Transformer'lar Neden RNN ve LSTM'lerin Yerini Aldi
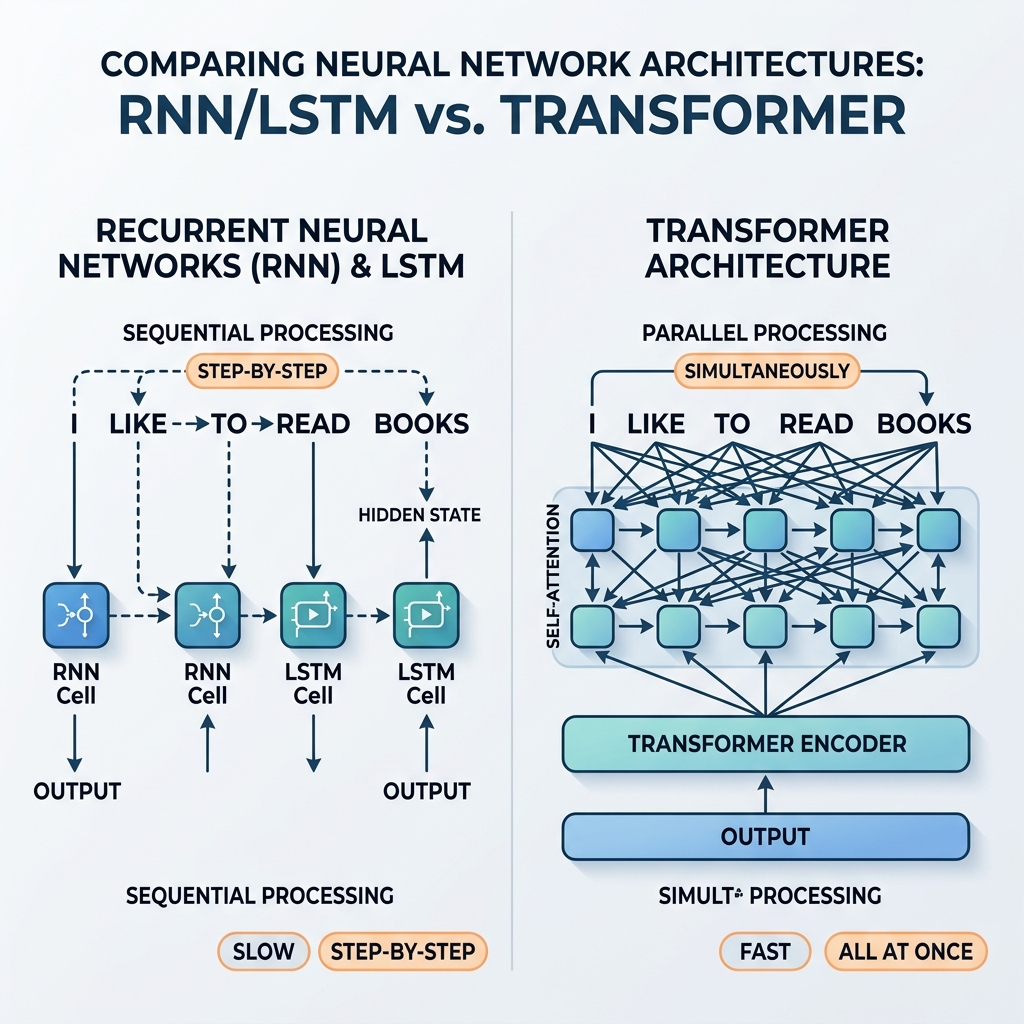
Yıllarca, Yinelemeli Yapay Sinir Ağları (RNN’ler) ve Uzun Kısa Süreli Bellek (LSTM) ağları, sıralı veri işlemenin tartışmasız şampiyonlarıydı. En gelişmiş çeviri sistemlerine, sesli asistanlara ve metin üretme modellerine güç veriyorlardı. Ancak 2017 yılında yayımlanan dönüm noktası niteliğindeki “Attention Is All You Need” (Vaswani ve ark.) makalesi Transformer mimarisini tanıttı. Birkaç yıl içinde, RNN’ler ve LSTM’ler ana akım yapay zeka modellerinden neredeyse tamamen silindi.
Bu hızlı geçiş neden gerçekleşti? Transformer’ı yinelemeli yapılara göre yapısal olarak bu kadar üstün kılan nedir? Bu makale, RNN/LSTM’lerin matematiksel ve mimari darboğazlarını ve Transformer’ların bunları nasıl aştığını incelemektedir.
1. Temel Darboğaz: Sıralı İşlem Engeli
Bir RNN’nin tanımlayıcı özelliği, yinelemeli durum geçişidir. Bir girdi dizisini işlemek için ağ, her bir belirteci (token) her seferinde bir adım olacak şekilde işler ve dahili gizli durumunu $h_t$, mevcut girdi $x_t$ ve önceki gizli durum $h_{t-1}$ temelinde günceller.
Matematiksel yineleme ilişkisi şu şekilde temsil edilir:
$$h_t = \tanh(W_{hh} h_{t-1} + W_{xh} x_t + b)$$
Paralelleştirme Sorunu
$h_t$ doğrudan $h_{t-1}$‘e bağlı olduğundan, işlem paralelleştirilemez. Bir cümledeki 100. kelimenin durumunu hesaplamak için ağın ilk 99 durumu sırayla hesaplaması gerekir.
GPU’lar ve TPU’lar devasa paralel matris hesaplamalarını destekleyecek şekilde geliştikçe, bu sıralı bağımlılık kritik bir darboğaz haline geldi. Büyük web ölçekli veri kümelerinde derin RNN modellerini eğitmek haftalar alıyordu; oysa hesaplamalar bağımsız olsaydı donanım çok daha hızlı çalışabilirdi.
2. Bilgi Darboğazı: Kaybolan Gradyanlar
Dizi uzunluğu $N$ arttıkça, zaman içinde geriye doğru yayılım (BPTT) gradyanları, yineleme ağırlığı $W_{hh}$ ile tekrarlanan matris çarpımını gerektirir. $W_{hh}$‘nin en büyük özdeğeri 1’den küçükse, gradyanlar üstel olarak küçülür (kaybolan gradyanlar). 1’den büyükse, üstel olarak büyürler (patlayan gradyanlar).
$$\frac{\partial E_t}{\partial h_1} = \frac{\partial E_t}{\partial h_t} \prod_{k=2}^{t} \frac{\partial h_k}{\partial h_{k-1}}$$
LSTM’ler ve Bellek Kısıtlaması
LSTM’ler, gradyanların doğrusal olarak akmasını sağlamak ve kaybolan gradyanları hafifletmek için hücre durumu (cell state) ve geçit mekanizmalarını (unutma geçidi, giriş geçidi, çıkış geçidi) getirdi. Ancak LSTM’ler bile birkaç yüz token’dan daha uzun dizilerle mücadele eder. Gizli vektörler, önceki tüm token’ların geçmişini sabit boyutlu bir temsile sıkıştırmaya zorlanır ve bu da bir “unutma” etkisine yol açar.
3. Transformer’lar Yineleme Sorununu Nasıl Çözdü?
Transformer, yinelemeyi tamamen bir kenara bırakarak yerine Self-Attention (Öz-Dikkat) mekanizmasını getirdi. Adım adım durum yayılımı yerine öz-dikkat, dizideki her token’ın aynı anda diğer tüm token’larla doğrudan etkileşime girmesini sağlar.
Dikkat matrisi şu şekilde hesaplanır:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{Q K^T}{\sqrt{d_k}}\right) V$$
Transformer, RNN darboğazlarını bu şekilde çözer:
- Kitlesel Paralelleştirme: Konumlar arasında sıralı bağımlılık olmadığından, giriş dizisindeki tüm token’lar aynı anda işlenir. Hesaplama grafiği sığdır ve son derece paralelleştirilebilirdir, böylece GPU’lar maksimum kapasitede kullanılır.
- Sabit Yol Uzunluğu: Herhangi iki token arasındaki yol uzunluğu $\mathcal{O}(1)$‘dir. Bu, uzun dizilerde kaybolan gradyan sorununu ortadan kaldırarak modellerin binlerce (hatta milyonlarca) token’lık bağlamları kolayca işlemesini sağlar.
- Konumsal Kodlamalar: Öz-dikkatte doğal bir dizi sırası bulunmadığından, Transformer kelime sırasını korumak için giriş gömmelerine Konumsal Kodlamalar (Positional Encodings) ekler.
4. PyTorch Sıralı İşlem Karşılaştırması
Aşağıdaki kod parçası, bir RNN hücresinin sıralı döngü tasarımı ile bir öz-dikkat katmanının paralel matris hesaplamasını karşılaştırmaktadır:
import torch
import torch.nn as nn
import time
batch_size = 32
seq_len = 512
embedding_dim = 128
# Girdiler: [batch_size, seq_len, embedding_dim]
x = torch.randn(batch_size, seq_len, embedding_dim)
# 1. Yinelemeli İşleme (RNN Hücresi)
class CustomRNN(nn.Module):
def __init__(self, dim):
super().__init__()
self.rnn_cell = nn.RNNCell(dim, dim)
def forward(self, x):
h = torch.zeros(x.size(0), x.size(2), device=x.device)
# Zaman adımları üzerinde sıralı döngü (paralelleştirilemez)
for t in range(x.size(1)):
h = self.rnn_cell(x[:, t, :], h)
return h
# 2. Paralel İşleme (Öz-Dikkat Katmanı)
class CustomSelfAttention(nn.Module):
def __init__(self, dim):
super().__init__()
self.num_heads = 4
self.mha = nn.MultiheadAttention(dim, self.num_heads, batch_first=True)
def forward(self, x):
# Tüm zaman adımlarında paralel matris çarpımı
attn_out, _ = self.mha(x, x, x)
return attn_out
rnn = CustomRNN(embedding_dim)
attention = CustomSelfAttention(embedding_dim)
# RNN Sıralı Döngü Testi
start = time.time()
rnn_out = rnn(x)
rnn_time = time.time() - start
# Öz-Dikkat Paralel Yürütme Testi
start = time.time()
attn_out = attention(x)
attn_time = time.time() - start
print(f"RNN Süresi (Sıralı döngü): {rnn_time * 1000:.2f} ms")
print(f"Dikkat Süresi (Paralel matris): {attn_time * 1000:.2f} ms")
5. Mimari Karşılaştırma Özeti
| Özellik | RNN / LSTM | Transformer |
|---|---|---|
| Sıralı İşlemler | $\mathcal{O}(N)$ | $\mathcal{O}(1)$ |
| Katman Başına Hesaplama Karmaşıklığı | $\mathcal{O}(N \cdot d^2)$ | $\mathcal{O}(N^2 \cdot d)$ |
| Maksimum Yol Uzunluğu | $\mathcal{O}(N)$ | $\mathcal{O}(1)$ |
| Paralelleştirme | Sınırlı / İmkansız | Son Derece Paralelleştirilebilir |
| Uzun Menzilli Bağımlılıklar | Zayıf (Unutur) | Mükemmel (Sabit yol) |
Sonuç
RNN’lerden Transformer’lara geçiş, hesaplama verimliliği ve kapasite tarafından yönlendirildi. Sıralı yinelemeyi paralel öz-dikkat ile değiştiren Transformer’lar, model boyutunu ve veri kümesi boyutunu üstel olarak ölçeklendirme yeteneğinin kilidini açtı. Bu yapısal atılım, yinelemeli mimariler kullanılarak eğitilmesi hesaplama açısından imkansız olan GPT ve Claude gibi modern Büyük Dil Modellerinin (LLM’ler) yolunu açtı.