מדוע הטרנספורמרים החליפו את ה-RNN וה-LSTM
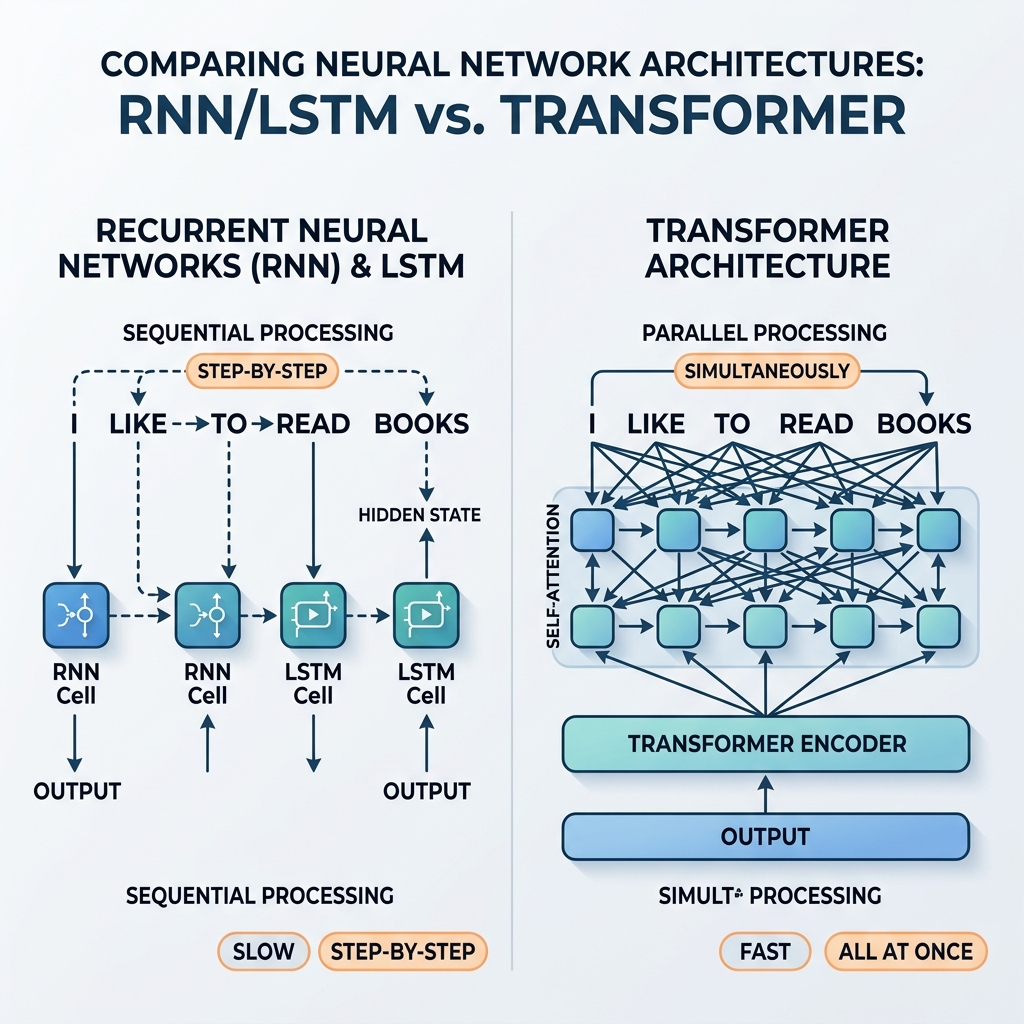
במשך שנים, רשתות עצביות חוזרות (RNN) ורשתות זיכרון לטווח ארוך וקצר (LSTM) היו האלופות הבלתי מעורערות של עיבוד נתונים סדרתי. הן הניעו מערכות תרגום מתקדמות, עוזרים קוליים ומודלים לייצור טקסט. עם זאת, בשנת 2017, המאמר המכונן “Attention Is All You Need” (Vaswani et al.) הציג את ארכיטקטורת הטרנספורמר. בתוך שנים ספורות, RNN ו-LSTM הוצאו כמעט לחלוטין ממודלי הבינה המלאכותית המרכזיים.
מדוע המעבר המהיר הזה קרה? מה הופך את הטרנספורמר למעולה מבחינה מבנית בהשוואה לרקורסיה? מאמר זה בוחן את צווארי הבקבוק המתמטיים והארכיטקטוניים של RNN/LSTM וכיצד הטרנספורמרים התגברו עליהם.
1. צוואר הבקבוק המרכזי: המגבלה הסדרתית
המאפיין המגדיר של RNN הוא מעבר המצב הרקורסיבי שלו. כדי לעבד רצף של קלטים, הרשת מעבדת כל טוקן צעד אחד בכל פעם, ומעדכנת את המצב הנסתר הפנימי שלה $h_t$ על בסיס הקלט הנוכחי $x_t$ והמצב הנסתר הקודם $h_{t-1}$.
יחס הרקורסיה המתמטי מיוצג כ:
$$h_t = \tanh(W_{hh} h_{t-1} + W_{xh} x_t + b)$$
בעיית המקביליות
מכיוון ש-$h_t$ תלוי ישירות ב-$h_{t-1}$, לא ניתן לבצע את העיבוד במקביל. כדי לחשב את המצב של המילה ה-100 במשפט, הרשת חייבת לחשב באופן סדרתי את 99 המצבים הראשונים.
ככל ש-GPUs ו-TPUs התפתחו כדי לתמוך בחישובי מטריצות מקביליים עצומים, התלות הסדרתית הזו הפכה לצוואר בקבוק קריטי. אימון מודלי RNN עמוקים על מאגרי נתונים עצומים באינטרנט נמשך שבועות, בעוד שהחומרה הייתה מסוגלת לרוץ מהר הרבה יותר אילו החישובים היו עצמאיים.
2. צוואר בקבוק המידע: גרדיאנטים נעלמים
ככל שאורך הרצף $N$ גדל, הפצת הגרדיאנט לאחור בזמן (BPTT) דורשת כפל מטריצות חוזר ונשנה עם משקל הרקורסיה $W_{hh}$. אם הערך העצמי הגדול ביותר של $W_{hh}$ קטן מ-1, הגרדיאנטים קטנים באופן מעריכי (גרדיאנטים נעלמים). אם הוא גדול מ-1, הם גדלים באופן מעריכי (גרדיאנטים מתפוצצים).
$$\frac{\partial E_t}{\partial h_1} = \frac{\partial E_t}{\partial h_t} \prod_{k=2}^{t} \frac{\partial h_k}{\partial h_{k-1}}$$
LSTMs ומגבלת הזיכרון
LSTMs הציגו את מצב התא (cell state) ומנגנוני שערים (שער שכחה, שער קלט, שער פלט) כדי לאפשר לגרדיאנטים לזרום בצורה ליניארית, ובכך להקל על בעיית הגרדיאנטים הנעלמים. עם זאת, אפילו LSTMs מתקשים עם רצפים ארוכים יותר מכמה מאות טוקנים. הווקטורים הנסתרים נאלצים לדחוס את ההיסטוריה של כל הטוקנים הקודמים לייצוג בגודל קבוע, מה שמוביל לאפקט של “שכחה”.
3. כיצד טרנספורמרים פתרו את בעיית הרקורסיה
הטרנספורמר זנח את הרקורסיה לחלוטין, והחליף אותה ב-מנגנון הקשב העצמי (Self-Attention). במקום הפצת מצב צעד אחר צעד, קשב עצמי מאפשר לכל טוקן לקיים אינטראקציה ישירה עם כל טוקן אחר ברצף בו-זמנית.
מטריצת הקשב מחושבת באמצעות:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{Q K^T}{\sqrt{d_k}}\right) V$$
כך הטרנספורמר פותר את צווארי הבקבוק של ה-RNN:
- מקביליות עצומה: מכיוון שאין תלות סדרתית בין המיקומים, כל הטוקנים ברצף הקלט מעובדים בו-זמנית. גרף החישוב הוא רדוד וניתן למקביליות גבוהה, מה שמנצל את ה-GPUs למקסימום היכולת.
- אורך נתיב קבוע: אורך הנתיב בין כל שני טוקנים הוא $\mathcal{O}(1)$. זה מונע את בעיית הגרדיאנט הנעלם על פני רצפים ארוכים, ומאפשר למודלים לטפל בקלות בקשרים של אלפי (או אפילו מיליוני) טוקנים.
- קידודים מיקומיים: מכיוון שאין סדר רציף מובנה בקשב עצמי, הטרנספורמר מחדיר קידודים מיקומיים (Positional Encodings) לתוך ייצוגי הקלט כדי לשמור על סדר המילים.
4. השוואת עיבוד רצף ב-PyTorch
קטע הקוד הבא מציג את ההבדל בין עיצוב הלולאה הסדרתית של תא RNN לחישוב המטריצה המקבילי של שכבת קשב עצמי:
import torch
import torch.nn as nn
import time
batch_size = 32
seq_len = 512
embedding_dim = 128
# קלטים: [batch_size, seq_len, embedding_dim]
x = torch.randn(batch_size, seq_len, embedding_dim)
# 1. עיבוד חוזר (תא RNN)
class CustomRNN(nn.Module):
def __init__(self, dim):
super().__init__()
self.rnn_cell = nn.RNNCell(dim, dim)
def forward(self, x):
h = torch.zeros(x.size(0), x.size(2), device=x.device)
# לולאה סדרתית על פני צעדי זמן (לא ניתן למקביל)
for t in range(x.size(1)):
h = self.rnn_cell(x[:, t, :], h)
return h
# 2. עיבוד מקבילי (שכבת קשב עצמי)
class CustomSelfAttention(nn.Module):
def __init__(self, dim):
super().__init__()
self.num_heads = 4
self.mha = nn.MultiheadAttention(dim, self.num_heads, batch_first=True)
def forward(self, x):
# כפל מטריצות מקבילי על פני כל צעדי הזמן
attn_out, _ = self.mha(x, x, x)
return attn_out
rnn = CustomRNN(embedding_dim)
attention = CustomSelfAttention(embedding_dim)
# מדידת לולאה סדרתית של RNN
start = time.time()
rnn_out = rnn(x)
rnn_time = time.time() - start
# מדידת ביצוע מקבילי של קשב עצמי
start = time.time()
attn_out = attention(x)
attn_time = time.time() - start
print(f"זמן RNN (לולאה סדרתית): {rnn_time * 1000:.2f} ms")
print(f"זמן קשב (מטריצה מקבילית): {attn_time * 1000:.2f} ms")
5. סיכום השוואה ארכיטקטונית
| מאפיין | RNN / LSTM | Transformer |
|---|---|---|
| פעולות סדרתיות | $\mathcal{O}(N)$ | $\mathcal{O}(1)$ |
| מורכבות חישובית לכל שכבה | $\mathcal{O}(N \cdot d^2)$ | $\mathcal{O}(N^2 \cdot d)$ |
| אורך נתיב מקסימלי | $\mathcal{O}(N)$ | $\mathcal{O}(1)$ |
| מקביליות | מוגבלת / בלתי אפשרית | מקביליות גבוהה |
| תלויות ארוכות טווח | גרועות (שוכח) | מצוינות (נתיב קבוע) |
סיכום
המעבר מ-RNN לטרנספורמרים הונע על ידי יעילות חישובית ויכולת נפח המודל. על ידי החלפת הרקורסיה הסדרתית בקשב עצמי מקבילי, הטרנספורמרים פתחו את היכולת להגדיל את גודל המודל ואת גודל מאגר הנתונים בצורה מעריכית. פריצת דרך מבנית זו סללה את הדרך למודלי שפה גדולים מודרניים (LLMs) כמו GPT ו-Claude, אשר אימונם היה בלתי אפשרי מבחינה חישובית באמצעות ארכיטקטורות חוזרות.