Почему Transformers заменили RNN и LSTM
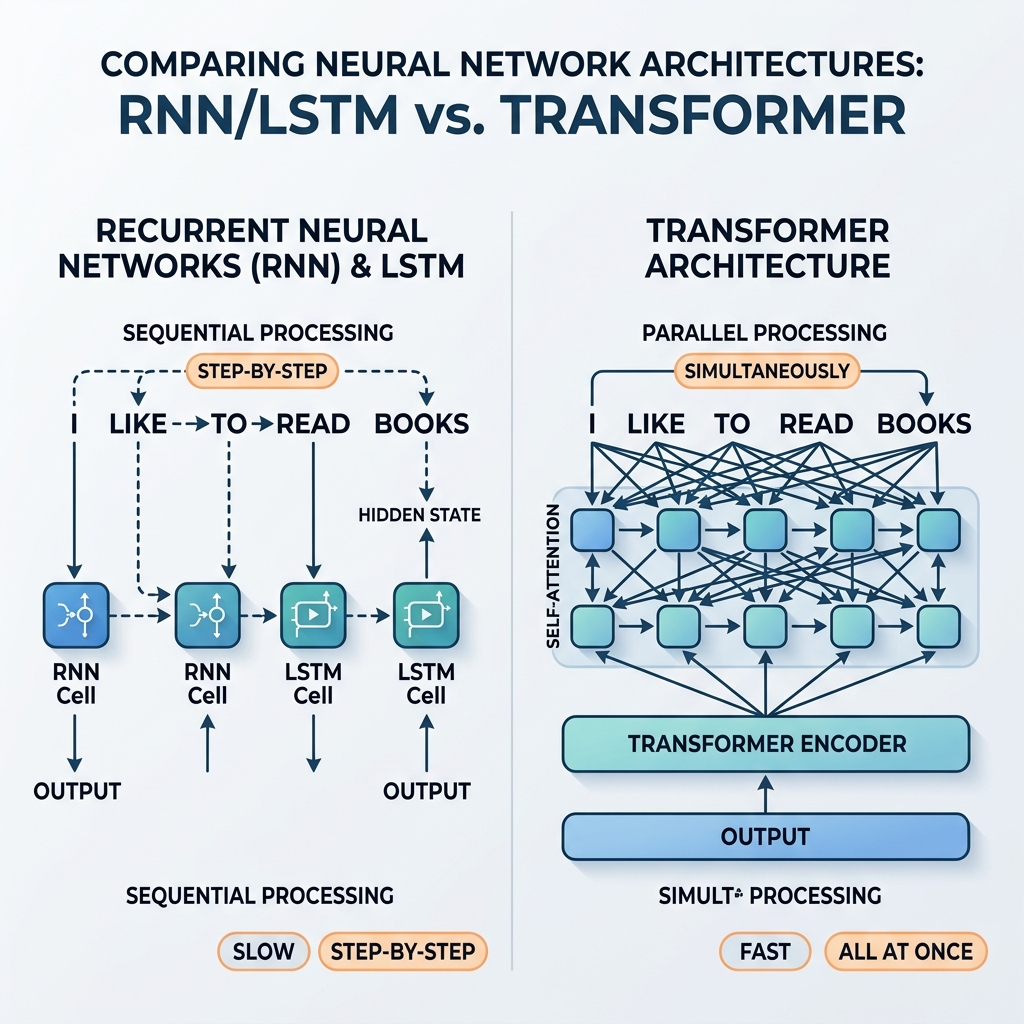
В течение многих лет рекуррентные нейронные сети (RNN) и сети долгой краткосрочной памяти (LSTM) были бесспорными лидерами в обработке последовательных данных. Они лежали в основе современных систем перевода, голосовых помощников и моделей генерации текста. Однако в 2017 году революционная статья «Attention Is All You Need» (Vaswani et al.) представила архитектуру Transformer. В течение нескольких лет RNN и LSTM были практически полностью вытеснены из основных моделей искусственного интеллекта.
Почему произошел этот стремительный переход? Что делает Transformer структурно настолько превосходящим рекуррентные архитектуры? В этой статье исследуются математические и архитектурные ограничения RNN/LSTM и то, как Transformers их преодолели.
1. Основное ограничение: последовательный барьер
Определяющей характеристикой RNN является ее рекурсивный переход состояния. Чтобы обработать последовательность входных данных, сеть обрабатывает каждый токен по очереди, обновляя свое внутреннее скрытое состояние $h_t$ на основе текущего входа $x_t$ и предыдущего скрытого состояния $h_{t-1}$.
Математическое рекуррентное соотношение представляется как:
$$h_t = \tanh(W_{hh} h_{t-1} + W_{xh} x_t + b)$$
Проблема параллелизации
Поскольку $h_t$ напрямую зависит от $h_{t-1}$, процесс обработки не может быть параллелизован. Чтобы вычислить состояние сотого слова в предложении, сеть должна последовательно вычислить первые 99 состояний.
По мере развития GPU и TPU, оптимизированных для массовых параллельных матричных вычислений, эта последовательная зависимость стала критическим узким местом. Обучение глубоких моделей RNN на больших веб-датасетах занимало недели, тогда как оборудование могло работать намного быстрее, если бы вычисления были независимыми.
2. Информационное ограничение: затухающие градиенты
При увеличении длины последовательности $N$ обратное распространение ошибки во времени (BPTT) требует многократного умножения матриц на рекуррентный вес $W_{hh}$. Если наибольшее собственное значение $W_{hh}$ меньше 1, градиенты уменьшаются экспоненциально (затухающие градиенты). Если оно больше 1, они растут экспоненциально (взрывающиеся градиенты).
$$\frac{\partial E_t}{\partial h_1} = \frac{\partial E_t}{\partial h_t} \prod_{k=2}^{t} \frac{\partial h_k}{\partial h_{k-1}}$$
LSTM и ограничение памяти
LSTM ввели состояние ячейки (cell state) и механизмы вентилей (вентиль забывания, входной вентиль, выходной вентиль), чтобы позволить градиентам течь линейно, смягчая проблему затухания градиентов. Однако даже LSTM испытывают трудности с последовательностями длиннее нескольких сотен токенов. Скрытые векторы вынуждены сжимать историю всех предыдущих токенов в представление фиксированного размера, что приводит к эффекту «забывания».
3. Как Transformers решили проблему рекуррентности
Transformer полностью отказался от рекуррентности, заменив ее механизмом Self-Attention (самовнимания). Вместо пошагового распространения состояния самовнимание позволяет каждому токену напрямую и одновременно взаимодействовать со всеми другими токенами в последовательности.
Матрица внимания рассчитывается по формуле:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{Q K^T}{\sqrt{d_k}}\right) V$$
Вот как Transformer решает проблемы RNN:
- Массовая параллелизация: Поскольку между позициями нет последовательных зависимостей, все токены во входной последовательности обрабатываются одновременно. Вычислительный граф является неглубоким и легко параллелизуемым, что позволяет максимально эффективно использовать графические процессоры (GPU).
- Постоянная длина пути: Длина пути между любыми двумя токенами составляет $\mathcal{O}(1)$. Это устраняет проблему затухания градиента на длинных последовательностях, позволяя моделям легко обрабатывать контексты в тысячи (или даже миллионы) токенов.
- Позиционное кодирование: Поскольку в самовнимании нет встроенного порядка последовательности, Transformer добавляет позиционное кодирование (Positional Encodings) во входные эмбеддинги для сохранения порядка слов.
4. Сравнение обработки последовательностей на PyTorch
Приведенный ниже фрагмент кода противопоставляет последовательный цикл ячейки RNN параллельному матричному вычислению слоя самовнимания:
import torch
import torch.nn as nn
import time
batch_size = 32
seq_len = 512
embedding_dim = 128
# Входные данные: [batch_size, seq_len, embedding_dim]
x = torch.randn(batch_size, seq_len, embedding_dim)
# 1. Рекуррентная обработка (ячейка RNN)
class CustomRNN(nn.Module):
def __init__(self, dim):
super().__init__()
self.rnn_cell = nn.RNNCell(dim, dim)
def forward(self, x):
h = torch.zeros(x.size(0), x.size(2), device=x.device)
# Последовательный цикл по временным шагам (не может быть параллелизован)
for t in range(x.size(1)):
h = self.rnn_cell(x[:, t, :], h)
return h
# 2. Параллельная обработка (слой Self-Attention)
class CustomSelfAttention(nn.Module):
def __init__(self, dim):
super().__init__()
self.num_heads = 4
self.mha = nn.MultiheadAttention(dim, self.num_heads, batch_first=True)
def forward(self, x):
# Параллельное умножение матриц по всем временным шагам
attn_out, _ = self.mha(x, x, x)
return attn_out
rnn = CustomRNN(embedding_dim)
attention = CustomSelfAttention(embedding_dim)
# Тестирование последовательного цикла RNN
start = time.time()
rnn_out = rnn(x)
rnn_time = time.time() - start
# Тестирование параллельного вычисления Self-Attention
start = time.time()
attn_out = attention(x)
attn_time = time.time() - start
print(f"Время RNN (последовательный цикл): {rnn_time * 1000:.2f} ms")
print(f"Время Attention (параллельная матрица): {attn_time * 1000:.2f} ms")
5. Сводная таблица архитектурного сравнения
| Характеристика | RNN / LSTM | Transformer |
|---|---|---|
| Последовательные операции | $\mathcal{O}(N)$ | $\mathcal{O}(1)$ |
| Вычислительная сложность на слой | $\mathcal{O}(N \cdot d^2)$ | $\mathcal{O}(N^2 \cdot d)$ |
| Максимальная длина пути | $\mathcal{O}(N)$ | $\mathcal{O}(1)$ |
| Параллелизация | Ограничена / Невозможна | Высокопараллельная |
| Длинные зависимости | Слабые (Забывает) | Отличные (Постоянный путь) |
Заключение
Переход от RNN к Transformers был обусловлен вычислительной эффективностью и емкостью моделей. Заменив последовательную рекуррентность параллельным самовниманием, Transformers открыли возможность экспоненциально масштабировать размер моделей и наборов данных. Этот структурный прорыв проложил путь к современным большим языковым моделям (LLM), таким как GPT и Claude, обучение которых на рекуррентных архитектурах было бы невозможным с вычислительной точки зрения.