与法学硕士构建自主人工智能工作流程
大型语言模型 (LLM) 改变了我们与技术交互的方式,从简单的会话聊天机器人迅速转变为能够驱动复杂、多步骤操作的推理引擎。虽然单个提示响应交互可能很强大,但生成式人工智能在企业环境中的真正价值在于自主人工智能工作流程。
自主工作流程不是依靠人类操作员来协调每一步,而是使用法学硕士作为中央决策者,长期规划、执行、评估和自我纠正任务。
本次深入探讨了如何使用现代设计模式、状态机和强大的护栏来架构、构建和部署可靠的自主人工智能工作流程。
1. 代理转变:聊天机器人与工作流程 LLM申请的演变可以分为四个不同的自主级别:
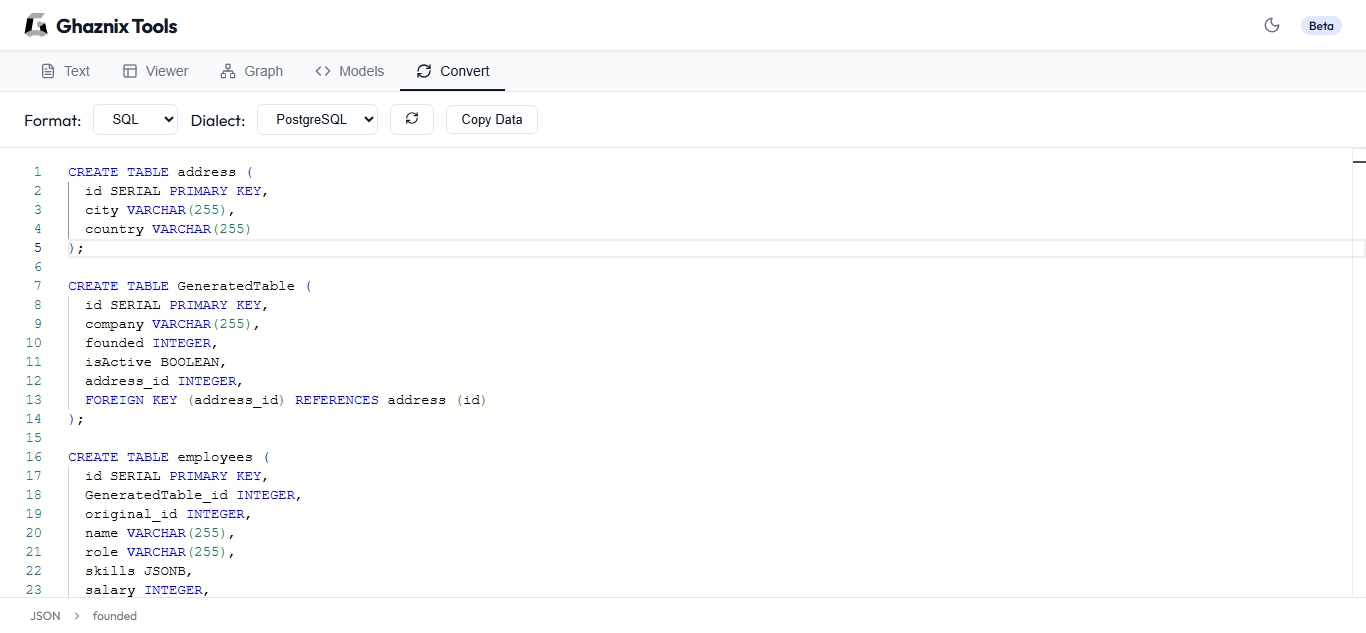
水平 范式 人类角色 核心机制 1 级 对话式聊天 高(每回合提示) 无状态单轮完成 2 级 工具调用/函数调用 中等(提供上下文) 模型选择API调用;返回结果 3级 定向工作流程 低(定义目标和图表) 带有 LLM 路由的硬编码状态机 4级 完全自主的代理 最小(定义目标/预算) LLM驱动的规划、执行和反思循环 虽然 4 级代理非常灵活,但众所周知,它们在生产环境中很难预测。因此,大多数企业架构都建立在第三级:定向工作流之上,将软件状态机的确定性可靠性与法学硕士的动态推理相结合。
2. 自主工作流程的核心支柱 要构建自主工作流程,您需要结合四个基本组件:
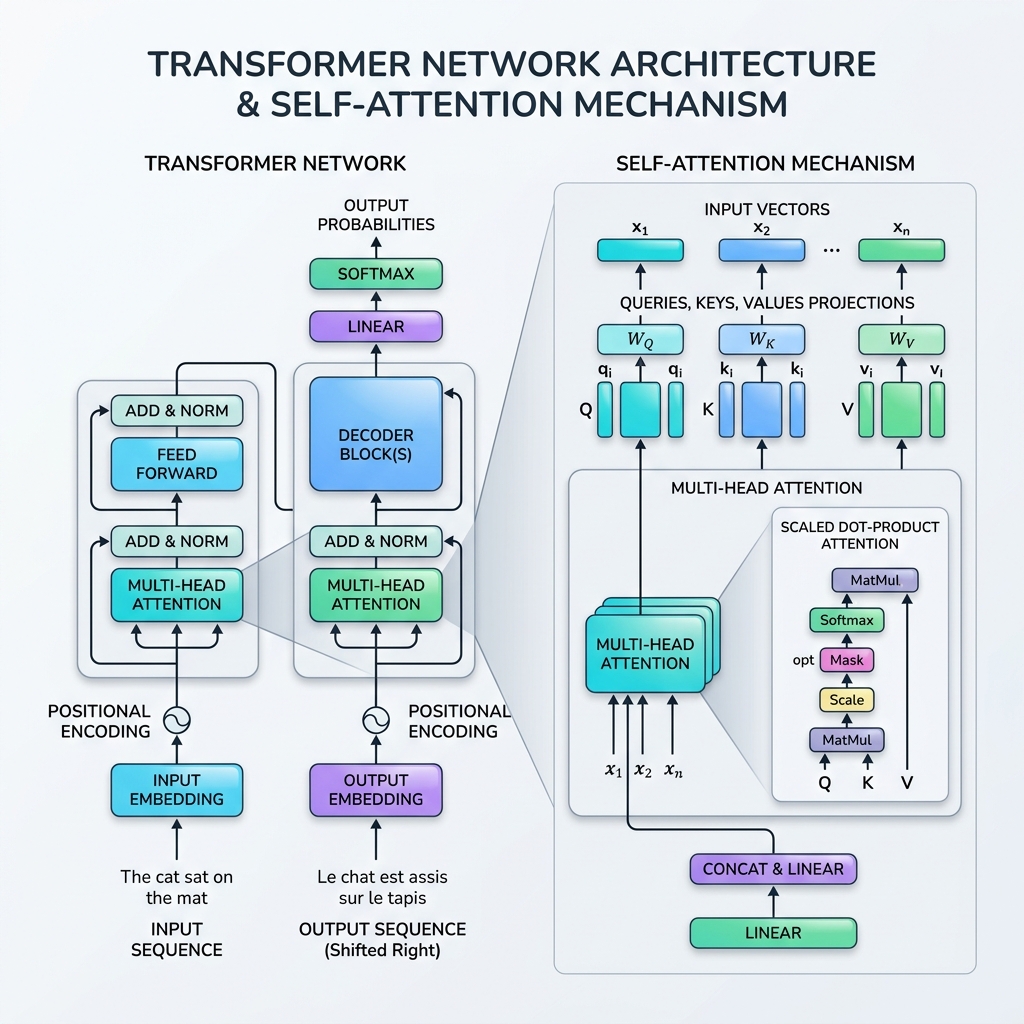
A. 推理与规划 工作流程的核心是规划范例。幼稚的 LLM 调用会尝试立即输出最终答案,这通常会导致推理失败。自主工作流程使用专门的规划循环:
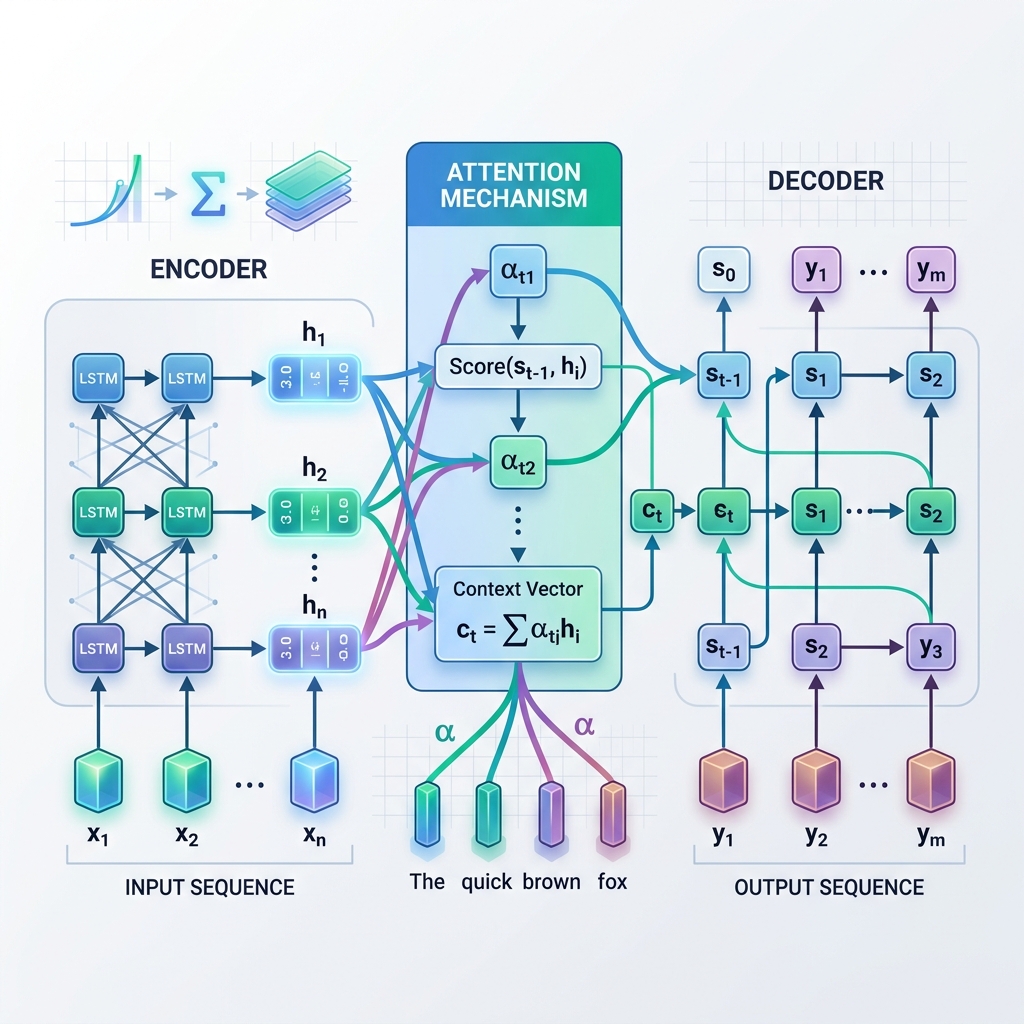
ReAct (Reason + Act):模型迭代地思考、行动(调用工具)、观察结果,重复这个循环,直到达到目标。 思想链 (CoT):强制模型在得出结论之前*输出其逐步推理。 思想树 (ToT):生成和评估多个替代路径,跟踪不同的分支,并在路径失败时回溯。 B. 短期和长期记忆 自治系统必须在多个执行周期中维护状态:
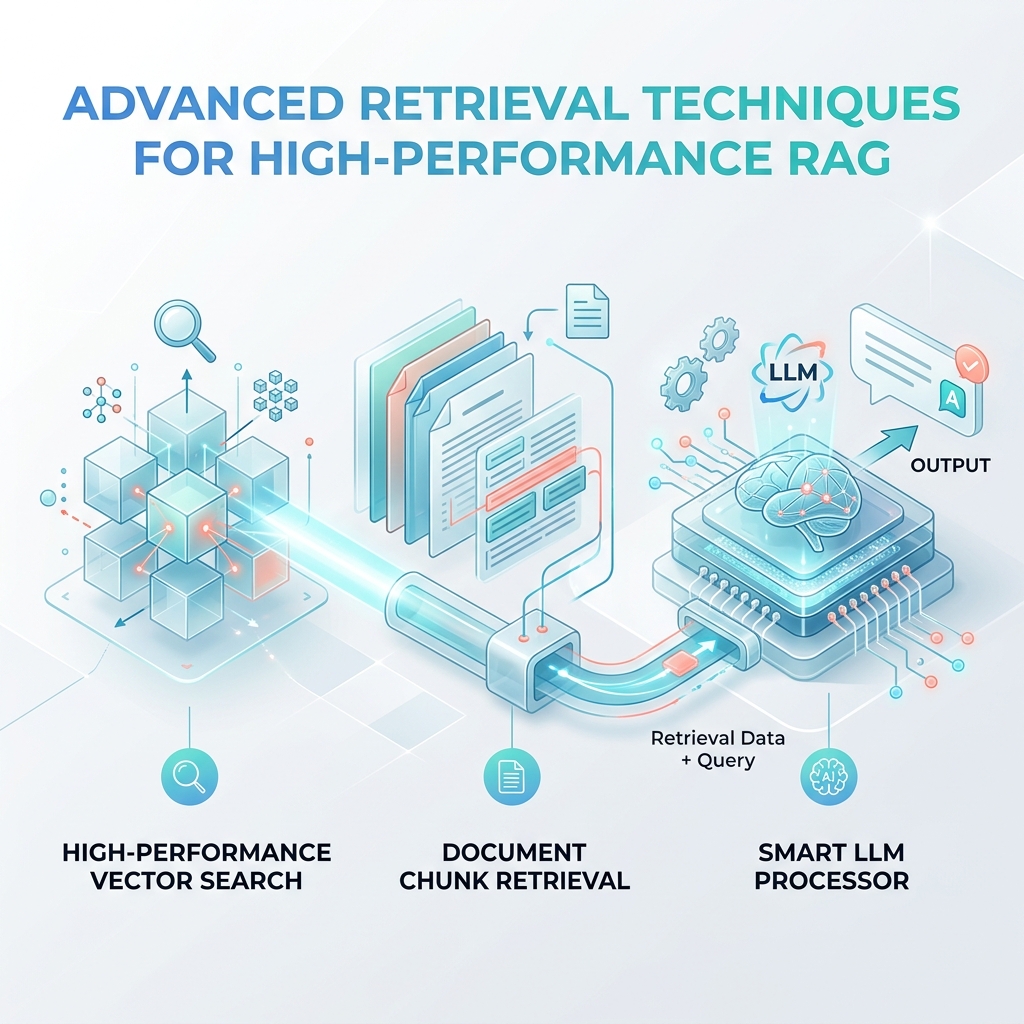
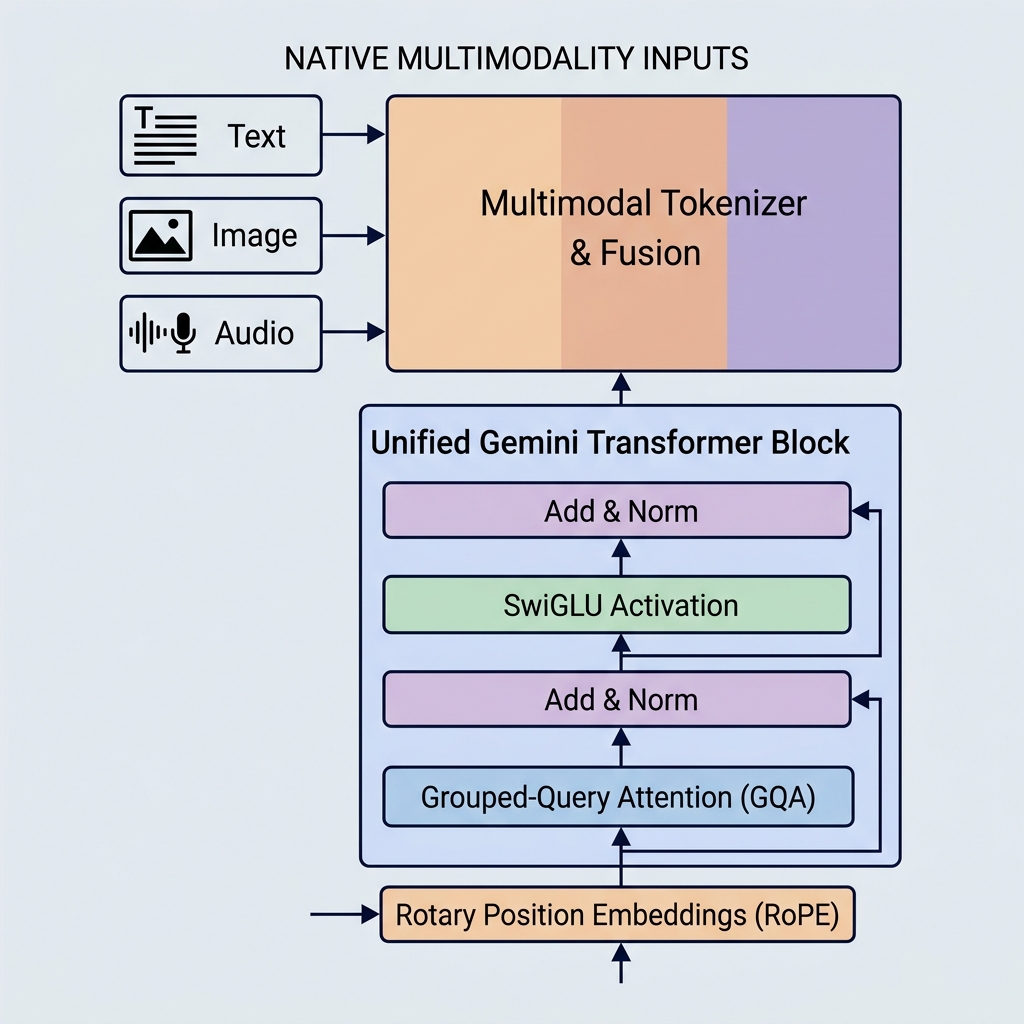
短期内存:跟踪工作流当前正在执行的操作的线程上下文、状态变量和执行日志。 长期记忆:矢量数据库和语义检索系统,允许工作流程调用历史运行、用户首选项和企业文档。 C. 工具和 Web 集成 为了在物理或数字世界中采取行动,法学硕士必须与外部服务交互。该模型需要访问数据库驱动程序、文件系统、Web 浏览器和第三方 API。现代工作流程越来越多地采用模型上下文协议 (MCP),标准化法学硕士如何发现并安全连接到上下文数据源和执行沙箱。
AI
Agents
LLMs
Orchestration
Software Architecture
Machine Learning