트랜스포머가 RNN과 LSTM을 대체한 이유
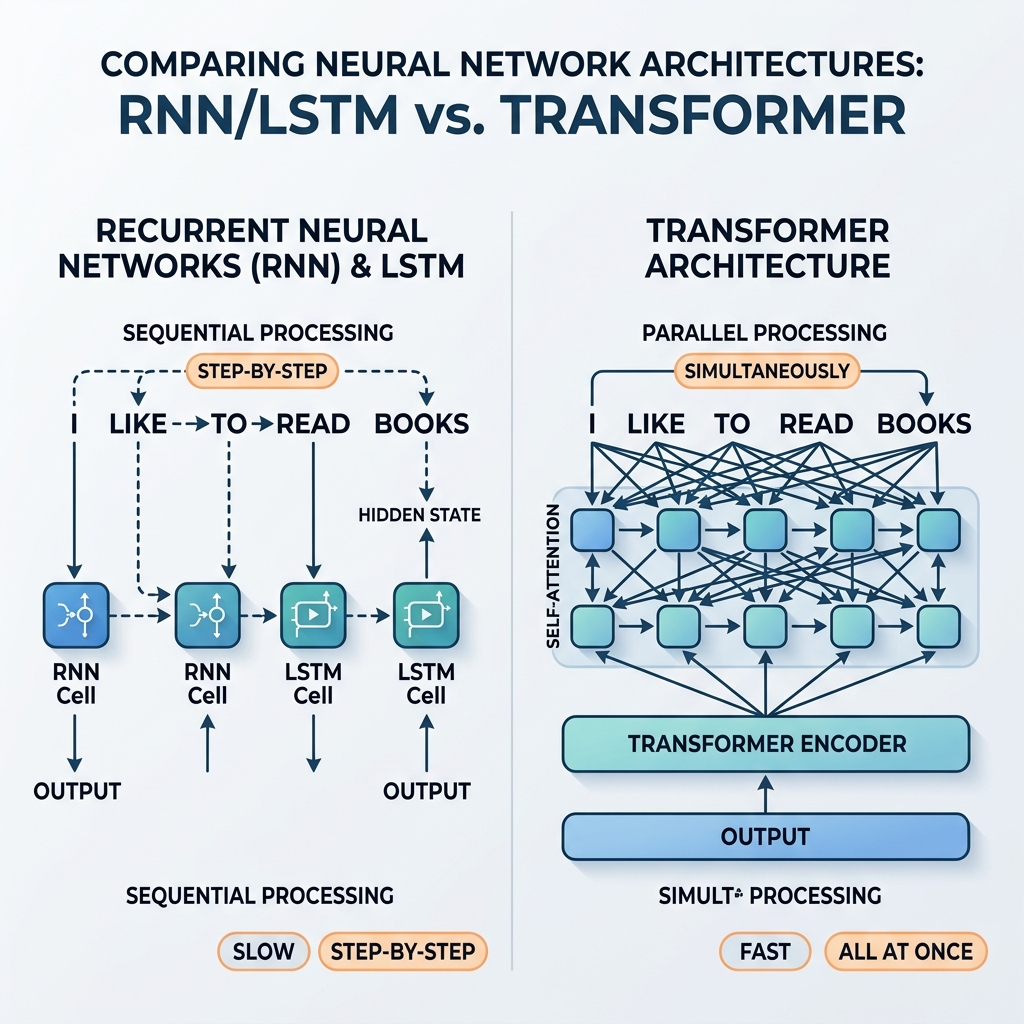
오랫동안 순환 신경망(RNN)과 장단기 메모리(LSTM) 네트워크는 순차 데이터 처리 분야에서 독보적인 챔피언이었습니다. 이들은 최첨단 번역 시스템, 음성 비서, 텍스트 생성 모델의 기반이 되었습니다. 그러나 2017년, 기념비적인 논문인 “Attention Is All You Need” (Vaswani et al.)가 트랜스포머 아키텍처를 도입했습니다. 그리고 불과 몇 년 만에 RNN과 LSTM은 인공지능 주류 모델에서 거의 완벽히 사라지게 되었습니다.
왜 이토록 빠른 전환이 발생했을까요? 순환구조와 비교할 때 트랜스포머가 아키텍처적으로 우월한 이유는 무엇일까요? 이 글에서는 RNN/LSTM의 수학적, 구조적 한계를 분석하고 트랜스포머가 이를 어떻게 극복했는지 살펴보겠습니다.
1. 핵심 병목 현상: 순차적 한계 (Sequential Bottleneck)
RNN을 정의하는 핵심 특징은 재귀적 상태 전환입니다. 순차 입력을 처리하기 위해 네트워크는 각 토큰을 한 번에 하나씩 처리하며, 현재 입력 $x_t$와 이전 은닉 상태 $h_{t-1}$을 기반으로 내부 은닉 상태 $h_t$를 업데이트합니다.
수학적인 재귀 관계식은 다음과 같습니다.
$$h_t = \tanh(W_{hh} h_{t-1} + W_{xh} x_t + b)$$
병렬화의 불가능
$h_t$는 $h_{t-1}$에 직접적으로 의존하기 때문에 처리를 병렬화할 수 없습니다. 한 문장에서 100번째 단어의 상태를 계산하려면 네트워크는 먼저 99개의 상태를 순차적으로 계산해야만 합니다.
GPU와 TPU가 대규모 병렬 행렬 연산을 지원하도록 진화하면서 이 순차적 의존성은 치명적인 병목 현상이 되었습니다. 대규모 웹 데이터셋에서 깊은 RNN 모델을 학습시키는 데 수주가 걸린 반면, 계산이 독립적이었다면 하드웨어가 훨씬 더 빠르게 작동할 수 있었습니다.
2. 정보 전달 병목: 그래디언트 소실 (Vanishing Gradients)
시퀀스 길이 $N$이 늘어남에 따라 역전파(BPTT) 과정에서 순환 가중치 $W_{hh}$와의 반복적인 행렬 곱이 필요합니다. 만약 $W_{hh}$의 최대 고윳값이 1보다 작으면 그래디언트는 기하급수적으로 감소하고(소실), 1보다 크면 기하급수적으로 증가합니다(폭발).
$$\frac{\partial E_t}{\partial h_1} = \frac{\partial E_t}{\partial h_t} \prod_{k=2}^{t} \frac{\partial h_k}{\partial h_{k-1}}$$
LSTM과 메모리 압축의 한계
LSTM은 **셀 상태(cell state)**와 게이트 메커니즘(망각 게이트, 입력 게이트, 출력 게이트)을 도입하여 그래디언트가 선형적으로 흐르게 함으로써 소실 문제를 완화했습니다. 하지만 LSTM 역시 수백 토큰 이상의 긴 시퀀스에서는 어려움을 겪습니다. 은닉 벡터가 고정된 크기 안에 모든 이전 토큰들의 정보를 압축해서 담아야 하므로 결국 정보를 “망각"하게 됩니다.
3. 트랜스포머가 순환 문제를 해결한 방법
트랜스포머는 순환(recurrence) 구조를 완전히 버리고 이를 셀프 어텐션(Self-Attention) 메커니즘으로 대체했습니다. 단계별 상태 전달 대신, 셀프 어텐션은 시퀀스 내의 모든 토큰이 동시에 서로 직접 상호작용하도록 만듭니다.
어텐션 행렬은 다음 식을 통해 계산됩니다.
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{Q K^T}{\sqrt{d_k}}\right) V$$
트랜스포머가 RNN의 병목 현상들을 해결한 방법은 다음과 같습니다.
- 대규모 병렬 처리: 위치 간의 순차적 의존성이 없기 때문에 입력 시퀀스의 모든 토큰이 한 번에 동시에 처리됩니다. 연산 그래프가 얕고 고도로 병렬화 가능하여 GPU 성능을 한계까지 사용할 수 있습니다.
- 상수 경로 길이: 임의의 두 토큰 사이의 정보 전달 경로 길이는 단 $\mathcal{O}(1)$입니다. 이는 긴 시퀀스에서의 그래디언트 소실 문제를 해결하며, 모델이 수천에서 수백만 토큰 범위의 컨텍스트를 쉽게 다룰 수 있게 해줍니다.
- 위치 인코딩: 셀프 어텐션 자체에는 시퀀스 순서에 대한 개념이 없기 때문에, 트랜스포머는 단어의 순서를 보존하기 위해 입력 임베딩에 **위치 인코딩(Positional Encodings)**을 더해줍니다.
4. PyTorch 시퀀스 처리 시간 비교
아래의 코드 스니펫은 RNN 셀의 순차적 루프 디자인과 셀프 어텐션 레이어의 병렬 행렬 연산 연산 속도를 비교하여 보여줍니다.
import torch
import torch.nn as nn
import time
batch_size = 32
seq_len = 512
embedding_dim = 128
# 입력 형태: [batch_size, seq_len, embedding_dim]
x = torch.randn(batch_size, seq_len, embedding_dim)
# 1. 순환 처리 (RNN 셀)
class CustomRNN(nn.Module):
def __init__(self, dim):
super().__init__()
self.rnn_cell = nn.RNNCell(dim, dim)
def forward(self, x):
h = torch.zeros(x.size(0), x.size(2), device=x.device)
# 시간 단계를 따르는 순차 루프 (병렬 연산 불가)
for t in range(x.size(1)):
h = self.rnn_cell(x[:, t, :], h)
return h
# 2. 병렬 처리 (셀프 어텐션 레이어)
class CustomSelfAttention(nn.Module):
def __init__(self, dim):
super().__init__()
self.num_heads = 4
self.mha = nn.MultiheadAttention(dim, self.num_heads, batch_first=True)
def forward(self, x):
# 모든 타임스텝에 걸쳐 병렬 행렬 곱 실행
attn_out, _ = self.mha(x, x, x)
return attn_out
rnn = CustomRNN(embedding_dim)
attention = CustomSelfAttention(embedding_dim)
# RNN 순차 루프 성능 평가
start = time.time()
rnn_out = rnn(x)
rnn_time = time.time() - start
# 셀프 어텐션 병렬 연산 성능 평가
start = time.time()
attn_out = attention(x)
attn_time = time.time() - start
print(f"RNN 연산 시간 (순차 루프): {rnn_time * 1000:.2f} ms")
print(f"어텐션 연산 시간 (병렬 행렬): {attn_time * 1000:.2f} ms")
5. 아키텍처 비교 요약
| 특징 | RNN / LSTM | Transformer |
|---|---|---|
| 순차 연산 단계 | $\mathcal{O}(N)$ | $\mathcal{O}(1)$ |
| 레이어당 연산 복잡도 | $\mathcal{O}(N \cdot d^2)$ | $\mathcal{O}(N^2 \cdot d)$ |
| 최대 경로 길이 | $\mathcal{O}(N)$ | $\mathcal{O}(1)$ |
| 병렬화 | 제한됨 / 불가능 | 매우 탁월함 |
| 장기 의존성 유지 | 저조함 (망각 현상) | 우수함 (상수 경로) |
결론
RNN에서 트랜스포머로의 전환은 하드웨어 연산 효율과 용량의 한계 때문에 가속화되었습니다. 순차 재귀 루프를 병렬 셀프 어텐션 구조로 변경함으로써 트랜스포머는 모델 크기와 학습 데이터셋의 규모를 기하급수적으로 확장했습니다. 이 아키텍처적 도약은 과거 순환 모델로는 학습이 불가능했던 GPT나 Claude 같은 현대 대규모 언어 모델(LLM)의 탄생을 가져왔습니다.