Pourquoi les Transformers ont remplacé les RNN et les LSTM
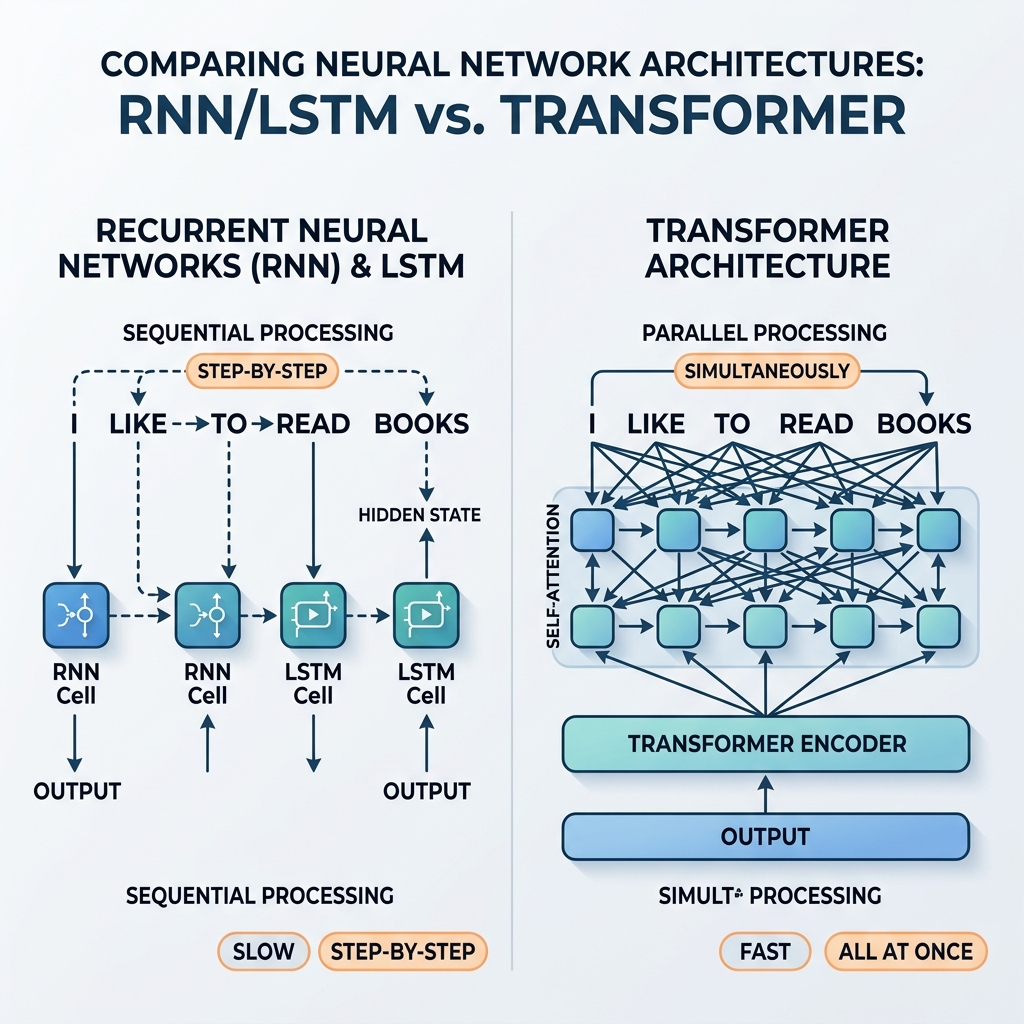
Pendant des années, les réseaux de neurones récurrents (RNN) et les réseaux LSTM (Long Short-Term Memory) ont été les champions incontestés du traitement des données séquentielles. Ils alimentaient des systèmes de traduction de pointe, des assistants vocaux et des modèles de génération de texte. Cependant, en 2017, l’article fondateur “Attention Is All You Need” (Vaswani et al.) a introduit l’architecture Transformer. En quelques années, les RNN et les LSTM ont été presque entièrement éliminés des modèles d’IA grand public.
Pourquoi cette transition rapide s’est-elle produite ? Qu’est-ce qui rend le Transformer si structurellement supérieur à la récurrence ? Cet article explore les verrous mathématiques et architecturaux des RNN/LSTM et comment les Transformers les ont surmontés.
1. Le verrou principal : le goulot d’étranglement séquentiel
La caractéristique essentielle d’un RNN est sa transition d’état récursive. Pour traiter une séquence d’entrées, le réseau traite chaque token un par un, mettant à jour son état caché interne $h_t$ en fonction de l’entrée actuelle $x_t$ et de l’état caché précédent $h_{t-1}$.
La relation de récurrence mathématique est représentée par :
$$h_t = \tanh(W_{hh} h_{t-1} + W_{xh} x_t + b)$$
Le problème de la parallélisation
Puisque $h_t$ dépend directement de $h_{t-1}$, le traitement ne peut pas être parallélisé. Pour calculer l’état du 100e mot d’une phrase, le réseau doit calculer séquentiellement les 99 premiers états.
Avec l’évolution des GPU et des TPU pour prendre en charge des calculs matriciels parallèles massifs, cette dépendance séquentielle est devenue un goulot d’étranglement critique. L’entraînement de modèles RNN profonds sur de grands ensembles de données Web prenait des semaines, alors que le matériel était capable de fonctionner beaucoup plus rapidement si les calculs étaient indépendants.
2. Le goulot d’étranglement de l’information : la disparition du gradient
À mesure que la longueur de la séquence $N$ augmente, la rétropropagation du gradient à travers le temps (BPTT) nécessite une multiplication matricielle répétée avec le poids de récurrence $W_{hh}$. Si la plus grande valeur propre de $W_{hh}$ est inférieure à 1, les gradients diminuent de manière exponentielle (phénomène de disparition du gradient). Si elle est supérieure à 1, ils augmentent de manière exponentielle (explosion du gradient).
$$\frac{\partial E_t}{\partial h_1} = \frac{\partial E_t}{\partial h_t} \prod_{k=2}^{t} \frac{\partial h_k}{\partial h_{k-1}}$$
Les LSTM et la contrainte de mémoire
Les LSTM ont introduit l’état de cellule et des mécanismes de portes (porte d’oubli, porte d’entrée, porte de sortie) pour permettre aux gradients de circuler linéairement, atténuant ainsi la disparition du gradient. Cependant, même les LSTM ont du mal avec des séquences de plus de quelques centaines de tokens. Les vecteurs cachés sont contraints de compresser l’historique de tous les tokens précédents dans une représentation de taille fixe, ce qui entraîne un effet d’« oubli ».
3. Comment les Transformers ont résolu le problème de la récurrence
Le Transformer a complètement abandonné la récurrence, la remplaçant par le mécanisme d’auto-attention (Self-Attention). Au lieu d’une propagation d’état étape par étape, l’auto-attention permet à chaque token d’interagir directement et simultanément avec tous les autres tokens de la séquence.
La matrice d’attention est calculée à l’aide de :
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{Q K^T}{\sqrt{d_k}}\right) V$$
Voici comment le Transformer résout les verrous des RNN :
- Parallélisation massive : Comme il n’y a pas de dépendances séquentielles entre les positions, tous les tokens de la séquence d’entrée sont traités en même temps. Le graphe de calcul est peu profond et hautement parallélisable, utilisant les GPU à leur capacité maximale.
- Longueur de chemin constante : La longueur du chemin entre deux tokens quelconques est de $\mathcal{O}(1)$. Cela élimine le problème de disparition du gradient sur les longues séquences, permettant aux modèles de gérer facilement des contextes de milliers (voire de millions) de tokens.
- Encodages positionnels : Comme il n’y a pas d’ordre séquentiel inhérent dans l’auto-attention, le Transformer injecte des encodages positionnels dans les embeddings d’entrée pour préserver l’ordre des mots.
4. Comparaison du traitement de séquences en PyTorch
Le fragment de code ci-dessous oppose la conception de boucle séquentielle d’une cellule RNN au calcul matriciel parallèle d’une couche d’auto-attention :
import torch
import torch.nn as nn
import time
batch_size = 32
seq_len = 512
embedding_dim = 128
# Entrées : [batch_size, seq_len, embedding_dim]
x = torch.randn(batch_size, seq_len, embedding_dim)
# 1. Traitement récurrent (Cellule RNN)
class CustomRNN(nn.Module):
def __init__(self, dim):
super().__init__()
self.rnn_cell = nn.RNNCell(dim, dim)
def forward(self, x):
h = torch.zeros(x.size(0), x.size(2), device=x.device)
# Boucle séquentielle sur les pas de temps (ne peut pas être parallélisée)
for t in range(x.size(1)):
h = self.rnn_cell(x[:, t, :], h)
return h
# 2. Traitement parallèle (Couche d'auto-attention)
class CustomSelfAttention(nn.Module):
def __init__(self, dim):
super().__init__()
self.num_heads = 4
self.mha = nn.MultiheadAttention(dim, self.num_heads, batch_first=True)
def forward(self, x):
# Multiplication matricielle parallèle sur tous les pas de temps
attn_out, _ = self.mha(x, x, x)
return attn_out
rnn = CustomRNN(embedding_dim)
attention = CustomSelfAttention(embedding_dim)
# Évaluation boucle séquentielle RNN
start = time.time()
rnn_out = rnn(x)
rnn_time = time.time() - start
# Évaluation exécution parallèle auto-attention
start = time.time()
attn_out = attention(x)
attn_time = time.time() - start
print(f"Temps RNN (Boucle séquentielle) : {rnn_time * 1000:.2f} ms")
print(f"Temps Attention (Matrice parallèle) : {attn_time * 1000:.2f} ms")
5. Résumé de la comparaison architecturale
| Caractéristique | RNN / LSTM | Transformer |
|---|---|---|
| Opérations séquentielles | $\mathcal{O}(N)$ | $\mathcal{O}(1)$ |
| Complexité de calcul par couche | $\mathcal{O}(N \cdot d^2)$ | $\mathcal{O}(N^2 \cdot d)$ |
| Longueur de chemin maximale | $\mathcal{O}(N)$ | $\mathcal{O}(1)$ |
| Parallélisation | Limitée / Impossible | Hautement parallélisable |
| Dépendances à longue portée | Faibles (Oubli) | Excellentes (Chemin constant) |
Conclusion
Le passage des RNN aux Transformers a été motivé par l’efficacité informatique et la capacité. En remplaçant la récurrence séquentielle par une auto-attention parallèle, les Transformers ont permis d’augmenter de manière exponentielle la taille du modèle et celle de l’ensemble de données. Cette percée structurelle a ouvert la voie aux grands modèles de langage (LLM) modernes comme GPT et Claude, dont l’entraînement aurait été impossible à réaliser à l’aide d’architectures récurrentes.