为什么 Transformer 取代了 RNN 和 LSTM
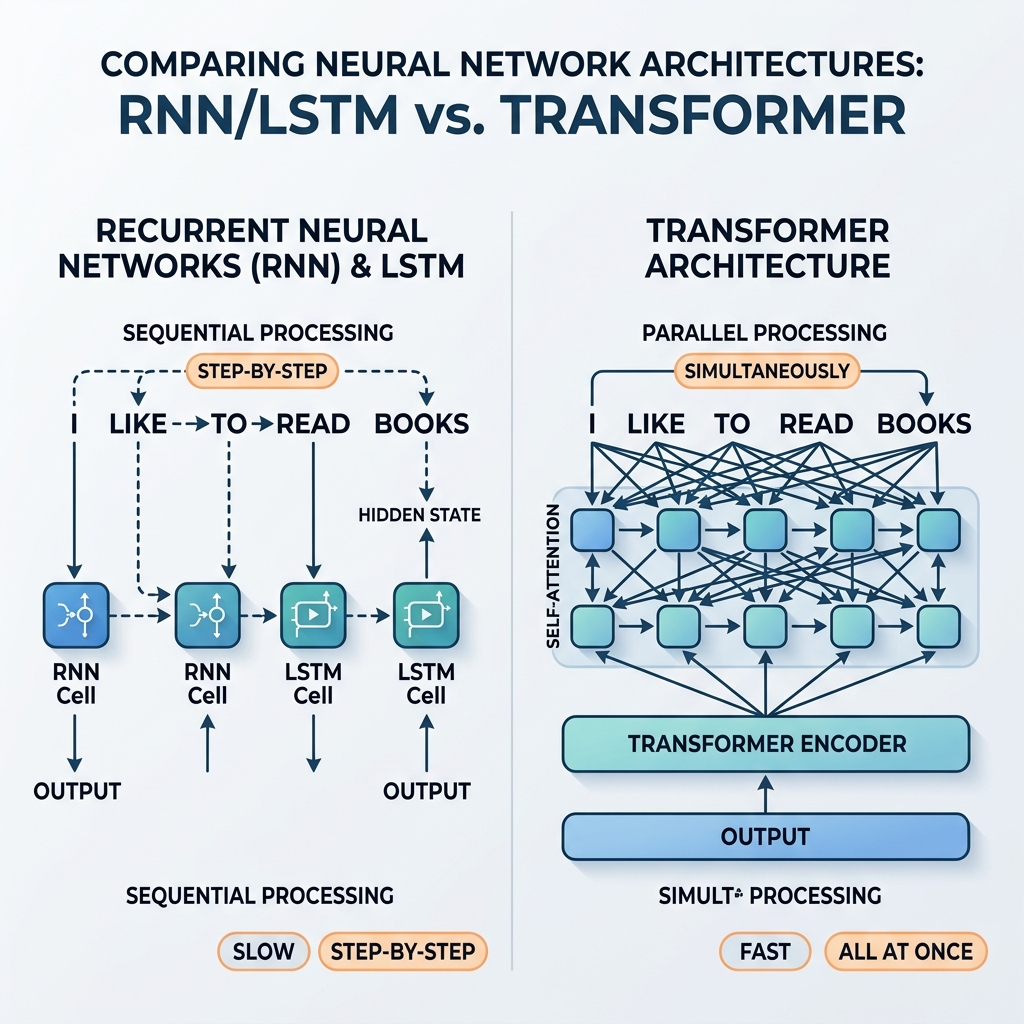
多年来,循环神经网络(RNN)和长短期记忆网络(LSTM)一直是序列数据处理领域无可争议的霸主。它们为最先进的翻译系统、语音助手和文本生成模型提供了强大的技术支持。然而,在 2017 年,一篇名为 “Attention Is All You Need”(Vaswani 等人)的里程碑式论文引入了 Transformer 架构。在短短几年内,RNN 和 LSTM 几乎完全退出了主流 AI 模型的舞台。
为什么会发生如此快速的转变?是什么让 Transformer 在结构上比循环网络更具优势?本文将探讨 RNN/LSTM 的数学和架构瓶颈,以及 Transformer 是如何克服它们的。
1. 核心瓶颈:串行限制
RNN 的决定性特征是其递归状态转换。为了处理输入序列,网络一步一步地处理每个 token,根据当前输入 $x_t$ 和前一个隐状态 $h_{t-1}$ 来更新其内部隐状态 $h_t$。
数学上的递推关系表示为:
$$h_t = \tanh(W_{hh} h_{t-1} + W_{xh} x_t + b)$$
并行化问题
由于 $h_t$ 直接依赖于 $h_{t-1}$,处理过程无法并行化。要计算一个句子中第 100 个单词的状态,网络必须顺序计算前 99 个状态。
随着 GPU 和 TPU 的发展以支持海量的并行矩阵计算,这种串行依赖性成为了致命的瓶颈。在大型网络数据集上训练深度 RNN 模型需要数周时间,而如果计算相互独立,硬件本可以运行得快得多。
2. 信息瓶颈:梯度消失
随着序列长度 $N$ 的增加,随时间反向传播(BPTT)梯度需要与循环权重 $W_{hh}$ 进行重复的矩阵乘法。如果 $W_{hh}$ 的最大特征值小于 1,梯度将呈指数级缩小(梯度消失);如果大于 1,则呈指数级增长(梯度爆炸)。
$$\frac{\partial E_t}{\partial h_1} = \frac{\partial E_t}{\partial h_t} \prod_{k=2}^{t} \frac{\partial h_k}{\partial h_{k-1}}$$
LSTM 与内存约束
LSTM 引入了细胞状态(cell state)和门控机制(遗忘门、输入门、输出门)以允许梯度线性流动,从而缓解了梯度消失问题。然而,即使是 LSTM,在处理超过几百个 token 的序列时也显得力不从心。隐向量被迫将所有先前 token 的历史信息压缩成一个固定大小的表示,从而导致“遗忘”效应。
3. Transformer 如何解决循环网络的问题
Transformer 完全摒弃了循环,取而代之的是自注意力机制(Self-Attention)。自注意力机制不采用逐步的状态传播,而是允许序列中的每个 token 同时与任何其他 token 直接交互。
注意力矩阵的计算公式为:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{Q K^T}{\sqrt{d_k}}\right) V$$
以下是 Transformer 解决 RNN 瓶颈的原理:
- 海量并行化: 由于不同位置之间没有串行依赖关系,输入序列中的所有 token 会同时被处理。计算图浅且高度可并行化,能将 GPU 的算力发挥到极致。
- 常数路径长度: 任意两个 token 之间的路径长度为 $\mathcal{O}(1)$。这消除了长序列上的梯度消失问题,使模型能够轻松处理成千上万(甚至数百万)个 token 的上下文。
- 位置编码: 由于自注意力机制中没有固定的序列顺序,Transformer 在输入嵌入中注入了位置编码(Positional Encodings),以保留单词顺序。
4. PyTorch 序列处理对比
下面的代码展示了 RNN 单元的串行循环设计与自注意力层的并行矩阵计算之间的对比:
import torch
import torch.nn as nn
import time
batch_size = 32
seq_len = 512
embedding_dim = 128
# 输入维度: [batch_size, seq_len, embedding_dim]
x = torch.randn(batch_size, seq_len, embedding_dim)
# 1. 循环处理 (RNN 单元)
class CustomRNN(nn.Module):
def __init__(self, dim):
super().__init__()
self.rnn_cell = nn.RNNCell(dim, dim)
def forward(self, x):
h = torch.zeros(x.size(0), x.size(2), device=x.device)
# 时间步上的串行循环 (无法并行化)
for t in range(x.size(1)):
h = self.rnn_cell(x[:, t, :], h)
return h
# 2. 并行处理 (自注意力层)
class CustomSelfAttention(nn.Module):
def __init__(self, dim):
super().__init__()
self.num_heads = 4
self.mha = nn.MultiheadAttention(dim, self.num_heads, batch_first=True)
def forward(self, x):
# 在所有时间步上并行进行矩阵乘法
attn_out, _ = self.mha(x, x, x)
return attn_out
rnn = CustomRNN(embedding_dim)
attention = CustomSelfAttention(embedding_dim)
# 测试 RNN 串行循环耗时
start = time.time()
rnn_out = rnn(x)
rnn_time = time.time() - start
# 测试自注意力并行计算耗时
start = time.time()
attn_out = attention(x)
attn_time = time.time() - start
print(f"RNN 时间 (串行循环): {rnn_time * 1000:.2f} ms")
print(f"Attention 时间 (并行矩阵): {attn_time * 1000:.2f} ms")
5. 架构特性对比摘要
| 特性 | RNN / LSTM | Transformer |
|---|---|---|
| 串行操作步骤 | $\mathcal{O}(N)$ | $\mathcal{O}(1)$ |
| 每层计算复杂度 | $\mathcal{O}(N \cdot d^2)$ | $\mathcal{O}(N^2 \cdot d)$ |
| 最大路径长度 | $\mathcal{O}(N)$ | $\mathcal{O}(1)$ |
| 并行化能力 | 受限 / 无法并行 | 高度可并行化 |
| 长距离依赖关系 | 较差 (易遗忘) | 极佳 (常数路径长度) |
结论
从 RNN 向 Transformer 的转变是由计算效率和模型容量驱动的。通过将串行循环替换为并行自注意力机制,Transformer 释放了指数级扩展模型规模和数据集大小的潜力。这一结构性的突破为现代大语言模型(LLM,如 GPT 和 Claude)铺平了道路,如果使用循环网络架构,它们的训练在计算上是根本无法实现的。