ट्रांसफॉर्मर ने RNN और LSTM को क्यों बदल दिया
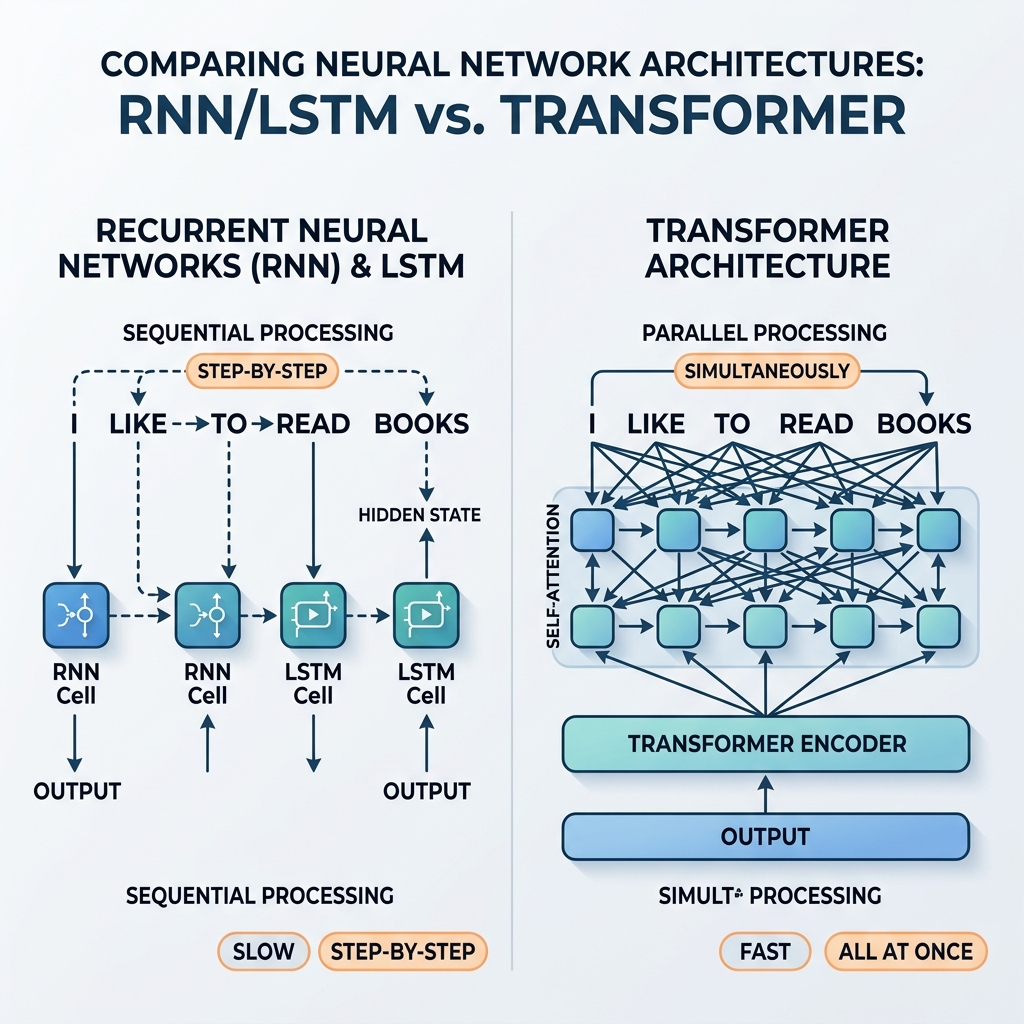
बरसों तक, रिकरेंट न्यूरल नेटवर्क (RNN) और लॉन्ग शॉर्ट-टर्म मेमोरी (LSTM) नेटवर्क अनुक्रमिक डेटा (sequential data) प्रसंस्करण के निर्विवाद विजेता थे। उन्होंने अत्याधुनिक अनुवाद प्रणालियों, वॉयस सहायकों और टेक्स्ट जनरेशन मॉडलों को संचालित किया। हालाँकि, 2017 में, मौलिक शोध पत्र “Attention Is All You Need” (Vaswani et al.) ने ट्रांसफॉर्मर आर्किटेक्चर को पेश किया। कुछ ही वर्षों के भीतर, RNN और LSTM लगभग पूरी तरह से मुख्यधारा के एआई मॉडलों से बाहर हो गए।
यह तीव्र परिवर्तन क्यों हुआ? ट्रांसफॉर्मर को संरचनात्मक रूप से पुनरावृत्ति (recurrence) से इतना बेहतर क्या बनाता है? यह लेख RNN/LSTM की गणितीय और आर्किटेक्चरल सीमाओं और ट्रांसफॉर्मर ने उन्हें कैसे पार किया, इसकी पड़ताल करता है।
1. मुख्य बाधा: अनुक्रमिक बाधा (Sequential Bottleneck)
RNN की परिभाषित विशेषता इसकी पुनरावर्ती स्थिति संक्रमण (recursive state transition) है। इनपुट के अनुक्रम को संसाधित करने के लिए, नेटवर्क एक समय में एक टोकन को संसाधित करता है, वर्तमान इनपुट $x_t$ और पिछली छिपी हुई स्थिति $h_{t-1}$ के आधार पर अपनी आंतरिक छिपी हुई स्थिति $h_t$ को अपडेट करता है।
गणितीय पुनरावृत्ति संबंध को इस प्रकार दर्शाया गया है:
$$h_t = \tanh(W_{hh} h_{t-1} + W_{xh} x_t + b)$$
समानांतरकरण (Parallelization) की समस्या
चूंकि $h_t$ सीधे $h_{t-1}$ पर निर्भर करता है, इसलिए प्रसंस्करण को समानांतर नहीं किया जा सकता है। एक वाक्य में 100वें शब्द की स्थिति की गणना करने के लिए, नेटवर्क को अनुक्रमिक रूप से पहले 99 स्थितियों की गणना करनी होगी।
जैसे-जैसे बड़े पैमाने पर समानांतर मैट्रिक्स गणनाओं का समर्थन करने के लिए जीपीयू और टीपीयू विकसित हुए, यह अनुक्रमिक निर्भरता एक गंभीर बाधा बन गई। बड़े वेब-स्तरीय डेटासेट पर गहरे RNN मॉडलों को प्रशिक्षित करने में हफ्तों लग जाते थे, जबकि यदि गणना स्वतंत्र होती तो हार्डवेयर बहुत तेजी से चलने में सक्षम था।
2. सूचना की बाधा: लुप्त होते ग्रेडिएंट (Vanishing Gradients)
जैसे-जैसे अनुक्रम लंबाई $N$ बढ़ती है, समय के साथ बैकप्रोपेगेटिंग ग्रेडिएंट (BPTT) के लिए पुनरावृत्ति वजन $W_{hh}$ के साथ बार-बार मैट्रिक्स गुणन की आवश्यकता होती है। यदि $W_{hh}$ का सबसे बड़ा आइजनेवैल्यू 1 से कम है, तो ग्रेडिएंट तेजी से सिकुड़ते हैं (vanishing gradients)। यदि यह 1 से अधिक है, तो वे तेजी से बढ़ते हैं (exploding gradients)।
$$\frac{\partial E_t}{\partial h_1} = \frac{\partial E_t}{\partial h_t} \prod_{k=2}^{t} \frac{\partial h_k}{\partial h_{k-1}}$$
LSTM और मेमोरी की सीमा
LSTM ने ग्रेडिएंट को रैखिक रूप से प्रवाहित करने की अनुमति देने के लिए सेल स्थिति और गेटिंग तंत्र (forget gate, input gate, output gate) पेश किया, जिससे लुप्त होते ग्रेडिएंट कम हुए। हालाँकि, LSTM भी कुछ सौ टोकन से लंबे अनुक्रमों के साथ संघर्ष करते हैं। छिपे हुए वेक्टर पिछले सभी टोकन के इतिहास को एक निश्चित आकार के प्रतिनिधित्व में संपीड़ित करने के लिए मजबूर होते हैं, जिससे “भूलने” का प्रभाव पैदा होता है।
3. ट्रांसफॉर्मर ने पुनरावृत्ति की समस्या को कैसे हल किया
ट्रांसफॉर्मर ने पुनरावृत्ति को पूरी तरह से त्याग दिया, इसे Self-Attention (स्व-अटेंशन) तंत्र से बदल दिया। चरण-दर-चरण स्थिति प्रसार के बजाय, स्व-अटेंशन अनुक्रम में प्रत्येक टोकन को एक ही समय में सीधे हर दूसरे टोकन के साथ बातचीत करने की अनुमति देता है।
अटेंशन मैट्रिक्स की गणना निम्न का उपयोग करके की जाती है:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{Q K^T}{\sqrt{d_k}}\right) V$$
यहाँ बताया गया है कि ट्रांसफॉर्मर RNN की बाधाओं को कैसे हल करता है:
- बड़े पैमाने पर समानांतरकरण: चूंकि स्थितियों के बीच कोई अनुक्रमिक निर्भरता नहीं होती है, इसलिए इनपुट अनुक्रम में सभी टोकन एक ही समय में संसाधित होते हैं। कम्प्यूटेशनल ग्राफ उथला और अत्यधिक समानांतर है, जो जीपीयू का अधिकतम क्षमता तक उपयोग करता है।
- स्थिर पथ लंबाई: किन्हीं दो टोकन के बीच पथ की लंबाई $\mathcal{O}(1)$ है। यह लंबे अनुक्रमों पर लुप्त ग्रेडिएंट की समस्या को समाप्त करता है, जिससे मॉडल आसानी से हजारों (या लाखों) टोकन के संदर्भों को संभाल सकते हैं।
- स्थितीय एन्कोडिंग (Positional Encodings): चूंकि स्व-अटेंशन में कोई अंतर्निहित अनुक्रम क्रम नहीं होता है, इसलिए ट्रांसफॉर्मर शब्द क्रम को बनाए रखने के लिए इनपुट एम्बेडिंग में स्थितीय एन्कोडिंग इंजेक्ट करता है।
4. PyTorch अनुक्रम प्रसंस्करण तुलना
नीचे दिया गया कोड स्निपेट एक RNN सेल के अनुक्रमिक लूप डिज़ाइन की तुलना एक स्व-अटेंशन परत की समानांतर मैट्रिक्स गणना से करता है:
import torch
import torch.nn as nn
import time
batch_size = 32
seq_len = 512
embedding_dim = 128
# इनपुट: [batch_size, seq_len, embedding_dim]
x = torch.randn(batch_size, seq_len, embedding_dim)
# 1. पुनरावर्ती प्रसंस्करण (RNN सेल)
class CustomRNN(nn.Module):
def __init__(self, dim):
super().__init__()
self.rnn_cell = nn.RNNCell(dim, dim)
def forward(self, x):
h = torch.zeros(x.size(0), x.size(2), device=x.device)
# समय चरणों पर अनुक्रमिक लूप (समानांतर नहीं किया जा सकता)
for t in range(x.size(1)):
h = self.rnn_cell(x[:, t, :], h)
return h
# 2. समानांतर प्रसंस्करण (स्व-अटेंशन परत)
class CustomSelfAttention(nn.Module):
def __init__(self, dim):
super().__init__()
self.num_heads = 4
self.mha = nn.MultiheadAttention(dim, self.num_heads, batch_first=True)
def forward(self, x):
# सभी समय चरणों में समानांतर मैट्रिक्स गुणन
attn_out, _ = self.mha(x, x, x)
return attn_out
rnn = CustomRNN(embedding_dim)
attention = CustomSelfAttention(embedding_dim)
# बेंचमार्क RNN अनुक्रमिक लूप
start = time.time()
rnn_out = rnn(x)
rnn_time = time.time() - start
# बेंचमार्क स्व-अटेंशन समानांतर निष्पादन
start = time.time()
attn_out = attention(x)
attn_time = time.time() - start
print(f"RNN समय (अनुक्रमिक लूप): {rnn_time * 1000:.2f} ms")
print(f"Attention समय (समानांतर मैट्रिक्स): {attn_time * 1000:.2f} ms")
5. आर्किटेक्चरल तुलना सारांश
| विशेषता | RNN / LSTM | Transformer |
|---|---|---|
| अनुक्रमिक संचालन | $\mathcal{O}(N)$ | $\mathcal{O}(1)$ |
| प्रति परत कम्प्यूटेशनल जटिलता | $\mathcal{O}(N \cdot d^2)$ | $\mathcal{O}(N^2 \cdot d)$ |
| अधिकतम पथ लंबाई | $\mathcal{O}(N)$ | $\mathcal{O}(1)$ |
| समानांतरकरण | सीमित / असंभव | अत्यधिक समानांतर करने योग्य |
| दीर्घकालिक निर्भरताएँ | खराब (भूल जाता है) | उत्कृष्ट (स्थिर पथ) |
निष्कर्ष
RNN से ट्रांसफॉर्मर में बदलाव कम्प्यूटेशनल दक्षता और क्षमता से प्रेरित था। अनुक्रमिक पुनरावृत्ति को समानांतर स्व-अटेंशन से बदलकर, ट्रांसफॉर्मर ने मॉडल के आकार और डेटासेट के आकार को तेजी से बढ़ाने की क्षमता को खोल दिया। इस संरचनात्मक सफलता ने आधुनिक बड़े भाषा मॉडल (LLM) जैसे GPT और Claude के लिए मार्ग प्रशस्त किया, जिन्हें आवर्ती आर्किटेक्चर का उपयोग करके प्रशिक्षित करना कम्प्यूटेशनल रूप से असंभव होता।