェアはより高速に動作する能力を持っていました。
2. 情報のボトルネック:勾配消失問題
シーケンス長 $N$ が増加するにつれて、時間を介した誤差逆伝播法(BPTT)では、再帰重み $W_{hh}$ との行列積を繰り返す必要があります。$W_{hh}$ の最大固有値が1未満の場合、勾配は指数関数的に縮小します(勾配消失)。1より大きい場合、それらは指数関数的に増加します(勾配爆発)。
$$\frac{\partial E_t}{\partial h_1} = \frac{\partial E_t}{\partial h_t} \prod_{k=2}^{t} \frac{\partial h_k}{\partial h_{k-1}}$$
LSTMとメモリ制限
LSTMはセル状態とゲート機構(忘却ゲート、入力ゲート、出力ゲート)を導入し、勾配が線形に流れるようにすることで勾配消失を緩和しました。しかし、LSTMであっても数百トークンを超える長さのシーケンスでは苦戦します。隠れベクトルは、過去のすべてのトークンの履歴を固定サイズの表現に圧縮することを強制されるため、「忘却」効果が生じます。
3. Transformerがどのように再帰問題を解決したか
Transformerは再帰を完全に取り除き、自己アテンション(Self-Attention)メカニズムに置き換えました。ステップバイステップの状態伝播の代わりに、自己アテンションはシーケンス内のすべてのトークンが同時に他のすべてのトークンと直接相互作用することを可能にします。
アテンション行列は以下のように計算されます。
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{Q K^T}{\sqrt{d_k}}\right) V$$
Transformerは次のようにしてRNNのボトルネックを解決します。
- 大規模な並列化: 位置の間にシーケンシャルな依存関係がないため、入力シーケンス内のすべてのトークンが同時に処理されます。計算グラフが浅く、並列化が容易なため、GPUを限界まで活用できます。
- 一定のパス長: 任意の2つのトークン間のパス長は $\mathcal{O}(1)$ です。これにより、長いシーケンスでの勾配消失問題が解消され、モデルは何千(さらには何百万)ものトークンの文脈を容易に処理できます。
- 位置エンコーディング: 自己アテンションには固有のシーケンス順序が存在しないため、Transformerは単語の順序を保持するために、入力埋め込みに**位置エンコーディング(Positional Encodings)**を注入します。
4. PyTorchによるシーケンス処理の比較
以下のコードスニペットは、RNNセルの順次ループ設計と自己アテンションレイヤーの並列行列計算を比較したものです。
import torch
import torch.nn as nn
import time
batch_size = 32
seq_len = 512
embedding_dim = 128
# 入力: [batch_size, seq_len, embedding_dim]
x = torch.randn(batch_size, seq_len, embedding_dim)
# 1. リカレント処理 (RNNセル)
class CustomRNN(nn.Module):
def __init__(self, dim):
super().__init__()
self.rnn_cell = nn.RNNCell(dim, dim)
def forward(self, x):
h = torch.zeros(x.size(0), x.size(2), device=x.device)
# タイムステップに沿った順次ループ (並列化不可)
for t in range(x.size(1)):
h = self.rnn_cell(x[:, t, :], h)
return h
# 2. 並列処理 (自己アテンションレイヤー)
class CustomSelfAttention(nn.Module):
def __init__(self, dim):
super().__init__()
self.num_heads = 4
self.mha = nn.MultiheadAttention(dim, self.num_heads, batch_first=True)
def forward(self, x):
# 全タイムステップにわたる並列行列積
attn_out, _ = self.mha(x, x, x)
return attn_out
rnn = CustomRNN(embedding_dim)
attention = CustomSelfAttention(embedding_dim)
# RNNの順次ループの実行時間を測定
start = time.time()
rnn_out = rnn(x)
rnn_time = time.time() - start
# 自己アテンションの並列実行の実行時間を測定
start = time.time()
attn_out = attention(x)
attn_time = time.time() - start
print(f"RNN実行時間 (順次ループ): {rnn_time * 1000:.2f} ms")
print(f"Attention実行時間 (並列行列): {attn_time * 1000:.2f} ms")
5. アーキテクチャ比較のまとめ
| 特徴 | RNN / LSTM | Transformer |
|---|---|---|
| 順次処理ステップ | $\mathcal{O}(N)$ | $\mathcal{O}(1)$ |
| レイヤーあたりの計算複雑度 | $\mathcal{O}(N \cdot d^2)$ | $\mathcal{O}(N^2 \cdot d)$ |
| 最大パス長 | $\mathcal{O}(N)$ | $\mathcal{O}(1)$ |
| 並列化能力 | 限定的 / 不可能 | 極めて高い並列性 |
| 長距離依存関係のモデリング | 不十分 (忘却する) | 優秀 (一定パス長) |
結論
RNNからTransformerへの移行は、計算効率と容量によって推進されました。シーケンシャルな再帰処理を並列の自己アテンションに置き換えることで、Transformerはモデルの規模とデータセットのサイズを指数関数的に拡張する能力を解放しました。この構造的な突破口が、リカレントアーキテクチャではトレーニングが計算上不可能であったGPTやClaudeのような、現代の大規模言語モデル(LLM)への道を開きました。