چرا ترنسفورمرها جایگزین شبکههای RNN و LSTM شدند
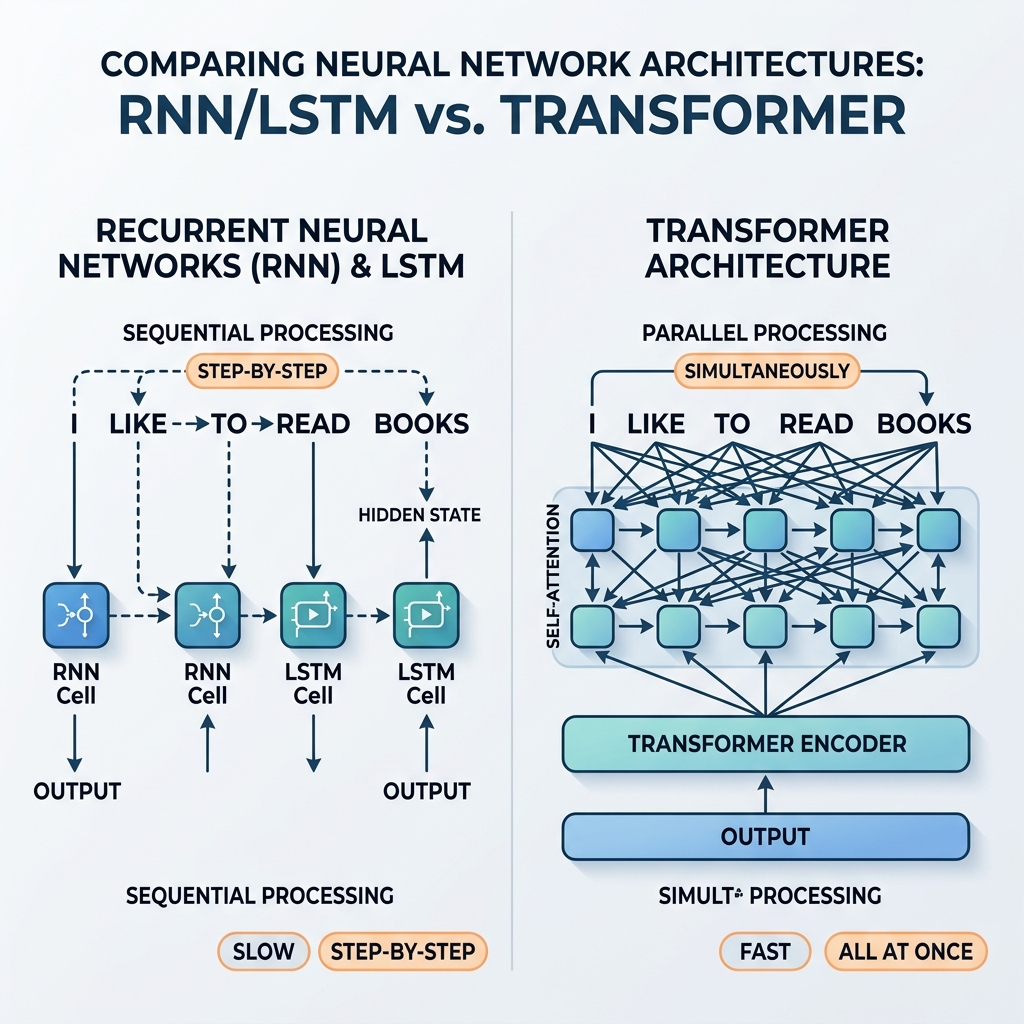
برای سالها، شبکههای عصبی بازگشتی (RNNs) و شبکههای حافظه طولانی کوتاهمدت (LSTM) قهرمانان بلامنازع پردازش دادههای متوالی بودند. آنها سیستمهای ترجمه پیشرفته، دستیارهای صوتی و مدلهای تولید متن را قدرت میبخشیدند. با این حال، در سال ۲۰۱۷، مقاله برجسته “Attention Is All You Need” (Vaswani et al.) معماری ترنسفورمر را معرفی کرد. در عرض چند سال، RNNها و LSTMها تقریباً به طور کامل از مدلهای اصلی هوش مصنوعی کنار گذاشته شدند.
چرا این انتقال سریع اتفاق افتاد؟ چه چیزی ترنسفورمر را از نظر ساختاری نسبت به بازگشتپذیری (recurrence) تا این حد برتر میکند؟ این مقاله تنگناهای ریاضی و معماری RNNها/LSTMها و نحوه غلبه ترنسفورمرها بر آنها را بررسی میکند.
۱. تنگنه اصلی: محدودیت متوالی
ویژگی تعیینکننده یک RNN، انتقال حالت بازگشتی آن است. برای پردازش یک توالی از ورودیها، شبکه هر توکن را در یک زمان پردازش میکند و حالت پنهان داخلی خود $h_t$ را بر اساس ورودی فعلی $x_t$ و حالت پنهان قبلی $h_{t-1}$ بهروزرسانی میکند.
رابطه بازگشتی ریاضی به صورت زیر نشان داده میشود:
$$h_t = \tanh(W_{hh} h_{t-1} + W_{xh} x_t + b)$$
مشکل موازیسازی
از آنجا که $h_t$ به طور مستقیم به $h_{t-1}$ وابسته است، پردازش نمیتواند موازی شود. برای محاسبه حالت صدمین کلمه در یک جمله، شبکه باید به طور متوالی ۹۹ حالت اول را محاسبه کند.
با تکامل GPUها و TPUها برای پشتیبانی از محاسبات ماتریسی موازی عظیم، این وابستگی متوالی به یک تنگنای بحرانی تبدیل شد. آموزش مدلهای عمیق RNN روی مجموعهدادگان بزرگ وب هفتهها طول میکشید، در حالی که سختافزار در صورت مستقل بودن محاسبات قادر بود بسیار سریعتر کار کند.
۲. تنگنه اطلاعات: گرادیانهای محوشونده
با افزایش طول توالی $N$، پسانتشار گرادیان در زمان (BPTT) نیاز به ضرب ماتریسی مکرر با وزن بازگشتی $W_{hh}$ دارد. اگر بزرگترین مقدار ویژه $W_{hh}$ کمتر از ۱ باشد، گرادیانها به طور نمایی کوچک میشوند (گرادیانهای محوشونده). اگر بزرگتر از ۱ باشد، به طور نمایی رشد میکنند (گرادیانهای انفجاری).
$$\frac{\partial E_t}{\partial h_1} = \frac{\partial E_t}{\partial h_t} \prod_{k=2}^{t} \frac{\partial h_k}{\partial h_{k-1}}$$
شبکههای LSTM و محدودیت حافظه
شبکههای LSTM حالت سلول (cell state) و مکانیزمهای دروازهبانی (دروازه فراموشی، دروازه ورودی، دروازه خروجی) را برای اجازه دادن به جریان خطی گرادیانها و کاهش گرادیانهای محوشونده معرفی کردند. با این حال، حتی LSTMها با توالیهای طولانیتر از چند صد توکن دست و پنجه نرم میکنند. بردارهای پنهان مجبورند تاریخچه تمام توکنهای قبلی را در یک نمایش با اندازه ثابت فشرده کنند که منجر به اثر “فراموشی” میشود.
۳. چگونه ترنسفورمرها مشکل بازگشتپذیری را حل کردند
ترنسفورمر بازگشتپذیری را به طور کامل کنار گذاشت و آن را با مکانیزم توجه به خود (Self-Attention) جایگزین کرد. به جای انتشار حالت گام به گام، توجه به خود به هر توکن اجازه میدهد تا به طور همزمان و مستقیم با هر توکن دیگری در توالی تعامل داشته باشد.
ماتریس توجه با استفاده از فرمول زیر محاسبه میشود:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{Q K^T}{\sqrt{d_k}}\right) V$$
در اینجا نحوه حل تنگناهای RNN توسط ترنسفورمر آمده است:
- موازیسازی عظیم: از آنجا که هیچ وابستگی متوالی بین موقعیتها وجود ندارد، تمام توکنها در توالی ورودی در یک زمان پردازش میشوند. نمودار محاسباتی کمعمق و بسیار موازی است و از حداکثر ظرفیت GPUها استفاده میکند.
- طول مسیر ثابت: طول مسیر بین هر دو توکن $\mathcal{O}(1)$ است. این امر مشکل گرادیان محوشونده را در توالیهای طولانی از بین میبرد و مدلها را قادر میسازد تا به راحتی بافتارهای هزاران (یا حتی میلیونها) توکن را مدیریت کنند.
- رمزگذاریهای موقعیتی: از آنجا که هیچ ترتیب متوالی ذاتی در توجه به خود وجود ندارد، ترنسفورمر رمزگذاریهای موقعیتی (Positional Encodings) را به جاسازیهای ورودی تزریق میکند تا ترتیب کلمات حفظ شود.
۴. مقایسه پردازش توالی در PyTorch
قطعه کد زیر طراحی حلقه متوالی یک سلول RNN را با محاسبه ماتریس موازی یک لایه توجه به خود مقایسه میکند:
import torch
import torch.nn as nn
import time
batch_size = 32
seq_len = 512
embedding_dim = 128
# ورودیها: [batch_size, seq_len, embedding_dim]
x = torch.randn(batch_size, seq_len, embedding_dim)
# ۱. پردازش بازگشتی (سلول RNN)
class CustomRNN(nn.Module):
def __init__(self, dim):
super().__init__()
self.rnn_cell = nn.RNNCell(dim, dim)
def forward(self, x):
h = torch.zeros(x.size(0), x.size(2), device=x.device)
# حلقه متوالی روی گامهای زمانی (نمیتواند موازی شود)
for t in range(x.size(1)):
h = self.rnn_cell(x[:, t, :], h)
return h
# ۲. پردازش موازی (لایه توجه به خود)
class CustomSelfAttention(nn.Module):
def __init__(self, dim):
super().__init__()
self.num_heads = 4
self.mha = nn.MultiheadAttention(dim, self.num_heads, batch_first=True)
def forward(self, x):
# ضرب ماتریس موازی در تمام گامهای زمانی
attn_out, _ = self.mha(x, x, x)
return attn_out
rnn = CustomRNN(embedding_dim)
attention = CustomSelfAttention(embedding_dim)
# بنچمارک حلقه متوالی RNN
start = time.time()
rnn_out = rnn(x)
rnn_time = time.time() - start
# بنچمارک اجرای موازی توجه به خود
start = time.time()
attn_out = attention(x)
attn_time = time.time() - start
print(f"زمان RNN (حلقه متوالی): {rnn_time * 1000:.2f} ms")
print(f"زمان توجه (ماتریس موازی): {attn_time * 1000:.2f} ms")
۵. خلاصه مقایسه معماری
| ویژگی | RNN / LSTM | Transformer |
|---|---|---|
| عملیات متوالی | $\mathcal{O}(N)$ | $\mathcal{O}(1)$ |
| پیچیدگی محاسباتی در هر لایه | $\mathcal{O}(N \cdot d^2)$ | $\mathcal{O}(N^2 \cdot d)$ |
| حداکثر طول مسیر | $\mathcal{O}(N)$ | $\mathcal{O}(1)$ |
| موازیسازی | محدود / غیرممکن | بسیار موازیپذیر |
| وابستگیهای طولانیمدت | ضعیف (فراموش میکند) | عالی (مسیر ثابت) |
نتیجهگیری
تغییر از RNNها به ترنسفورمرها به دلیل کارایی محاسباتی و ظرفیت مدل بود. ترنسفورمرها با جایگزین کردن بازگشت متوالی با توجه به خود موازی، توانایی مقیاسپذیری اندازه مدل و اندازه مجموعهداده را به طور نمایی باز کردند. این پیشرفت ساختاری راه را برای مدلهای زبانی بزرگ مدرن (LLM) مانند GPT و Claude هموار کرد که آموزش آنها با استفاده از معماریهای بازگشتی از نظر محاسباتی غیرممکن بود.