Por que os Transformers substituíram as RNNs e LSTMs
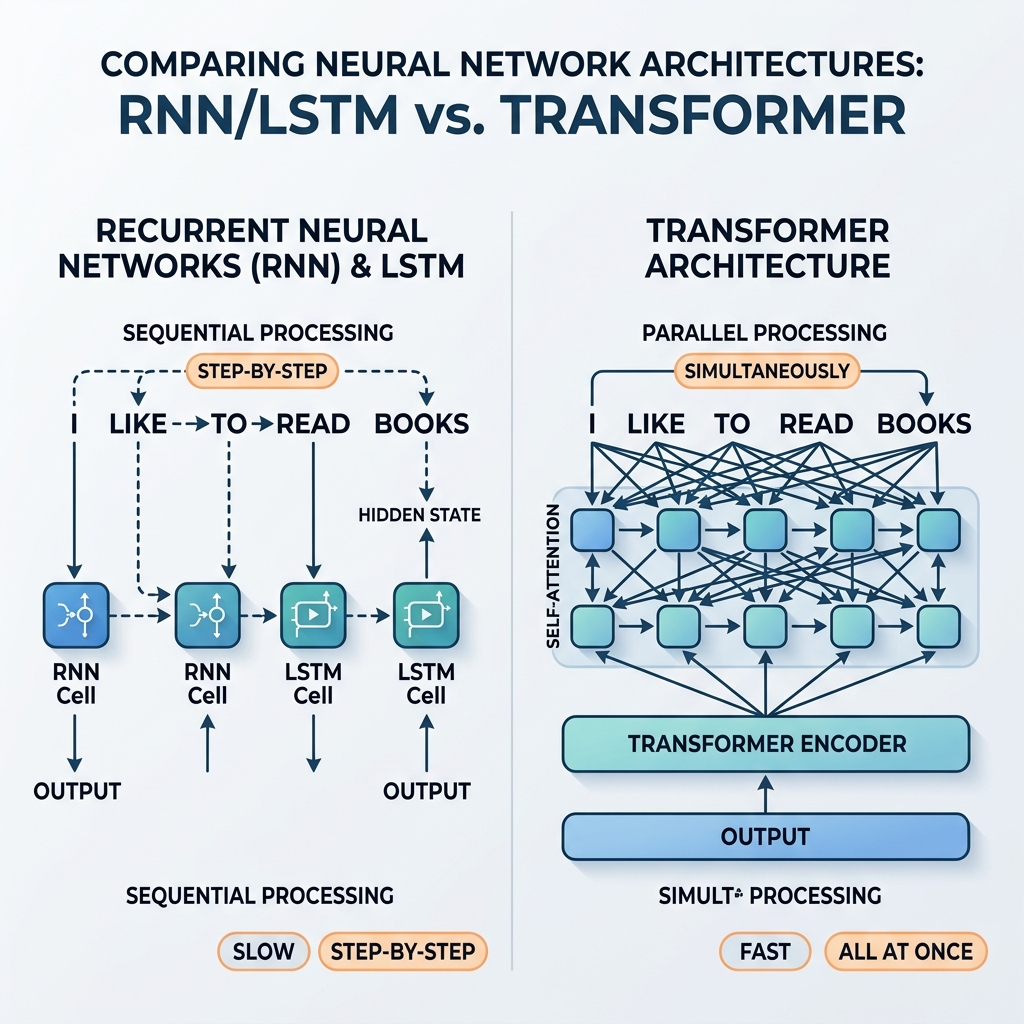
Por anos, as Redes Neurais Recorrentes (RNNs) e as redes de memória de longo prazo (LSTM) foram as campeãs incontestáveis do processamento de dados sequenciais. Elas alimentavam sistemas de tradução de última geração, assistentes de voz e modelos de geração de texto. No entanto, em 2017, o artigo seminal “Attention Is All You Need” (Vaswani et al.) introduziu a arquitetura Transformer. Em poucos anos, as RNNs e LSTMs foram quase inteiramente eliminadas dos modelos de IA tradicionais.
Por que essa transição rápida aconteceu? O que torna o Transformer estruturalmente tão superior à recorrência? Este artigo explora os gargalos matemáticos e arquitetônicos das RNNs/LSTMs e como os Transformers os superaram.
1. O Gargalo Principal: Limitação Sequencial
A característica definidora de uma RNN é sua transição de estado recursiva. Para processar uma sequência de entradas, a rede processa cada token um passo de cada vez, atualizando seu estado oculto interno $h_t$ com base na entrada atual $x_t$ e no estado oculto anterior $h_{t-1}$.
A relação de recorrência matemática é representada como:
$$h_t = \tanh(W_{hh} h_{t-1} + W_{xh} x_t + b)$$
O Problema da Paralelização
Como $h_t$ depende diretamente de $h_{t-1}$, o processamento não pode ser paralelizado. Para calcular o estado da centésima palavra em uma frase, a rede deve calcular sequencialmente os primeiros 99 estados.
À medida que as GPUs e TPUs evoluíram para suportar cálculos de matrizes paralelos massivos, essa dependência sequencial tornou-se um gargalo crítico. O treinamento de modelos RNN profundos em grandes conjuntos de dados da web levava semanas, enquanto o hardware era capaz de rodar muito mais rápido se os cálculos fossem independentes.
2. O Gargalo de Informação: Gradientes Desvanecentes
À medida que o comprimento da sequência $N$ aumenta, a retropropagação de gradientes através do tempo (BPTT) requer a multiplicação repetida de matrizes com o peso de recorrência $W_{hh}$. Se o maior autovalor de $W_{hh}$ for menor que 1, os gradientes diminuem exponencialmente (gradientes desvanecentes). Se for maior que 1, eles crescem exponencialmente (gradientes explodindo).
$$\frac{\partial E_t}{\partial h_1} = \frac{\partial E_t}{\partial h_t} \prod_{k=2}^{t} \frac{\partial h_k}{\partial h_{k-1}}$$
LSTMs e a Restrição de Memória
As LSTMs introduziram o estado da célula e mecanismos de portas (forget gate, input gate, output gate) para permitir que os gradientes fluam linearmente, mitigando os gradientes desvanecentes. No entanto, mesmo as LSTMs têm dificuldades com sequências maiores que algumas centenas de tokens. Os vetores ocultos são forçados a compactar o histórico de todos os tokens anteriores em uma representação de tamanho fixo, levando a um efeito de “esquecimento”.
3. Como os Transformers Resolveram o Problema da Recorrência
O Transformer descartou a recorrência completamente, substituindo-a pelo mecanismo de Self-Attention (Autoatenção). Em vez da propagação de estado passo a passo, a autoatenção permite que cada token interaja diretamente com qualquer outro token na sequência simultaneamente.
A matriz de atenção é calculada usando:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{Q K^T}{\sqrt{d_k}}\right) V$$
É assim que o Transformer resolve os gargalos das RNNs:
- Paralelização Massiva: Como não há dependências sequenciais entre as posições, todos os tokens na sequência de entrada são processados ao mesmo tempo. O gráfico computacional é raso e altamente paralelizável, utilizando as GPUs em sua capacidade máxima.
- Comprimento de Caminho Constante: O comprimento do caminho entre dois tokens quaisquer é $\mathcal{O}(1)$. Isso elimina o problema do gradiente desvanecente em sequências longas, permitindo que os modelos lidem facilmente com contextos de milhares (ou até milhões) de tokens.
- Codificações Posicionais: Como não há ordem sequencial inerente na autoatenção, o Transformer injeta Codificações Posicionais nos embeddings de entrada para preservar a ordem das palavras.
4. Comparação de Processamento de Sequência em PyTorch
O trecho de código abaixo contrasta o design de loop sequencial de uma célula RNN com o cálculo de matriz paralelo de uma camada de autoatenção:
import torch
import torch.nn as nn
import time
batch_size = 32
seq_len = 512
embedding_dim = 128
# Entradas: [batch_size, seq_len, embedding_dim]
x = torch.randn(batch_size, seq_len, embedding_dim)
# 1. Processamento Recorrente (Célula RNN)
class CustomRNN(nn.Module):
def __init__(self, dim):
super().__init__()
self.rnn_cell = nn.RNNCell(dim, dim)
def forward(self, x):
h = torch.zeros(x.size(0), x.size(2), device=x.device)
# Loop sequencial sobre etapas de tempo (não pode ser paralelizado)
for t in range(x.size(1)):
h = self.rnn_cell(x[:, t, :], h)
return h
# 2. Processamento Paralelo (Camada de Autoatenção)
class CustomSelfAttention(nn.Module):
def __init__(self, dim):
super().__init__()
self.num_heads = 4
self.mha = nn.MultiheadAttention(dim, self.num_heads, batch_first=True)
def forward(self, x):
# Multiplicação de matriz paralela em todas as etapas de tempo
attn_out, _ = self.mha(x, x, x)
return attn_out
rnn = CustomRNN(embedding_dim)
attention = CustomSelfAttention(embedding_dim)
# Benchmark loop sequencial RNN
start = time.time()
rnn_out = rnn(x)
rnn_time = time.time() - start
# Benchmark execução paralela de autoatenção
start = time.time()
attn_out = attention(x)
attn_time = time.time() - start
print(f"Tempo RNN (Loop sequencial): {rnn_time * 1000:.2f} ms")
print(f"Tempo de Atenção (Matriz paralela): {attn_time * 1000:.2f} ms")
5. Resumo da Comparação Arquitetônica
| Característica | RNN / LSTM | Transformer |
|---|---|---|
| Operações Sequenciais | $\mathcal{O}(N)$ | $\mathcal{O}(1)$ |
| Complexidade Computacional por Camada | $\mathcal{O}(N \cdot d^2)$ | $\mathcal{O}(N^2 \cdot d)$ |
| Comprimento Máximo de Caminho | $\mathcal{O}(N)$ | $\mathcal{O}(1)$ |
| Paralelização | Limitada / Impossível | Altamente Paralelizável |
| Dependências de Longo Alcance | Ruins (Esquece) | Excelentes (Caminho constante) |
Conclusão
A mudança de RNNs para Transformers foi impulsionada pela eficiência computacional e capacidade. Ao substituir a recorrência sequencial pela autoatenção paralela, os Transformers permitiram escalar o tamanho do modelo e do conjunto de dados exponencialmente. Esse avanço estrutural abriu caminho para os modernos Grandes Modelos de Linguagem (LLMs) como GPT e Claude, que teriam sido computacionalmente inviáveis de treinar usando arquiteturas recorrentes.