ٹرانسفارمرز نے RNN اور LSTM کی جگہ کیوں لی
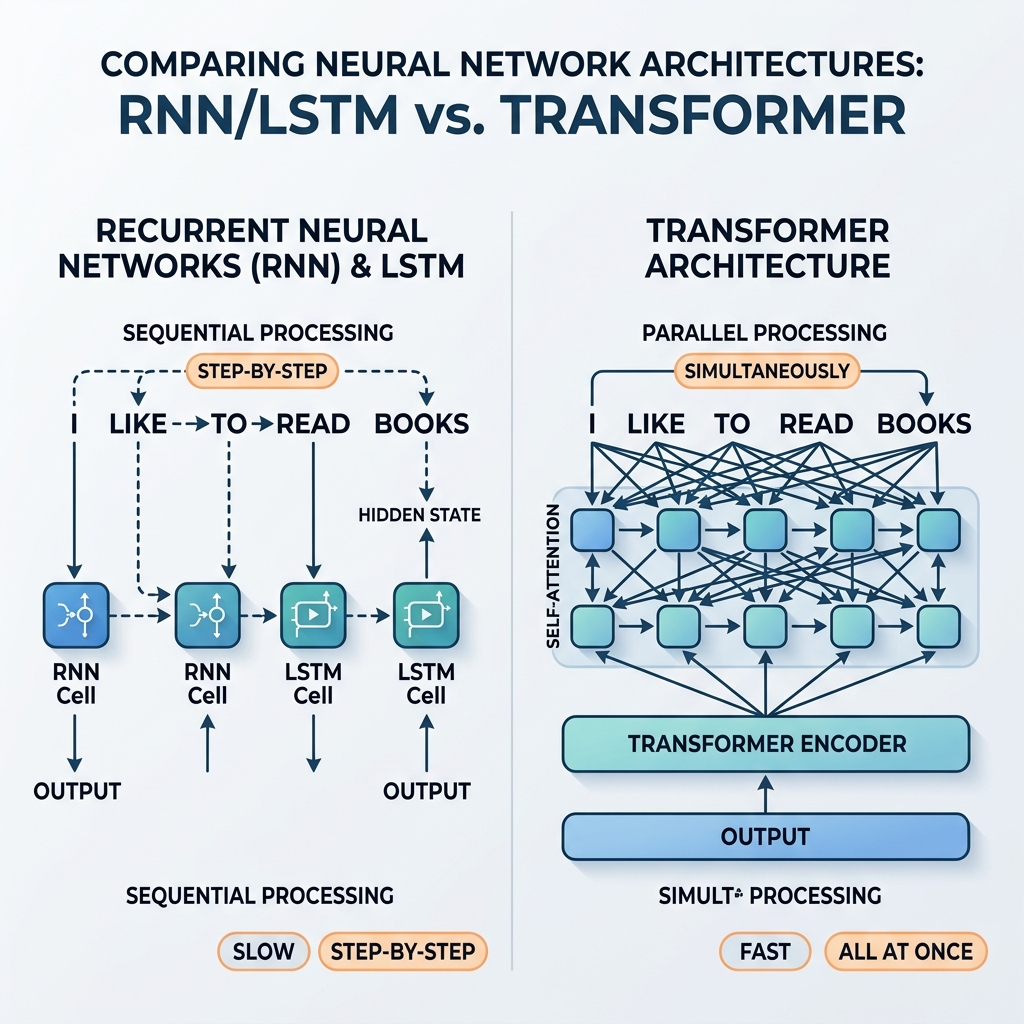
برسوں تک، ریکرنٹ نیورل نیٹ ورکس (RNNs) اور لانگ شارٹ ٹرم میموری (LSTM) نیٹ ورکس ترتیب وار ڈیٹا پروسیسنگ کے بے تاج بادشاہ تھے۔ انہوں نے جدید ترین ترجمہ کے نظام، صوتی معاونین، اور ٹیکسٹ جنریشن ماڈلز کو طاقت دی۔ تاہم، 2017 میں، تاریخی مقالے “Attention Is All You Need” (Vaswani et al.) نے ٹرانسفارمر فن تعمیر کو متعارف کرایا۔ چند ہی سالوں میں، RNNs اور LSTMs کو مرکزی دھارے کے AI ماڈلز سے تقریباً مکمل طور پر باہر کر دیا گیا۔
یہ تیز رفتار تبدیلی کیوں ہوئی؟ ٹرانسفارمر کو ساختی طور پر تکرار (recurrence) سے اتنا بہتر کیا بناتا ہے؟ یہ مضمون RNNs/LSTMs کی ریاضیاتی اور ساختی رکاوٹوں اور ٹرانسفارمرز نے ان پر کیسے قابو پایا اس کا جائزہ لیتا ہے۔
1. بنیادی رکاوٹ: ترتیب وار پروسیسنگ کی حد
RNN کی وضاحتی خصوصیت اس کی تکراری حالت کی منتقلی ہے۔ ان پٹ کی ترتیب کو پروسیس کرنے کے لیے، نیٹ ورک ہر ٹوکن کو ایک وقت میں ایک قدم پروسیس کرتا ہے، اپنے اندرونی پوشیدہ حالت $h_t$ کو موجودہ ان پٹ $x_t$ اور پچھلی پوشیدہ حالت $h_{t-1}$ کی بنیاد پر اپ ڈیٹ کرتا ہے۔
ریاضیاتی تکرار کا تعلق اس طرح ظاہر کیا جاتا ہے:
$$h_t = \tanh(W_{hh} h_{t-1} + W_{xh} x_t + b)$$
متوازی پروسیسنگ کا مسئلہ
چونکہ $h_t$ براہ راست $h_{t-1}$ پر منحصر ہے، اس لیے پروسیسنگ کو متوازی (parallel) نہیں کیا جا سکتا۔ ایک جملے میں 100ویں لفظ کی حالت کا حساب لگانے کے لیے، نیٹ ورک کو ترتیب وار پہلے 99 حالتوں کا حساب لگانا ہوگا۔
جیسے جیسے GPUs اور TPUs بڑے پیمانے پر متوازی میٹرکس حسابات کی حمایت کے لیے تیار ہوئے، یہ ترتیب وار انحصار ایک سنگین رکاوٹ بن گیا۔ بڑے پیمانے پر ڈیٹا سیٹس پر گہرے RNN ماڈلز کی تربیت میں ہفتوں لگ جاتے تھے، جبکہ اگر حسابات آزاد ہوتے تو ہارڈ ویئر بہت تیزی سے چلنے کے قابل تھا۔
2. معلومات کی رکاوٹ: گرتے ہوئے گریڈینٹ (Vanishing Gradients)
جیسے جیسے ترتیب کی لمبائی $N$ بڑھتی ہے، وقت کے ساتھ پیچھے کی طرف جانے والے گریڈینٹ (BPTT) کے لیے تکرار کے وزن $W_{hh}$ کے ساتھ بار بار میٹرکس ضرب کی ضرورت ہوتی ہے۔ اگر $W_{hh}$ کا سب سے بڑا آئیجن ویلیو 1 سے کم ہے، تو گریڈینٹ تیزی سے سکڑتے ہیں (vanishing gradients)۔ اگر یہ 1 سے زیادہ ہے، تو وہ تیزی سے بڑھتے ہیں (exploding gradients)۔
$$\frac{\partial E_t}{\partial h_1} = \frac{\partial E_t}{\partial h_t} \prod_{k=2}^{t} \frac{\partial h_k}{\partial h_{k-1}}$$
LSTMs اور میموری کی حد
LSTMs نے گریڈینٹ کو لکیری طور پر بہنے کی اجازت دینے کے لیے سیل حالت اور گیٹنگ میکانزم (forget gate, input gate, output gate) متعارف کرایا، جس سے ختم ہوتے گریڈینٹ کو کم کیا گیا۔ تاہم، LSTMs بھی چند سو ٹوکنز سے طویل ترتیب کے ساتھ جدوجہد کرتے ہیں۔ پوشیدہ ویکٹر پچھلے تمام ٹوکنز کی تاریخ کو ایک مقررہ سائز کی نمائندگی میں سکیڑنے پر مجبور ہوتے ہیں، جس سے “بھولنے” کا اثر پیدا ہوتا ہے۔
3. ٹرانسفارمرز نے تکرار کے مسئلے کو کیسے حل کیا
ٹرانسفارمر نے تکرار کو مکمل طور پر ترک کر دیا، اسے Self-Attention (خود توجہ) میکانزم سے بدل دیا۔ قدم بہ قدم حالت کے پھیلاؤ کے بجائے، خود توجہ ترتیب میں ہر ٹوکن کو ایک ہی وقت میں براہ راست ہر دوسرے ٹوکن کے ساتھ بات چیت کرنے کی اجازت دیتی ہے۔
اٹینشن میٹرکس کا حساب درج ذیل کا استعمال کرتے ہوئے کیا جاتا ہے:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{Q K^T}{\sqrt{d_k}}\right) V$$
ٹرانسفارمر RNN کی رکاوٹوں کو کیسے حل کرتا ہے:
- بڑے پیمانے پر متوازی پروسیسنگ: چونکہ پوزیشنوں کے درمیان کوئی ترتیب وار انحصار نہیں ہوتا ہے، اس لیے ان پٹ ترتیب کے تمام ٹوکنز ایک ہی وقت میں پروسیس ہوتے ہیں۔ کمپیوٹیشنل گراف اتھلا اور انتہائی متوازی ہے، جو GPUs کا زیادہ سے زیادہ صلاحیت تک استعمال کرتا ہے۔
- مستقل راستے کی لمبائی: کسی بھی دو ٹوکنز کے درمیان راستے کی لمبائی $\mathcal{O}(1)$ ہے۔ یہ طویل ترتیبوں پر ختم ہوتے گریڈینٹ کے مسئلے کو ختم کرتا ہے، جس سے ماڈل آسانی سے ہزاروں (یا لاکھوں) ٹوکنز کے سیاق و سباق کو سنبھال سکتے ہیں۔
- پوزیشنی انکوڈنگز: چونکہ خود توجہ میں کوئی اندرونی ترتیب نہیں ہوتی ہے، اس لیے ٹرانسفارمر الفاظ کی ترتیب کو برقرار رکھنے کے لیے ان پٹ ایمبیڈنگز میں پوزیشنی انکوڈنگز داخل کرتا ہے۔
4. PyTorch ترتیب وار پروسیسنگ کا موازنہ
نیچے دیا گیا کوڈ اسنیپٹ ایک RNN سیل کے ترتیب وار لوپ ڈیزائن کا سیلف اٹینشن لیئر کے متوازی میٹرکس حساب سے موازنہ کرتا ہے:
import torch
import torch.nn as nn
import time
batch_size = 32
seq_len = 512
embedding_dim = 128
# ان پٹ: [batch_size, seq_len, embedding_dim]
x = torch.randn(batch_size, seq_len, embedding_dim)
# 1. تکراری پروسیسنگ (RNN سیل)
class CustomRNN(nn.Module):
def __init__(self, dim):
super().__init__()
self.rnn_cell = nn.RNNCell(dim, dim)
def forward(self, x):
h = torch.zeros(x.size(0), x.size(2), device=x.device)
# وقت کے قدموں پر ترتیب وار لوپ (متوازی نہیں کیا جا سکتا)
for t in range(x.size(1)):
h = self.rnn_cell(x[:, t, :], h)
return h
# 2. متوازی پروسیسنگ (خود توجہ کی تہہ)
class CustomSelfAttention(nn.Module):
def __init__(self, dim):
super().__init__()
self.num_heads = 4
self.mha = nn.MultiheadAttention(dim, self.num_heads, batch_first=True)
def forward(self, x):
# تمام ٹائم اسٹپس پر متوازی میٹرکس ضرب
attn_out, _ = self.mha(x, x, x)
return attn_out
rnn = CustomRNN(embedding_dim)
attention = CustomSelfAttention(embedding_dim)
# بینچ مارک RNN ترتیب وار لوپ
start = time.time()
rnn_out = rnn(x)
rnn_time = time.time() - start
# بینچ مارک خود توجہ متوازی عمل درآمد
start = time.time()
attn_out = attention(x)
attn_time = time.time() - start
print(f"RNN وقت (ترتیب وار لوپ): {rnn_time * 1000:.2f} ms")
print(f"Attention وقت (متوازی میٹرکس): {attn_time * 1000:.2f} ms")
5. ساختی موازنہ کا خلاصہ
| خصوصیت | RNN / LSTM | Transformer |
|---|---|---|
| ترتیب وار آپریشنز | $\mathcal{O}(N)$ | $\mathcal{O}(1)$ |
| فی تہہ کمپیوٹیشنل پیچیدگی | $\mathcal{O}(N \cdot d^2)$ | $\mathcal{O}(N^2 \cdot d)$ |
| زیادہ سے زیادہ راستے کی لمبائی | $\mathcal{O}(N)$ | $\mathcal{O}(1)$ |
| متوازی پروسیسنگ | محدود / ناممکن | انتہائی متوازی پروسیسنگ کے قابل |
| طویل فاصلے کے روابط | کمزور (بھول جاتا ہے) | بہترین (مستقل راستہ) |
نتیجہ
RNNs سے ٹرانسفارمرز کی طرف منتقلی کمپیوٹیشنل کارکردگی اور گنجائش کی وجہ سے ہوئی۔ ترتیب وار تکرار کو متوازی خود توجہ سے بدل کر، ٹرانسفارمرز نے ماڈل کے سائز اور ڈیٹا سیٹ کے سائز کو تیزی سے بڑھانے کی صلاحیت کو کھول دیا۔ اس ساختی پیش رفت نے جدید بڑے زبان کے ماڈلز (LLMs) جیسے GPT اور Claude کے لیے راستہ ہموار کیا، جن کی تربیت تکراری فن تعمیر کا استعمال کرتے ہوئے کمپیوٹیشنل طور پر ناممکن ہوتی۔