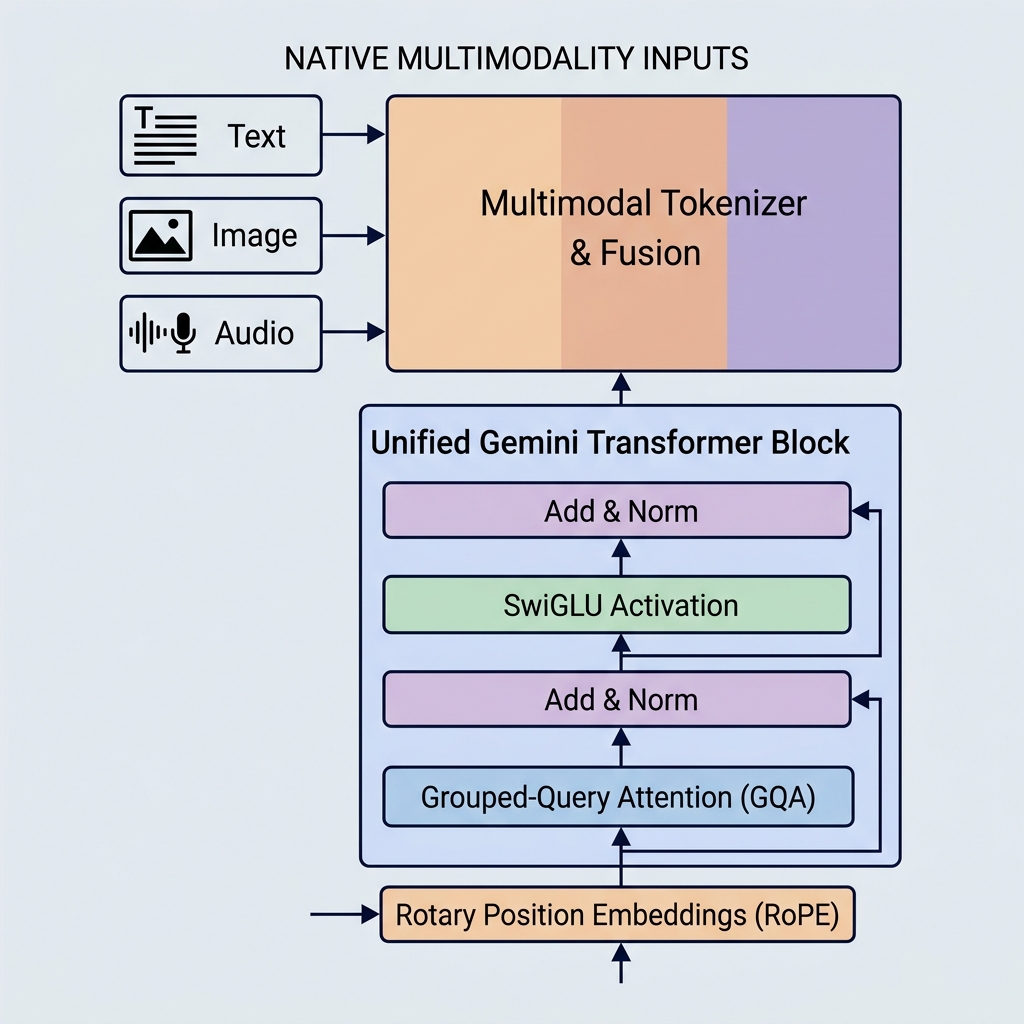
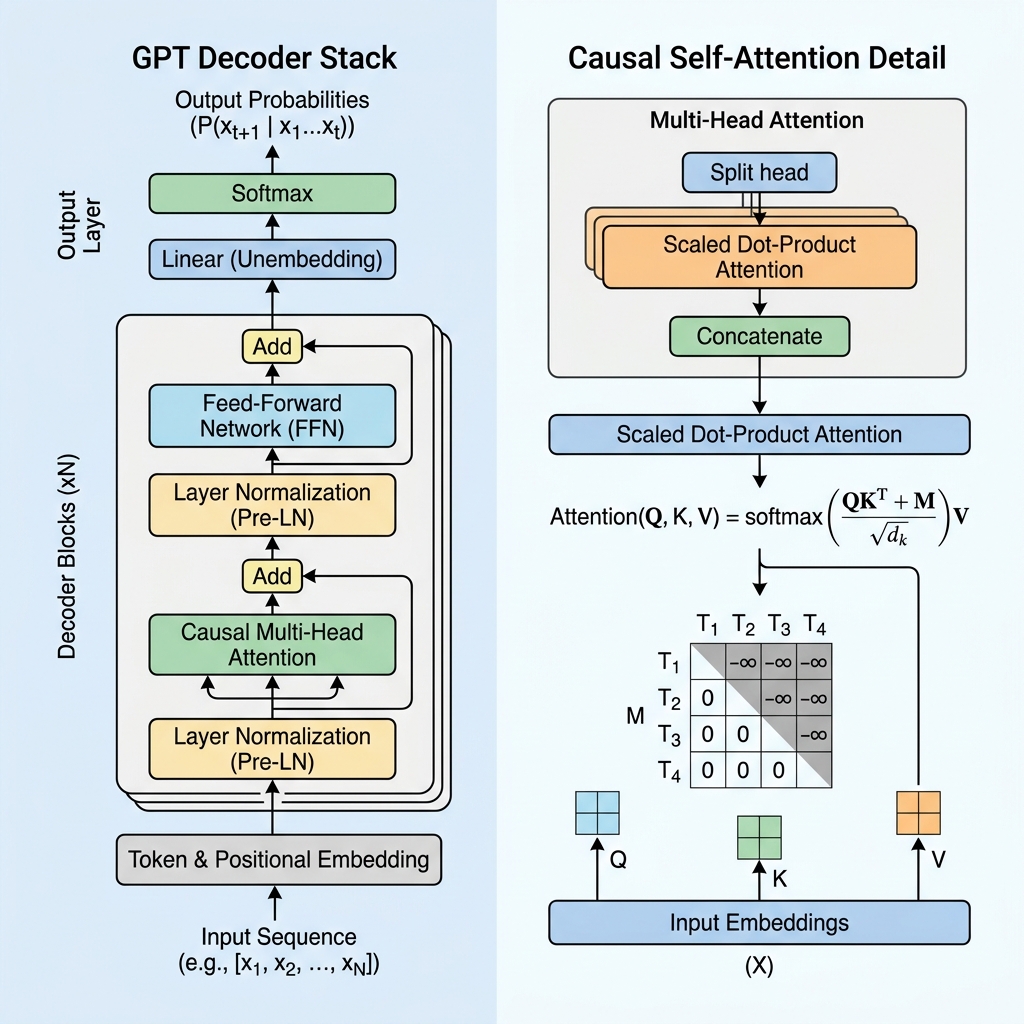
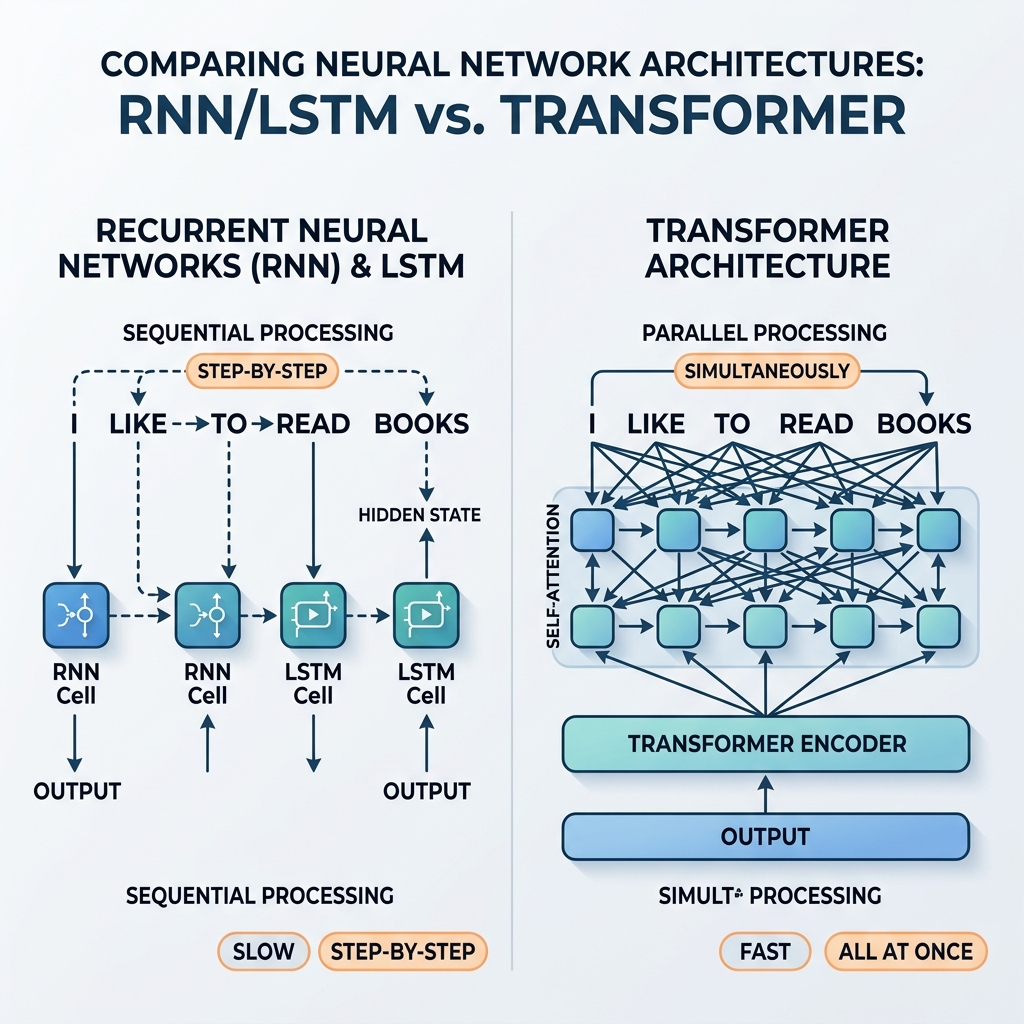
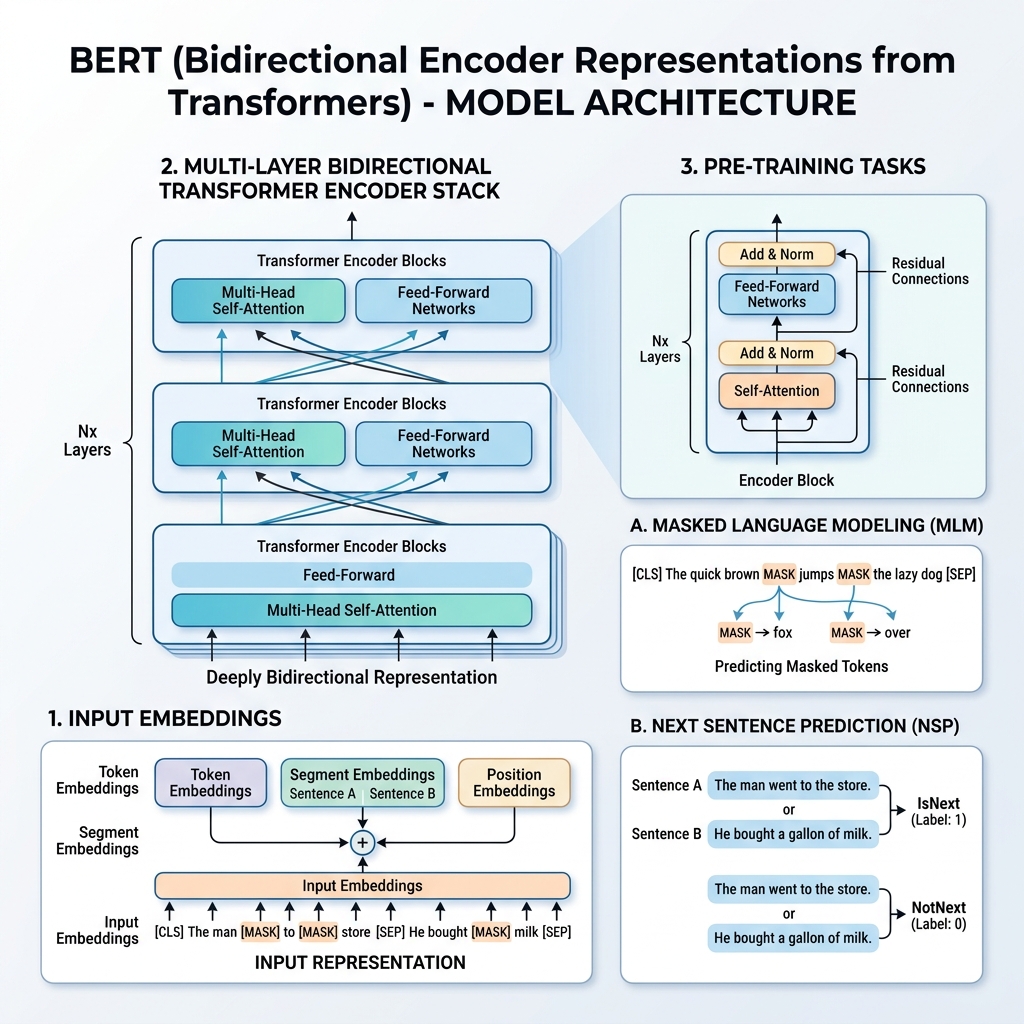
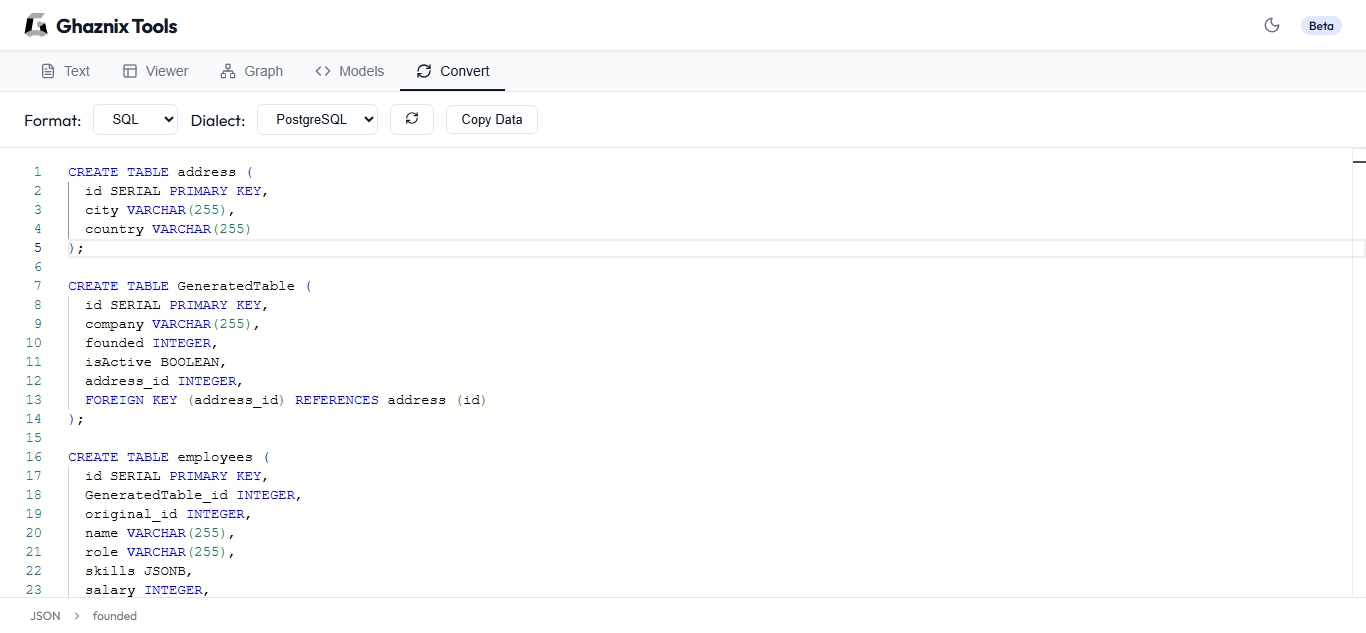
LLM を使用した自律型 AI ワークフローの構築
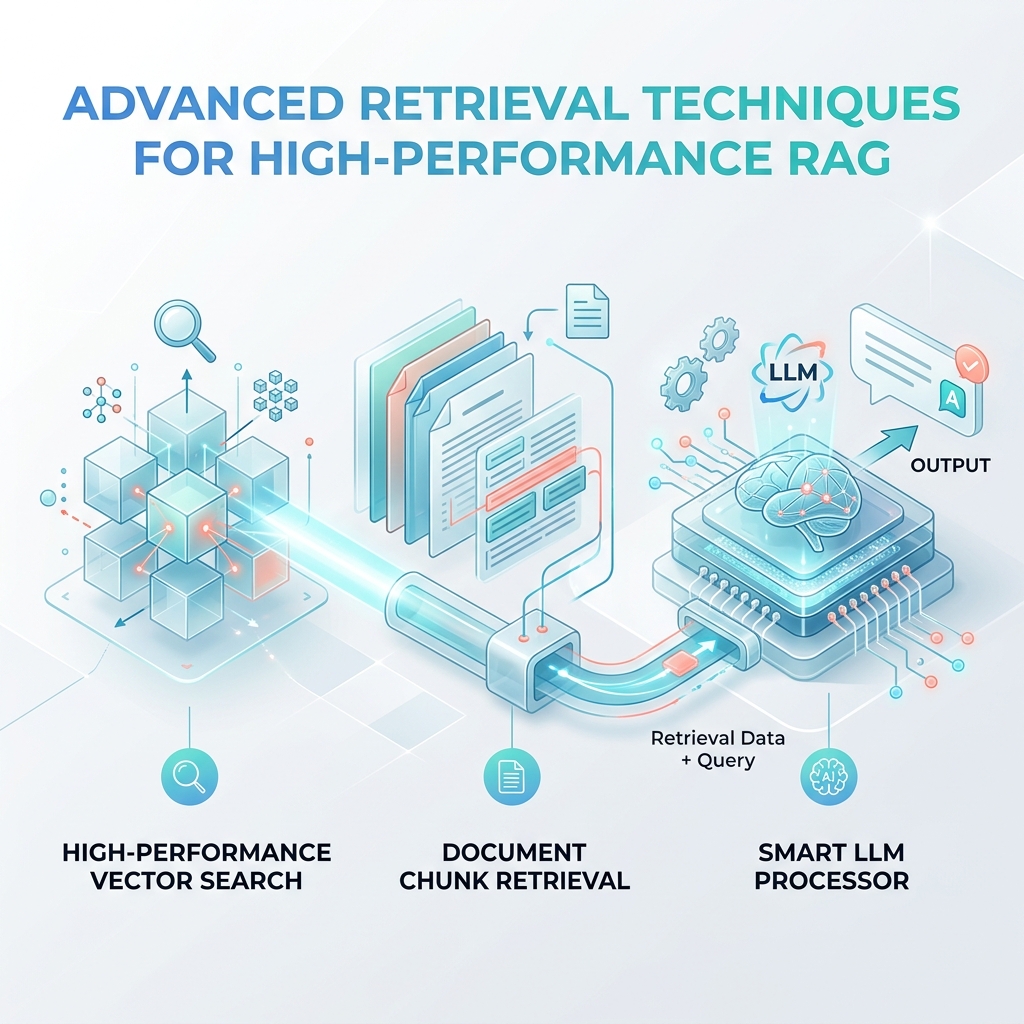
大規模言語モデル (LLM) は、私たちがテクノロジーと対話する方法を変革し、単純な会話型チャットボットから、複雑な複数ステップのアクションを実行できる推論エンジンへと急速に移行しました。単一のプロンプト応答インタラクションは強力ですが、企業環境における生成 AI の真の価値は 自律 AI ワークフローにあります。
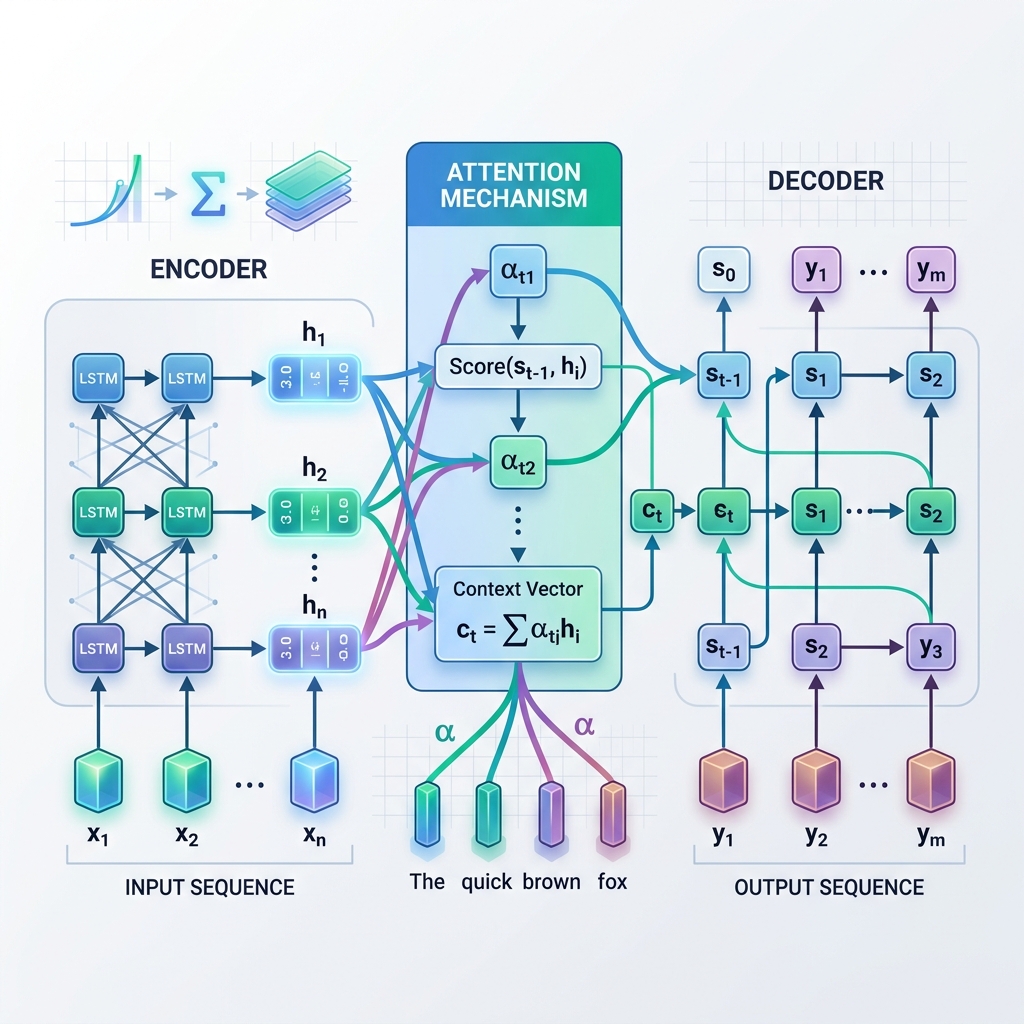
人間のオペレーターに依存してすべてのステップを調整するのではなく、自律型ワークフローは、長期間にわたってタスクを計画、実行、評価、自己修正する中心的な意思決定者として LLM を使用します。
この詳細な説明では、最新の設計パターン、ステート マシン、堅牢なガードレールを使用して、信頼性の高い自律型 AI ワークフローを設計、構築、展開する方法を探ります。
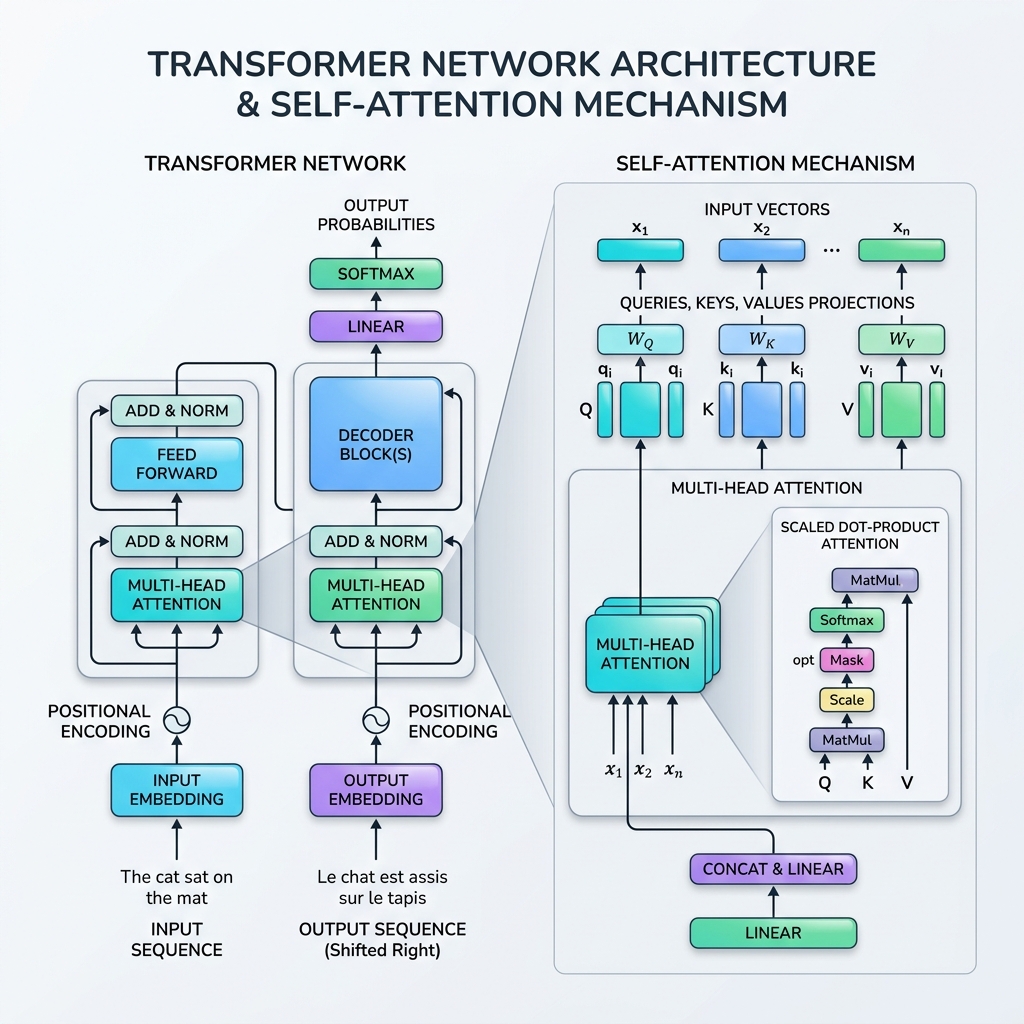
1. エージェントの変化: チャットボットとワークフロー LLM アプリケーションの進化は、自律性の 4 つの異なるレベルに分類できます。
レベル パラダイム 人間の役割 コアメカニズム レベル 1 会話型チャット 高 (毎ターンプロンプトが表示されます) ステートレスな 1 ターンの完了 レベル 2 ツール呼び出し / 関数呼び出し 中 (コンテキストを提供) モデルは呼び出す API を選択します。結果を返します レベル 3 指示されたワークフロー 低 (目標とグラフを定義) LLM ルーティングを備えたハードコーディングされたステート マシン レベル 4 完全自律型エージェント 最小限 (目的/予算を定義) LLM 主導の計画、実行、およびリフレクション ループ レベル 4 エージェントは柔軟性に優れていますが、運用環境での予測が難しいことで知られています。したがって、ほとんどのエンタープライズ アーキテクチャは、ソフトウェア ステート マシンの決定論的な信頼性と LLM の動的な推論を組み合わせた レベル 3: 指示されたワークフロー に基づいて構築されています。
AI
Agents
LLMs
Orchestration
Software Architecture
Machine Learning