Warum Transformer RNNs und LSTMs abgelöst haben
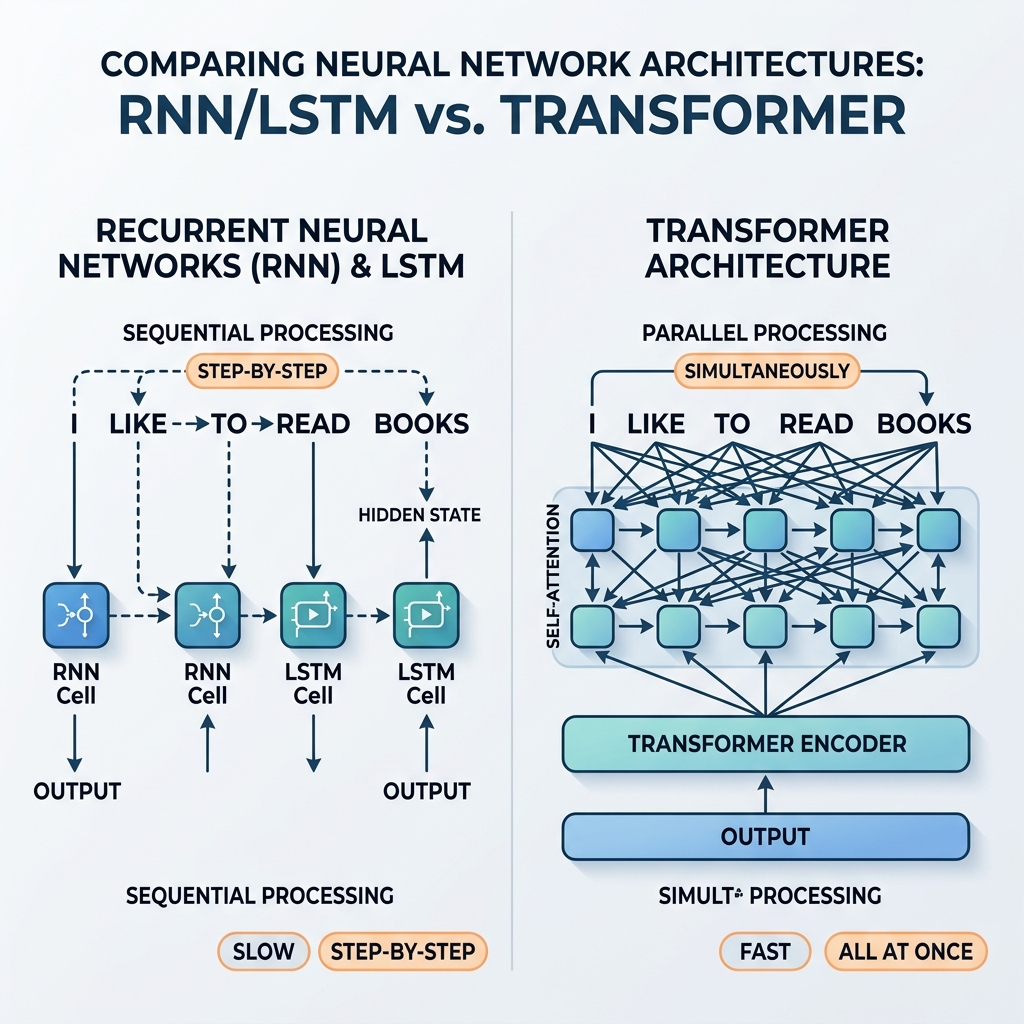
Jahrelang waren Recurrent Neural Networks (RNNs) und Long Short-Term Memory (LSTM) Netzwerke die unbestrittenen Champions der sequentiellen Datenverarbeitung. Sie trieben modernste Übersetzungssysteme, Sprachassistenten und Textgenerierungsmodelle an. Im Jahr 2017 führte das bahnbrechende Paper „Attention Is All You Need“ (Vaswani et al.) jedoch die Transformer-Architektur ein. Innerhalb weniger Jahre wurden RNNs und LSTMs fast vollständig aus den gängigen KI-Modellen verdrängt.
Warum kam es zu diesem raschen Übergang? Was macht den Transformer der Rekursion strukturell so überlegen? Dieser Artikel untersucht die mathematischen und architektonischen Engpässe von RNNs/LSTMs und wie Transformer sie überwunden haben.
1. Der Kernengpass: Sequentieller Flaschenhals
Das definierende Merkmal eines RNN ist sein rekursiver Zustandsübergang. Um eine Sequenz von Eingaben zu verarbeiten, verarbeitet das Netzwerk jedes Token Schritt für Schritt und aktualisiert seinen internen verborgenen Zustand $h_t$ basierend auf der aktuellen Eingabe $x_t$ und dem vorherigen verborgenen Zustand $h_{t-1}$.
Die mathematische Rekursionsbeziehung wird wie folgt dargestellt:
$$h_t = \tanh(W_{hh} h_{t-1} + W_{xh} x_t + b)$$
Das Parallelisierungsproblem
Da $h_t$ direkt von $h_{t-1}$ abhängt, kann die Verarbeitung nicht parallelisiert werden. Um den Zustand des 100. Wortes in einem Satz zu berechnen, muss das Netzwerk nacheinander die ersten 99 Zustände berechnen.
Da sich GPUs und TPUs dahingehend entwickelt haben, massive parallele Matrixberechnungen zu unterstützen, wurde diese sequentielle Abhängigkeit zu einem kritischen Engpass. Das Training tiefer RNN-Modelle auf großen Webdatensätzen dauerte Wochen, während die Hardware in der Lage gewesen wäre, viel schneller zu laufen, wenn die Berechnungen unabhängig gewesen wären.
2. Der Informationsengpass: Verschwindende Gradienten
Wenn die Sequenzlänge $N$ zunimmt, erfordert die Backpropagation durch die Zeit (BPTT) wiederholte Matrixmultiplikationen mit dem Rekursionsgewicht $W_{hh}$. Wenn der größte Eigenwert von $W_{hh}$ kleiner als 1 ist, schrumpfen die Gradienten exponentiell (verschwindende Gradienten). Wenn er größer als 1 ist, wachsen sie exponentiell (explodierende Gradienten).
$$\frac{\partial E_t}{\partial h_1} = \frac{\partial E_t}{\partial h_t} \prod_{k=2}^{t} \frac{\partial h_k}{\partial h_{k-1}}$$
LSTMs und die Speicherbeschränkung
LSTMs führten den Zellzustand und Gating-Mechanismen (Forget Gate, Input Gate, Output Gate) ein, um Gradienten linear fließen zu lassen und verschwindende Gradienten abzumildern. Aber selbst LSTMs haben Probleme mit Sequenzen, die länger als ein paar hundert Token sind. Die verborgenen Vektoren sind gezwungen, die Historie aller vorherigen Token in einer Darstellung fester Größe zu komprimieren, was zu einem „Vergessenseffekt“ führt.
3. Wie Transformer das Rekursionsproblem gelöst haben
Der Transformer verwarf die Rekursion vollständig und ersetzte sie durch den Self-Attention-Mechanismus. Anstelle einer schrittweisen Zustandsfortpflanzung ermöglicht Self-Attention jedem Token, gleichzeitig direkt mit jedem anderen Token in der Sequenz zu interagieren.
Die Aufmerksamkeitsmatrix (Attention Matrix) wird berechnet mittels:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{Q K^T}{\sqrt{d_k}}\right) V$$
So löst der Transformer die RNN-Engpässe:
- Massive Parallelisierung: Da es keine sequentiellen Abhängigkeiten zwischen den Positionen gibt, werden alle Token in der Eingabesequenz gleichzeitig verarbeitet. Der Berechnungsgraph ist flach und hochgradig parallelisierbar, wodurch GPUs maximal ausgelastet werden.
- Konstante Pfadlänge: Die Pfadlänge zwischen zwei beliebigen Token beträgt $\mathcal{O}(1)$. Dies eliminiert das Problem verschwindender Gradienten bei langen Sequenzen und ermöglicht es Modellen, Kontexte von Tausenden (oder sogar Millionen) von Token problemlos zu verarbeiten.
- Positions-Kodierungen: Da es bei der Self-Attention keine inhärente Sequenzreihenfolge gibt, fügt der Transformer Positions-Kodierungen in die Eingabe-Embeddings ein, um die Wortreihenfolge beizubehalten.
4. PyTorch Sequenzverarbeitungsvergleich
Das folgende Code-Snippet vergleicht das sequentielle Schleifendesign einer RNN-Zelle mit der parallelen Matrixberechnung einer Self-Attention-Schicht:
import torch
import torch.nn as nn
import time
batch_size = 32
seq_len = 512
embedding_dim = 128
# Eingaben: [batch_size, seq_len, embedding_dim]
x = torch.randn(batch_size, seq_len, embedding_dim)
# 1. Rekurrente Verarbeitung (RNN-Zelle)
class CustomRNN(nn.Module):
def __init__(self, dim):
super().__init__()
self.rnn_cell = nn.RNNCell(dim, dim)
def forward(self, x):
h = torch.zeros(x.size(0), x.size(2), device=x.device)
# Sequentielle Schleife über Zeitschritte (kann nicht parallelisiert werden)
for t in range(x.size(1)):
h = self.rnn_cell(x[:, t, :], h)
return h
# 2. Parallele Verarbeitung (Self-Attention-Schicht)
class CustomSelfAttention(nn.Module):
def __init__(self, dim):
super().__init__()
self.num_heads = 4
self.mha = nn.MultiheadAttention(dim, self.num_heads, batch_first=True)
def forward(self, x):
# Parallele Matrixmultiplikation über alle Zeitschritte hinweg
attn_out, _ = self.mha(x, x, x)
return attn_out
rnn = CustomRNN(embedding_dim)
attention = CustomSelfAttention(embedding_dim)
# Benchmark RNN sequentielle Schleife
start = time.time()
rnn_out = rnn(x)
rnn_time = time.time() - start
# Benchmark Self-Attention parallele Ausführung
start = time.time()
attn_out = attention(x)
attn_time = time.time() - start
print(f"RNN-Zeit (Sequentielle Schleife): {rnn_time * 1000:.2f} ms")
print(f"Attention-Zeit (Parallele Matrix): {attn_time * 1000:.2f} ms")
5. Zusammenfassung des architektonischen Vergleichs
| Eigenschaft | RNN / LSTM | Transformer |
|---|---|---|
| Sequentielle Operationen | $\mathcal{O}(N)$ | $\mathcal{O}(1)$ |
| Rechenkomplexität pro Schicht | $\mathcal{O}(N \cdot d^2)$ | $\mathcal{O}(N^2 \cdot d)$ |
| Maximale Pfadlänge | $\mathcal{O}(N)$ | $\mathcal{O}(1)$ |
| Parallelisierung | Eingeschränkt / Unmöglich | Hochgradig parallelisierbar |
| Langfristige Abhängigkeiten | Schlecht (Vergisst) | Ausgezeichnet (Konstanter Pfad) |
Fazit
Der Wechsel von RNNs zu Transformern wurde durch Recheneffizienz und Kapazität angetrieben. Durch das Ersetzen sequentieller Rekursion durch parallele Self-Attention eröffneten Transformer die Möglichkeit, Modellgröße und Datensatzgröße exponentiell zu skalieren. Dieser strukturelle Durchbruch ebnete den Weg für moderne große Sprachmodelle (LLMs) wie GPT und Claude, deren Training mit rekurrenten Architekturen rechnerisch unmöglich gewesen wäre.
Entdecken Sie weitere technische Einblicke im Ghaznix-Blog →