Transformer ネットワークと自己アテンション(Self-Attention)メカニズムの理解
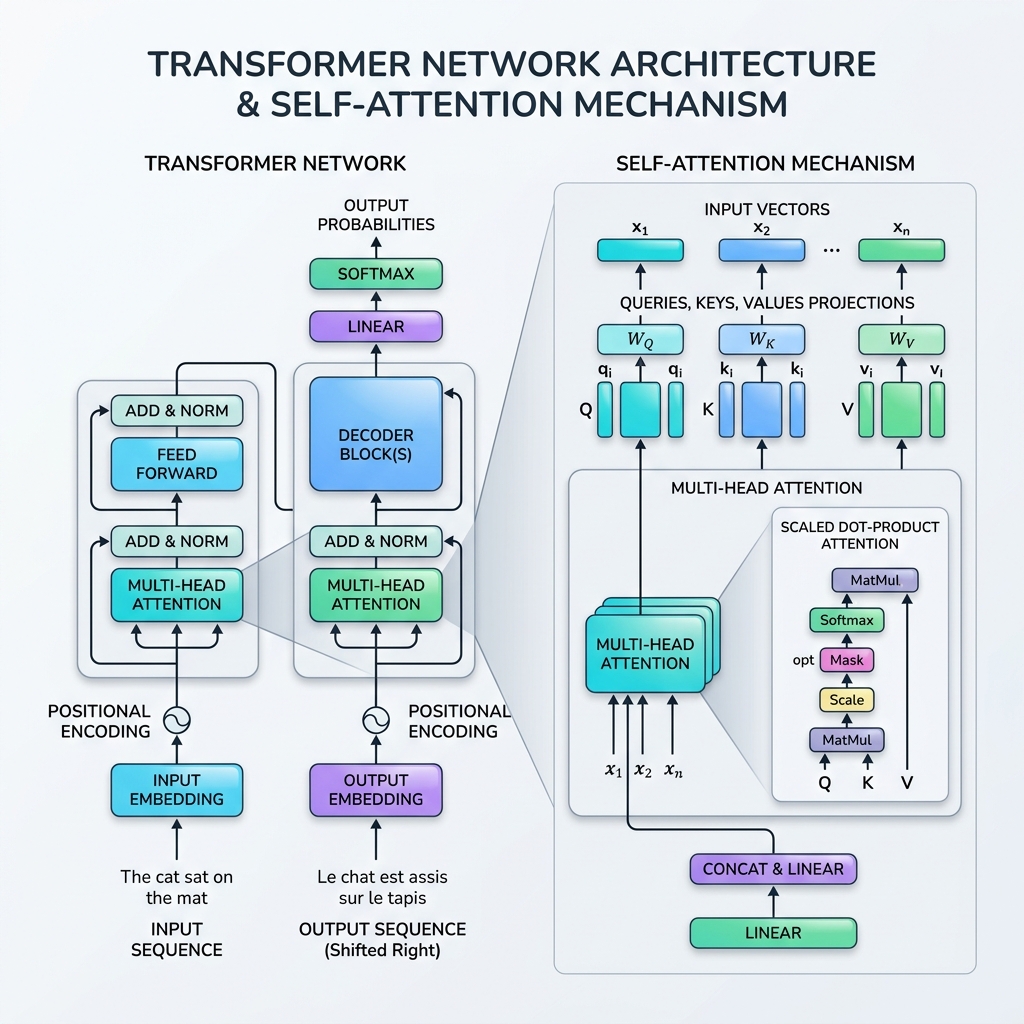
2017年、Vaswaniらによるマイルストーン的な論文 “Attention Is All You Need” の発表によって、人工知能の地平は永遠に塗り替えられました。この論文は、従来の再帰型構造(RNN、LSTM)を完全に排除し、自己アテンション(Self-Attention)メカニズムを用いてシーケンスデータを並列処理する、革命的なニューラルネットワークアーキテクチャ Transformer を提案しました。
今日、Transformer は GPT-4、Gemini、Claude、Llama をはじめとする、ほぼすべての最先端の大規模言語モデル(LLM)の原動力となっています。このブログでは、Transformer ネットワークの仕組みを紐解き、自己アテンションメカニズムが数学的および実践的にどのように実装されているかを解説します。
1. 順次処理のボトルネック(RNN と Transformer の比較)
Transformer 以前は、リカレントニューラルネットワーク(RNN)や長短期記憶(LSTM)ネットワークがシーケンスモデリング의 標準でした。しかし、RNNはトークンを順次(1単語ずつ)処理します。10番目の単語の隠れ状態を計算するためには、モデルはまず1番目から9番目までの単語の隠れ状態を計算しなければなりません。
この順次処理の性質は、2つの深刻な制限をもたらします。
- 並列化の欠如: 計算が前のステップの完了を待つ必要があるため、現代のGPUを効率的に活用できません。
- 勾配消失・爆発問題: 長いシーケンスの初期の情報は、モデルが終端に達するまでに圧縮され、失われてしまいます(ボトルネック問題)。
Transformer はこれら両方の問題を解決します。再帰を Self-Attention に置き換えることで、Transformer は入力シーケンス全体を同時に処理し、大規模な並列化と、距離に関係なくシーケンス内の任意の2つのトークン間の直接的な結合経路を可能にします。
2. 自己アテンション(Self-Attention)メカニズムとは?
自己アテンションは、同じシーケンス内の異なる単語間の関係性をモデルが評価できるようにする仕組みです。単語を単独で処理するのではなく、文中の他のすべての単語からコンテキストを取り入れることで、各単語を表現します。
例えば、次の文章を考えてみましょう。
- “The bank of the river was muddy."(川の土手は泥だらけだった。)
- “The money was deposited in the bank."(お金は銀行に預けられた。)
「bank」という単語は、文脈によって異なる意味を持ちます。自己アテンションにより、モデルは最初の文では「river(川)」を、2番目の文では「money(お金)」を見ることで、「bank」の表現を正しく調整できます。
データベースのアナロジー:クエリ(Q)、キー(K)、値(V)
自己アテンションの数学的定式化は、情報検索(データベース)のルックアップをモデルにしています。各入力トークンについて、3つのベクトル表現を投影します。
- クエリ (Query, $Q$): 現在のトークンが「探している」もの。
- キー (Key, $K$): シーケンス内のトークンの「ラベル」またはプロファイル。
- 値 (Value, $V$): トークンの実際のコンテンツまたは情報。
アテンションメカニズムは、Query とすべての Keys の間の類似度スコアを計算し、これらのスコアを重みに正規化して、Values の加重和を返します。
3. スケールド・ドットプロダクト・アテンションの数学的ステップ
自己アテンションの標準的な数式は、**スケールド・ドットプロダクト・アテンション(Scaled Dot-Product Attention)**と呼ばれます。
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
この数式がどのように実行されるか、数学的ステップを順に追っていきましょう。
ステップ1: 投影行列の計算
入力シーケンス行列 $X \in \mathbb{R}^{T \times d_{\text{model}}}$ に対し、学習可能な重み行列 $W_Q, W_K, W_V$ を掛け合わせて、Queries ($Q$)、Keys ($K$)、Values ($V$) を得ます。 $$Q = X W_Q, \quad K = X W_K, \quad V = X W_V$$
ステップ2: 類似度スコアの計算(内積)
クエリ行列 $Q$ とキー行列の転置 $K^T$ の内積を計算し、すべてのトークンペア間の生の適合度・関連度を測定します。 $$\text{Scores} = QK^T$$ 得られる行列の次元は $T \times T$ であり、要素 $(i, j)$ はトークン $i$ がトークン $j$ にどれだけ注意を払うべきかを表します。
ステップ3: スコアの変倍(スケーリング)
スコアをキーの次元数($d_k$)の平方根で割ります。 $$\text{Scaled Scores} = \frac{QK^T}{\sqrt{d_k}}$$ なぜスケーリングするのか? $d_k$ が大きい場合、内積の大きさは非常に大きくなり、softmax 関数を勾配が極端に小さい領域に押し込んでしまいます(勾配消失問題)。$\sqrt{d_k}$ で割ることで、トレーニングプロセスが安定します。
ステップ4: Softmax の適用(アテンション重み)
各行に softmax 関数を適用して、スコアを確率分布(0から1の間の値で、合計が1になる)に正規化します。 $$\text{Attention Weights} = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)$$
ステップ5: 値の加重和
最後に、アテンション重みに値行列 $V$ を掛けます。 $$\text{Output} = \text{Attention Weights} \times V$$ このステップで情報が統合され、各トークンの出力表現は、それが「注意を払った」トークンから強い影響を受けるようになります。
4. マルチヘッドアテンション(Multi-Head Attention)
自己アテンションを1回だけ行う代わりに、Transformer はマルチヘッドアテンションを使用します。これは、Query、Key、Value ベクトルを $h$ 個のより小さな次元(ヘッド)に分割し、それぞれのサブスペースで独立して並列にアテンションを計算し、最後に結果を結合します。
これにより、モデルが異なる種類の関係性に同時に注意を払うことができるため、極めて重要です。例えば、あるヘッドは主語と動詞の一致に焦点を当て、別のヘッドは代名詞の指示対象の解決や時間の言及に焦点を当てることができます。
5. アテンションメカニズムの Python/NumPy 実装
実装を理解するために、NumPy を使用して、スケールド・ドットプロダクト・アテンションとマルチヘッドアテンションのシンプルで自己完結した Python シミュレーションを書いてみましょう。
import numpy as np
def softmax(x):
# オーバーフローを避けるための安定化 softmax
exp_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return exp_x / np.sum(exp_x, axis=-1, keepdims=True)
def scaled_dot_product_attention(Q, K, V, mask=None):
"""
Scaled Dot-Product Attention を計算します。
Q: [batch_size, seq_len, d_k]
K: [batch_size, seq_len, d_k]
V: [batch_size, seq_len, d_v]
mask: オプションのバイナリマスク [batch_size, seq_len, seq_len]
"""
d_k = Q.shape[-1]
# ステップ2 & 3: 内積の計算とスケーリング
scores = np.matmul(Q, K.swapaxes(-2, -1)) / np.sqrt(d_k)
# オプションのマスキング(例: デコーダーにおける因果関係マスク)
if mask is not None:
scores = np.where(mask == 0, -1e9, scores)
# ステップ4: softmax を適用してアテンション重みを得る
attention_weights = softmax(scores)
# ステップ5: 値の加重和
output = np.matmul(attention_weights, V)
return output, attention_weights
# --- 実行例 ---
if __name__ == "__main__":
np.random.seed(42)
batch_size = 1
seq_len = 4
d_k = 8
d_v = 8
# ランダムな Query、Key、Value ベクトルを生成
Q = np.random.randn(batch_size, seq_len, d_k)
K = np.random.randn(batch_size, seq_len, d_k)
V = np.random.randn(batch_size, seq_len, d_v)
output, weights = scaled_dot_product_attention(Q, K, V)
print("アテンション重み行列 (シーケンス長 x シーケンス長):")
print(np.round(weights[0], 4))
print("\nAttention Output Shape:", output.shape)
6. アーキテクチャの比較
| 機能 | RNN / LSTM | Transformer |
|---|---|---|
| 順次処理 | あり (トークンごと) | なし (並列シーケンス) |
| 計算複雑性 | 順次 $O(T)$ | 順次 $O(1)$、総操作 $O(T^2)$ |
| 長期依存関係 | 不得意 (ステップが進むと記憶が消失) | 極めて得意 (距離に関係なく直接結合) |
| 並列化 | 時間軸に沿って不可能 | ネイティブで並列化可能 |
| 位置情報の認識 | 暗黙的 (順次処理ステップに内在) | 明示的 (位置エンコーディングが必要) |
7. Transformer ブロックのその他の構成要素
自己アテンションをフルスタックで機能させるために、Transformer アーキテクチャは各ブロックにいくつかの重要な層を含んでいます。
- 位置エンコーディング(Positional Encoding): Transformer はすべてのトークンを一度に処理するため、本質的に順序の概念がありません。そのため、トークンの順序を表すために、異なる周波数の正弦波および余弦波を用いた位置エンコーディングベクトルを入力埋め込みに直接加算します。
- 残差接続(Residual Connections): 各サブレイヤー(アテンションおよびフィードフォワード)をバイパスするスキップ接続により、非常に深いネットワークでも勾配が消失することなく伝播しやすくなります。
- レイヤー正規化(Layer Normalization): 各層の活性化を正規化し、学習を安定させ、高速化します。
- フィードフォワードネットワーク(FFN): 各トークンに独立して適用される位置ごとの2層のパーセプトロン(MLP)であり、非線形な表現力を追加します。
結論
Transformer による再帰から並列自己アテンションへの転換は、現代のAIの発展の道を開きました。クエリ、キー、および値を理解することで、モデルが概念を動的に結びつけ、リアルタイムで意味を構築する様子を視覚的に理解でき、これが現代のLLMの高度な認知能力の礎となっています。