لماذا حلت المحولات (Transformers) محل شبكات RNN و LSTM
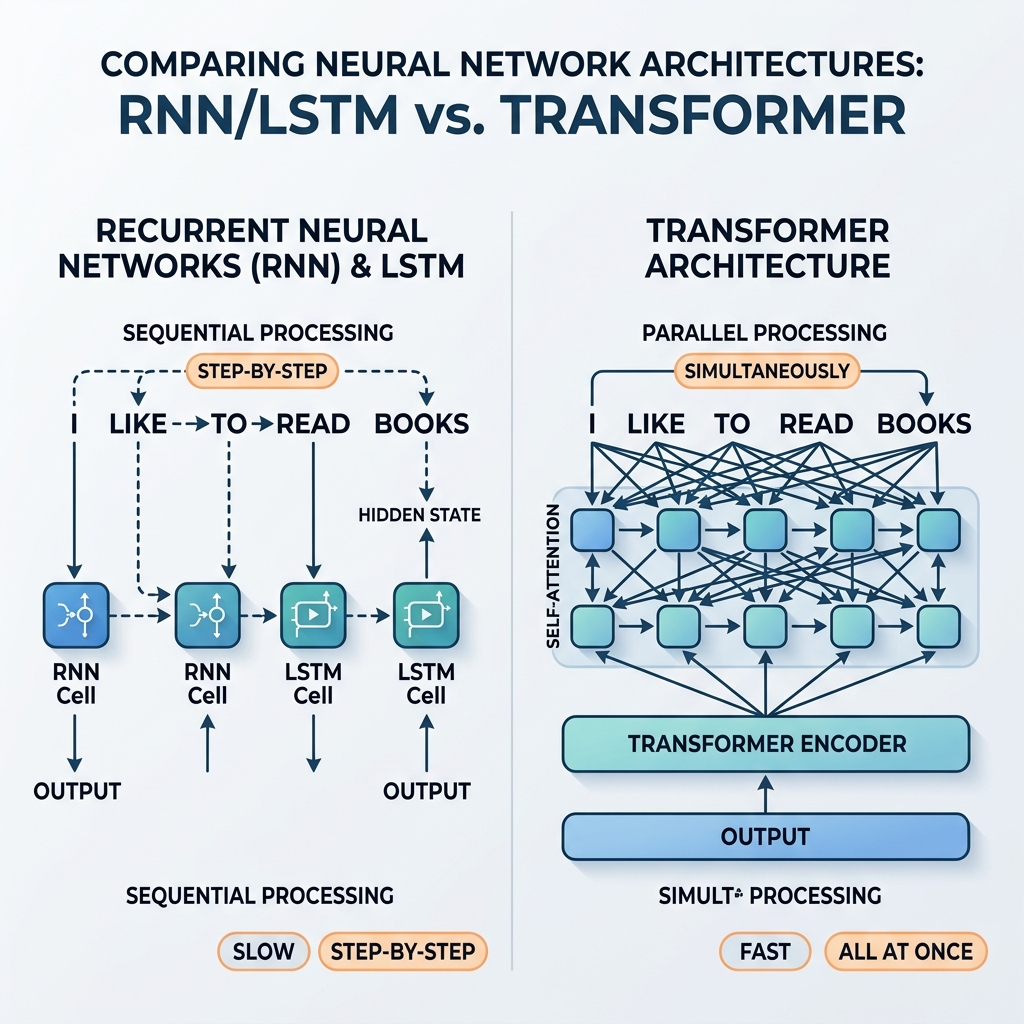
لسنوات عديدة، كانت الشبكات العصبية المتكررة (RNNs) وشبكات الذاكرة طويلة قصيرة المدى (LSTM) هي البطل بلا منازع في معالجة البيانات المتسلسلة. لقد قامت بتشغيل أنظمة الترجمة الحديثة، والمساعدين الصوتيين، ونماذج توليد النصوص. ومع ذلك، في عام 2017، قدمت الورقة البحثية التاريخية “Attention Is All You Need” (Vaswani et al.) بنية المحول (Transformer). وخلال سنوات قليلة، تم التخلص تدريجياً من شبكات RNN و LSTM تماماً من نماذج الذكاء الاصطناعي السائدة.
لماذا حدث هذا الانتقال السريع؟ ما الذي يجعل المحول متفوقاً هيكلياً على التكرار؟ تستكشف هذه المقالة الاختناقات الرياضية والهيكلية لشبكات RNN/LSTM وكيف تغلبت المحولات عليها.
1. الاختناق الرئيسي: عائق المعالجة المتسلسلة
السمة المحددة لشبكة RNN هي انتقال الحالة المتكرر. لمعالجة تسلسل من المدخلات، تعالج الشبكة كل توكن خطوة بخطوة، وتحدث حالتها المخفية الداخلية $h_t$ بناءً على الإدخال الحالي $x_t$ والحالة المخفية السابقة $h_{t-1}$.
يتم تمثيل علاقة التكرار الرياضية على النحو التالي:
$$h_t = \tanh(W_{hh} h_{t-1} + W_{xh} x_t + b)$$
مشكلة التوازي
نظراً لأن $h_t$ تعتمد مباشرة على $h_{t-1}$، فلا يمكن معالجة العمليات بالتوازي. لحساب حالة الكلمة رقم 100 في الجملة، يجب على الشبكة حساب أول 99 حالة بالتسلسل.
مع تطور وحدات معالجة الرسومات (GPUs) ووحدات معالجة الموتر (TPUs) لدعم عمليات حساب المصفوفات المتوازية الضخمة، أصبح هذا الاعتماد المتسلسل اختناقاً حرجاً. استغرق تدريب نماذج RNN العميقة على مجموعات البيانات الضخمة أسابيع، بينما كان العتاد قادراً على العمل بشكل أسرع بكثير إذا كانت الحسابات مستقلة.
2. اختناق المعلومات: تلاشيgradients
مع زيادة طول التسلسل $N$، يتطلب الانتشار العكسي للgradient عبر الزمن (BPTT) ضرباً متكرراً للمصفوفات مع وزن التكرار $W_{hh}$. إذا كانت القيمة الذاتية الأكبر لـ $W_{hh}$ أقل من 1، فإن الgradients تتقلص بشكل كبير (تلاشي الgradients). وإذا كانت أكبر من 1، فإنها تنمو بشكل كبير (انفجار الgradients).
$$\frac{\partial E_t}{\partial h_1} = \frac{\partial E_t}{\partial h_t} \prod_{k=2}^{t} \frac{\partial h_k}{\partial h_{k-1}}$$
شبكات LSTM وقيود الذاكرة
قدمت شبكات LSTM حالة الخلية وآليات البوابات (بوابة النسيان، بوابة الإدخال، بوابة الإخراج) للسماح للgradients بالتدفق خطياً، مما يخفف من تلاشي الgradients. ومع ذلك، حتى شبكات LSTM تعاني مع التسلسلات الأطول من بضع مئات من التوكنات. تضطر المتجهات المخفية إلى ضغط تاريخ جميع التوكنات السابقة في تمثيل ذي حجم ثابت، مما يؤدي إلى تأثير “النسيان”.
3. كيف حلت المحولات مشكلة التكرار
تخلت المحولات عن التكرار تماماً، واستبدلته بـ آلية الانتباه الذاتي (Self-Attention). بدلاً من انتشار الحالة خطوة بخطوة، يتيح الانتباه الذاتي لكل توكن التفاعل مباشرة مع كل توكن آخر في التسلسل في نفس الوقت.
يتم حساب مصفوفة الانتباه باستخدام:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{Q K^T}{\sqrt{d_k}}\right) V$$
إليك كيف يحل المحول اختناقات شبكة RNN:
- التوازي الضخم: نظراً لعدم وجود اعتمادات متسلسلة بين المواقع، يتم معالجة جميع التوكنات في تسلسل الإدخال في نفس الوقت. الرسم البياني الحسابي ضحل وقابل للتوازي بشكل كبير، مما يستغل وحدات معالجة الرسومات إلى أقصى سعة.
- طول مسار ثابت: طول المسار بين أي توكنين هو $\mathcal{O}(1)$. هذا يزيل مشكلة تلاشي الgradient على التسلسلات الطويلة، مما يمكن النماذج من التعامل بسهولة مع سياقات تتكون من آلاف (أو حتى ملايين) التوكنات.
- الترميز الموضعي: نظراً لعدم وجود ترتيب تسلسلي متأصل في الانتباه الذاتي، يقوم المحول بحقن ترميزات موضعية (Positional Encodings) في تضمينات الإدخال للحفاظ على ترتيب الكلمات.
4. مقارنة معالجة التسلسل باستخدام PyTorch
يوضح مقتطف الكود أدناه التباين بين تصميم الحلقة المتسلسلة لخلية RNN وحساب المصفوفة المتوازي لطبقة الانتباه الذاتي:
import torch
import torch.nn as nn
import time
batch_size = 32
seq_len = 512
embedding_dim = 128
# المدخلات: [batch_size, seq_len, embedding_dim]
x = torch.randn(batch_size, seq_len, embedding_dim)
# 1. المعالجة المتكررة (خلية RNN)
class CustomRNN(nn.Module):
def __init__(self, dim):
super().__init__()
self.rnn_cell = nn.RNNCell(dim, dim)
def forward(self, x):
h = torch.zeros(x.size(0), x.size(2), device=x.device)
# حلقة متسلسلة عبر الخطوات الزمنية (لا يمكن جعلها متوازية)
for t in range(x.size(1)):
h = self.rnn_cell(x[:, t, :], h)
return h
# 2. المعالجة المتوازية (طبقة الانتباه الذاتي)
class CustomSelfAttention(nn.Module):
def __init__(self, dim):
super().__init__()
self.num_heads = 4
self.mha = nn.MultiheadAttention(dim, self.num_heads, batch_first=True)
def forward(self, x):
# ضرب المصفوفات المتوازي عبر جميع الخطوات الزمنية
attn_out, _ = self.mha(x, x, x)
return attn_out
rnn = CustomRNN(embedding_dim)
attention = CustomSelfAttention(embedding_dim)
# اختبار حلقة RNN المتسلسلة
start = time.time()
rnn_out = rnn(x)
rnn_time = time.time() - start
# اختبار تنفيذ الانتباه الذاتي المتوازي
start = time.time()
attn_out = attention(x)
attn_time = time.time() - start
print(f"وقت RNN (الحلقة المتسلسلة): {rnn_time * 1000:.2f} ms")
print(f"وقت الانتباه (المصفوفة المتوازية): {attn_time * 1000:.2f} ms")
5. ملخص المقارنة الهيكلية
| الخاصية | RNN / LSTM | Transformer |
|---|---|---|
| العمليات المتسلسلة | $\mathcal{O}(N)$ | $\mathcal{O}(1)$ |
| التعقيد الحسابي لكل طبقة | $\mathcal{O}(N \cdot d^2)$ | $\mathcal{O}(N^2 \cdot d)$ |
| أقصى طول للمسار | $\mathcal{O}(N)$ | $\mathcal{O}(1)$ |
| التوازي | محدود / مستحيل | قابل للتوازي بشكل كبير |
| الاعتمادات طويلة المدى | ضعيفة (تنسى) | ممتازة (مسار ثابت) |
خاتمة
كان الدافع وراء الانتقال من شبكات RNN إلى المحولات هو الكفاءة الحسابية والقدرة الاستيعابية للنماذج. من خلال استبدال التكرار المتسلسل بالانتباه الذاتي المتوازي، فتحت المحولات القدرة على توسيع حجم النموذج وحجم مجموعة البيانات بشكل كبير. مهد هذا الاختراق الهيكلي الطريق لنماذج اللغة الكبيرة الحديثة (LLMs) مثل GPT و Claude، والتي كان من المستحيل حسابياً تدريبها باستخدام البنيات المتكررة.