Perché i Transformer hanno sostituito le reti RNN e LSTM
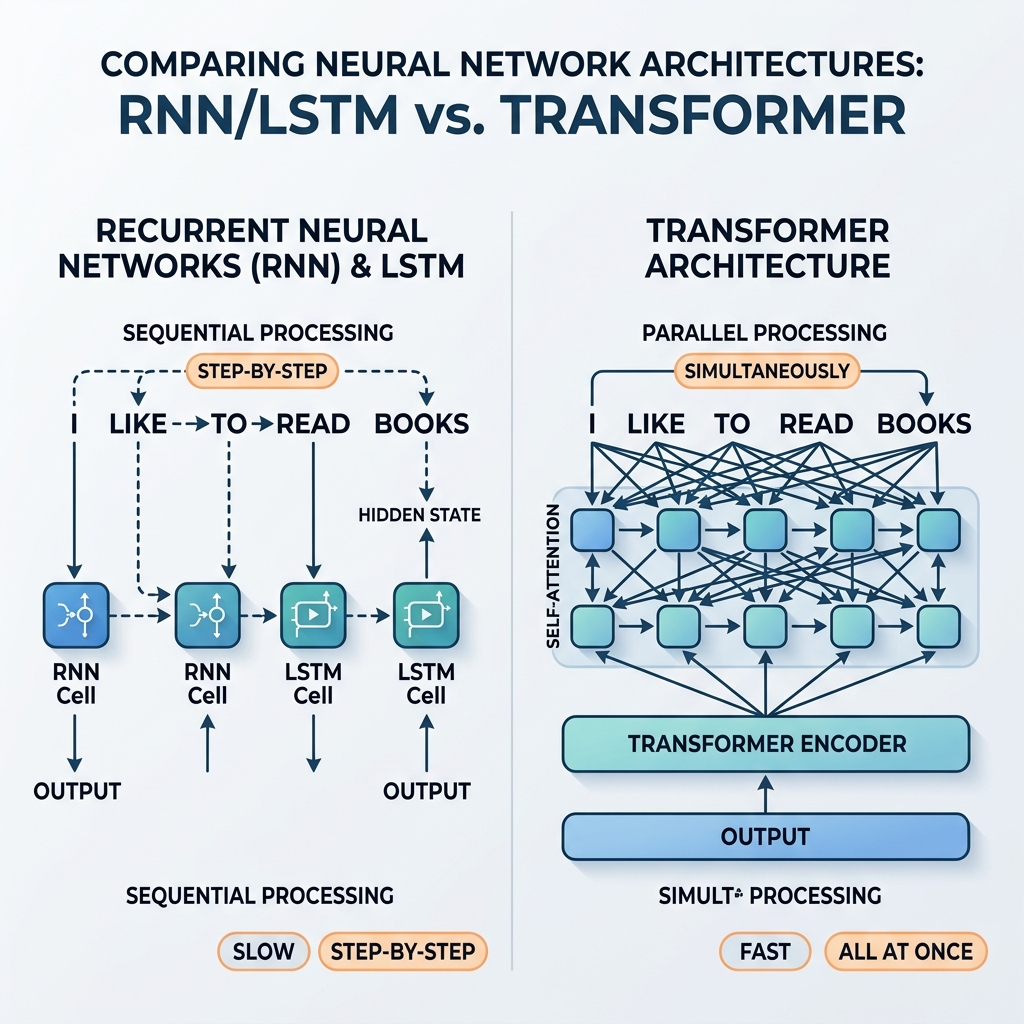
Per anni, le reti neurali ricorrenti (RNN) e le reti Long Short-Term Memory (LSTM) sono state le campionesse indiscusse dell’elaborazione di dati sequenziali. Hanno alimentato sistemi di traduzione all’avanguardia, assistenti vocali e modelli di generazione del testo. Tuttavia, nel 2017, l’articolo seminale “Attention Is All You Need” (Vaswani et al.) ha introdotto l’architettura Transformer. Nel giro di pochi anni, RNN e LSTM sono state quasi interamente eliminate dai modelli di intelligenza artificiale tradizionali.
Perché è avvenuta questa rapida transizione? Cosa rende il Transformer così strutturalmente superiore alla ricorrenza? Questo articolo esplora i colli di bottiglia matematici e strutturali di RNN/LSTM e come i Transformer li hanno superati.
1. Il collo di bottiglia principale: il vincolo sequenziale
La caratteristica distintiva di una RNN è la sua transizione di stato ricorsiva. Per elaborare una sequenza di input, la rete elabora ogni token un passaggio alla volta, aggiornando il suo stato nascosto interno $h_t$ in base all’input corrente $x_t$ e allo stato nascosto precedente $h_{t-1}$.
La relazione di ricorrenza matematica è rappresentata come:
$$h_t = \tanh(W_{hh} h_{t-1} + W_{xh} x_t + b)$$
Il problema della parallelizzazione
Poiché $h_t$ dipende direttamente da $h_{t-1}$, l’elaborazione non può essere parallelizzata. Per calcolare lo stato della centesima parola in una frase, la rete deve calcolare sequenzialmente i primi 99 stati.
Con l’evoluzione di GPU e TPU per supportare calcoli di matrici paralleli massivi, questa dipendenza sequenziale è diventata un collo di bottiglia critico. L’addestramento di modelli RNN profondi su grandi set di dati web richiedeva settimane, mentre l’hardware era in grado di funzionare molto più velocemente se i calcoli fossero stati indipendenti.
2. Il collo di bottiglia delle informazioni: gradienti che svaniscono
Con l’aumentare della lunghezza della sequenza $N$, la retropropagazione del gradiente nel tempo (BPTT) richiede la moltiplicazione ripetuta di matrici con il peso di ricorrenza $W_{hh}$. Se l’autovalore massimo di $W_{hh}$ è minore di 1, i gradienti si riducono esponenzialmente (vanishing gradient). Se è maggiore di 1, crescono esponenzialmente (exploding gradient).
$$\frac{\partial E_t}{\partial h_1} = \frac{\partial E_t}{\partial h_t} \prod_{k=2}^{t} \frac{\partial h_k}{\partial h_{k-1}}$$
Le LSTM e il vincolo di memoria
Le LSTM hanno introdotto lo stato della cella e i meccanismi di gating (forget gate, input gate, output gate) per consentire ai gradienti di fluire linearmente, mitigando il problema dei gradienti che svaniscono. Tuttavia, anche le LSTM hanno difficoltà con sequenze più lunghe di poche centinaia di token. I vettori nascosti sono costretti a comprimere la cronologia di tutti i token precedenti in una rappresentazione a dimensione fissa, portando a un effetto di “oblio”.
3. In che modo i Transformer hanno risolto il problema della ricorrenza
Il Transformer ha scartato completamente la ricorrenza, sostituendola con il meccanismo di Self-Attention. Invece della propagazione dello stato passo-passo, la Self-Attention consente a ciascun token di interagire direttamente con ogni altro token nella sequenza contemporaneamente.
La matrice di attenzione viene calcolata utilizzando:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{Q K^T}{\sqrt{d_k}}\right) V$$
Ecco come il Transformer risolve i colli di bottiglia delle RNN:
- Parallelizzazione massiva: Poiché non vi sono dipendenze sequenziali tra le posizioni, tutti i token nella sequenza di input vengono elaborati contemporaneamente. Il grafico computazionale è piatto e altamente parallelizzabile, sfruttando al massimo le GPU.
- Lunghezza costante del percorso: La lunghezza del percorso tra due token qualsiasi è $\mathcal{O}(1)$. Ciò elimina il problema del gradiente evanescente su sequenze lunghe, consentendo ai modelli di gestire facilmente contesti di migliaia (o addirittura milioni) di token.
- Codifica posizionale: Poiché non vi è alcun ordine sequenziale intrinseco nella Self-Attention, il Transformer inserisce Codifiche Posizionali (Positional Encodings) negli embedding di input per preservare l’ordine delle parole.
4. Confronto dell’elaborazione di sequenze in PyTorch
Il frammento di codice seguente confronta il design a ciclo sequenziale di una cella RNN con il calcolo di matrice parallelo di un livello di Self-Attention:
import torch
import torch.nn as nn
import time
batch_size = 32
seq_len = 512
embedding_dim = 128
# Input: [batch_size, seq_len, embedding_dim]
x = torch.randn(batch_size, seq_len, embedding_dim)
# 1. Elaborazione ricorrente (cella RNN)
class CustomRNN(nn.Module):
def __init__(self, dim):
super().__init__()
self.rnn_cell = nn.RNNCell(dim, dim)
def forward(self, x):
h = torch.zeros(x.size(0), x.size(2), device=x.device)
# Ciclo sequenziale sui passaggi temporali (non può essere parallelizzato)
for t in range(x.size(1)):
h = self.rnn_cell(x[:, t, :], h)
return h
# 2. Elaborazione parallela (livello Self-Attention)
class CustomSelfAttention(nn.Module):
def __init__(self, dim):
super().__init__()
self.num_heads = 4
self.mha = nn.MultiheadAttention(dim, self.num_heads, batch_first=True)
def forward(self, x):
# Moltiplicazione di matrici parallele su tutti i passaggi temporali
attn_out, _ = self.mha(x, x, x)
return attn_out
rnn = CustomRNN(embedding_dim)
attention = CustomSelfAttention(embedding_dim)
# Benchmark ciclo sequenziale RNN
start = time.time()
rnn_out = rnn(x)
rnn_time = time.time() - start
# Benchmark esecuzione parallela Self-Attention
start = time.time()
attn_out = attention(x)
attn_time = time.time() - start
print(f"Tempo RNN (ciclo sequenziale): {rnn_time * 1000:.2f} ms")
print(f"Tempo Attention (matrice parallela): {attn_time * 1000:.2f} ms")
5. Riepilogo del confronto strutturale
| Caratteristica | RNN / LSTM | Transformer |
|---|---|---|
| Operazioni sequenziali | $\mathcal{O}(N)$ | $\mathcal{O}(1)$ |
| Complessità computazionale per livello | $\mathcal{O}(N \cdot d^2)$ | $\mathcal{O}(N^2 \cdot d)$ |
| Lunghezza massima del percorso | $\mathcal{O}(N)$ | $\mathcal{O}(1)$ |
| Parallelizzazione | Limitata / Impossibile | Altamente parallelizzabile |
| Dipendenze a lungo raggio | Scarse (Dimentica) | Eccellenti (Percorso costante) |
Conclusione
Il passaggio dalle RNN ai Transformer è stato guidato dall’efficienza computazionale e dalla capacità. Sostituendo la ricorrenza sequenziale con la Self-Attention parallela, i Transformer hanno sbloccato la capacità di ridimensionare le dimensioni del modello e del set di dati in modo esponenziale. Questa svolta strutturale ha spianato la strada ai moderni modelli linguistici di grandi dimensioni (LLM) come GPT e Claude, il cui addestramento sarebbe stato computazionalmente impossibile con le architetture ricorrenti.
Esplora altre prospettive tecnologiche sul Blog di Ghaznix →