Por qué los Transformers reemplazaron a las RNN y LSTM
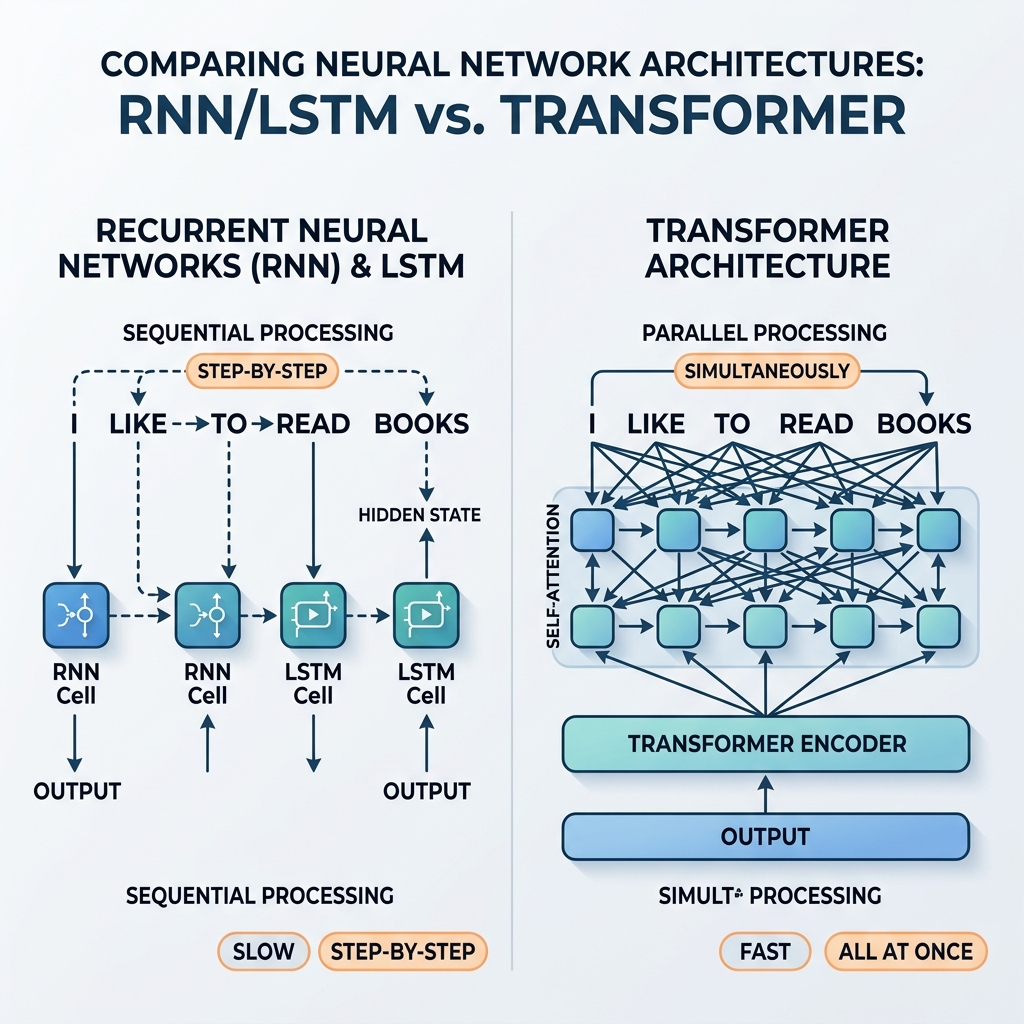
Durante años, las redes neuronales recurrentes (RNN) y las redes de memoria a corto y largo plazo (LSTM) fueron las campeonas indiscutibles del procesamiento de datos secuenciales. Impulsaron sistemas de traducción de última generación, asistentes de voz y modelos de generación de texto. Sin embargo, en 2017, el artículo fundamental “Attention Is All You Need” (Vaswani et al.) introdujo la arquitectura Transformer. En pocos años, las RNN y LSTM se eliminaron casi por completo de los modelos de IA principales.
¿Por qué ocurrió esta rápida transición? ¿Qué hace que el Transformer sea estructuralmente tan superior a la recurrencia? Este artículo explora los cuellos de botella matemáticos y arquitectónicos de las RNN/LSTM y cómo los Transformers los superaron.
1. El cuello de botella principal: el límite secuencial
La característica definitoria de una RNN es su transición de estado recursiva. Para procesar una secuencia de entradas, la red procesa cada token un paso a la vez, actualizando su estado oculto interno $h_t$ en función de la entrada actual $x_t$ y del estado oculto anterior $h_{t-1}$.
La relación de recurrencia matemática se representa como:
$$h_t = \tanh(W_{hh} h_{t-1} + W_{xh} x_t + b)$$
El problema de la paralelización
Dado que $h_t$ depende directamente de $h_{t-1}$, el procesamiento no se puede paralelizar. Para calcular el estado de la centésima palabra en una oración, la red debe calcular secuencialmente los primeros 99 estados.
A medida que las GPU y TPU evolucionaron para admitir cálculos de matrices paralelos masivos, esta dependencia secuencial se convirtió en un cuello de botella crítico. El entrenamiento de modelos RNN profundos en grandes conjuntos de datos web tomaba semanas, mientras que el hardware era capaz de funcionar mucho más rápido si los cálculos eran independientes.
2. El cuello de botella de la información: gradientes que se desvanecen
A medida que aumenta la longitud de la secuencia $N$, la retropropagación de gradientes a través del tiempo (BPTT) requiere la multiplicación repetida de matrices con el peso de recurrencia $W_{hh}$. Si el valor propio más grande de $W_{hh}$ es menor que 1, los gradientes se reducen exponencialmente (gradientes que se desvanecen). Si es mayor que 1, crecen exponencialmente (gradientes que explotan).
$$\frac{\partial E_t}{\partial h_1} = \frac{\partial E_t}{\partial h_t} \prod_{k=2}^{t} \frac{\partial h_k}{\partial h_{k-1}}$$
Las LSTM y la restricción de memoria
Las LSTM introdujeron el estado de la celda y mecanismos de compuertas (forget gate, input gate, output gate) para permitir que los gradientes fluyan linealmente, mitigando los gradientes que se desvanecen. Sin embargo, incluso las LSTM tienen dificultades con secuencias de más de unos pocos cientos de tokens. Los vectores ocultos se ven obligados a comprimir el historial de todos los tokens anteriores en una representación de tamaño fijo, lo que lleva a un efecto de “olvido”.
3. Cómo resolvieron los Transformers el problema de la recurrencia
El Transformer descartó la recurrencia por completo, reemplazándola con el mecanismo de Self-Attention (Autoatención). En lugar de la propagación del estado paso a paso, la autoatención permite que cada token interactúe directamente con cualquier otro token de la secuencia simultáneamente.
La matriz de atención se calcula mediante:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{Q K^T}{\sqrt{d_k}}\right) V$$
Así es como el Transformer resuelve los cuellos de botella de las RNN:
- Paralelización masiva: Dado que no hay dependencias secuenciales entre posiciones, todos los tokens de la secuencia de entrada se procesan al mismo tiempo. El gráfico computacional es poco profundo y altamente paralelizable, utilizando las GPU al máximo.
- Longitud de trayectoria constante: La longitud de la trayectoria entre dos tokens cualesquiera es $\mathcal{O}(1)$. Esto elimina el problema del gradiente que se desvanece sobre secuencias largas, lo que permite que los modelos manejen fácilmente contextos de miles (o incluso millones) de tokens.
- Codificaciones posicionales: Dado que no hay un orden de secuencia inherente en la autoatención, el Transformer inyecta Codificaciones Posicionales en los embeddings de entrada para preservar el orden de las palabras.
4. Comparación de procesamiento de secuencias en PyTorch
El siguiente fragmento de código contrasta el diseño de bucle secuencial de una celda RNN con el cálculo de matriz paralelo de una capa de autoatención:
import torch
import torch.nn as nn
import time
batch_size = 32
seq_len = 512
embedding_dim = 128
# Entradas: [batch_size, seq_len, embedding_dim]
x = torch.randn(batch_size, seq_len, embedding_dim)
# 1. Procesamiento recurrente (Celda RNN)
class CustomRNN(nn.Module):
def __init__(self, dim):
super().__init__()
self.rnn_cell = nn.RNNCell(dim, dim)
def forward(self, x):
h = torch.zeros(x.size(0), x.size(2), device=x.device)
# Bucle secuencial sobre pasos de tiempo (no se puede paralelizar)
for t in range(x.size(1)):
h = self.rnn_cell(x[:, t, :], h)
return h
# 2. Procesamiento paralelo (Capa de autoatención)
class CustomSelfAttention(nn.Module):
def __init__(self, dim):
super().__init__()
self.num_heads = 4
self.mha = nn.MultiheadAttention(dim, self.num_heads, batch_first=True)
def forward(self, x):
# Multiplicación de matrices paralela en todos los pasos de tiempo
attn_out, _ = self.mha(x, x, x)
return attn_out
rnn = CustomRNN(embedding_dim)
attention = CustomSelfAttention(embedding_dim)
# Evaluación bucle secuencial RNN
start = time.time()
rnn_out = rnn(x)
rnn_time = time.time() - start
# Evaluación ejecución paralela de autoatención
start = time.time()
attn_out = attention(x)
attn_time = time.time() - start
print(f"Tiempo RNN (Bucle secuencial): {rnn_time * 1000:.2f} ms")
print(f"Tiempo de atención (Matriz paralela): {attn_time * 1000:.2f} ms")
5. Resumen de comparación arquitectónica
| Característica | RNN / LSTM | Transformer |
|---|---|---|
| Operaciones secuenciales | $\mathcal{O}(N)$ | $\mathcal{O}(1)$ |
| Complejidad computacional por capa | $\mathcal{O}(N \cdot d^2)$ | $\mathcal{O}(N^2 \cdot d)$ |
| Longitud de trayectoria máxima | $\mathcal{O}(N)$ | $\mathcal{O}(1)$ |
| Paralelización | Limitada / Imposible | Altamente paralelizable |
| Dependencias de largo alcance | Deficientes (Olvida) | Excelentes (Trayectoria constante) |
Conclusión
El cambio de RNN a Transformers fue impulsado por la eficiencia computacional y la capacidad. Al reemplazar la recurrencia secuencial con autoatención paralela, los Transformers permitieron escalar el tamaño del modelo y del conjunto de datos exponencialmente. Este avance estructural allanó el camino para los modelos de lenguaje grande (LLM) modernos como GPT y Claude, que habrían sido computacionalmente imposibles de entrenar utilizando arquitecturas recurrentes.