ट्रांसफार्मर नेटवर्क और सेल्फ-अटेंशन (Self-Attention) तंत्र को समझना
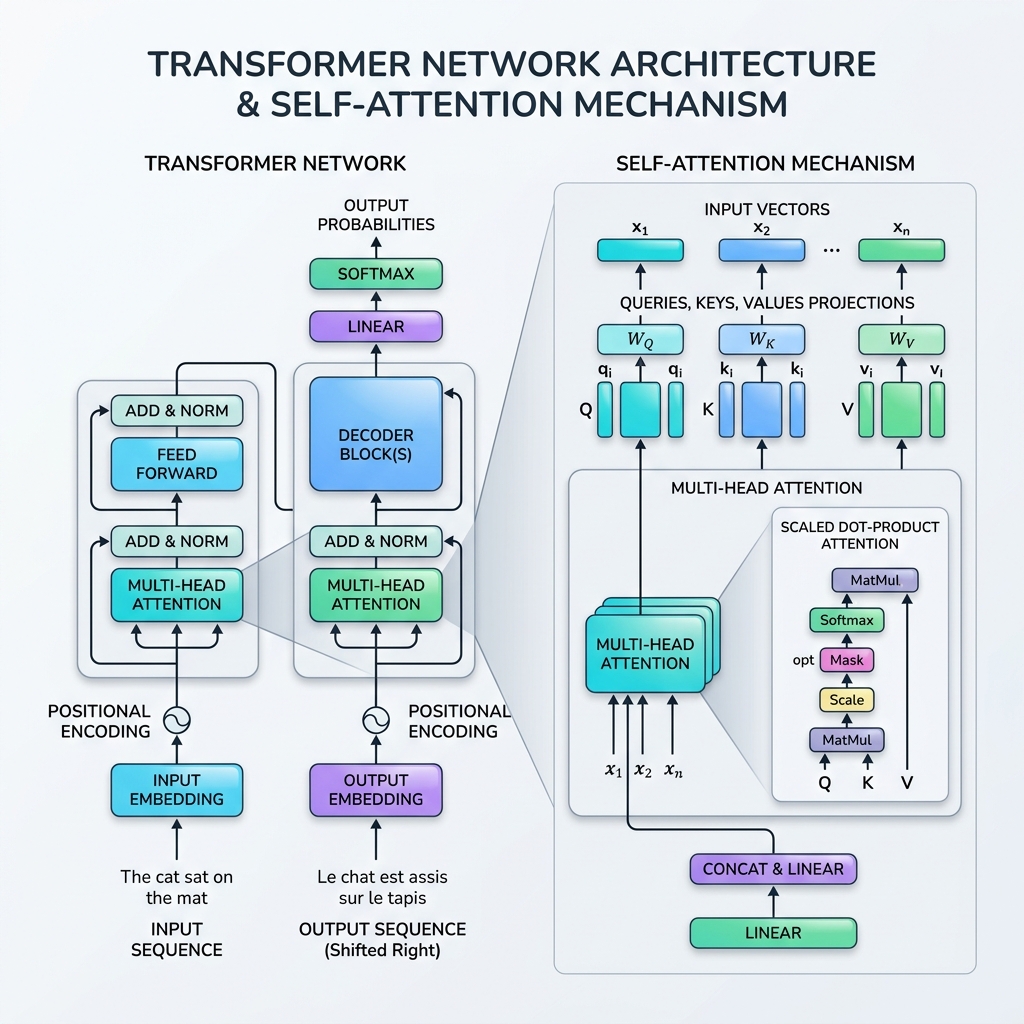
2017 में, वासवानी आदि द्वारा लिखित ऐतिहासिक शोध पत्र “Attention Is All You Need” के प्रकाशन के साथ कृत्रिम बुद्धिमत्ता (AI) का परिदृश्य हमेशा के लिए बदल गया। इस शोध पत्र ने ट्रांसफार्मर (Transformer) को पेश किया, जो एक क्रांतिकारी तंत्रिका नेटवर्क (neural network) आर्किटेक्चर था जिसने पुनरावृत्ति (RNN, LSTM) को पूरी तरह से त्याग दिया, और इसके बजाय सेल्फ-अटेंशन तंत्र (Self-Attention Mechanism) का उपयोग करके क्रमिक डेटा को समानांतर (parallel) रूप से संसाधित करने का विकल्प चुना।
आज, ट्रांसफार्मर लगभग सभी अत्याधुनिक लार्ज लैंग्वेज मॉडल (LLM) को शक्ति प्रदान करते हैं, जिसमें GPT-4, Gemini, Claude और Llama शामिल हैं। यह ब्लॉग ट्रांसफार्मर नेटवर्क की गुत्थी को सुलझाता है और बताता है कि सेल्फ-अटेंशन तंत्र को गणितीय और व्यावहारिक रूप से कैसे लागू किया जाता है।
1. क्रमिक प्रसंस्करण की बाधा (RNN बनाम ट्रांसफार्मर)
ट्रांसफार्मर से पहले, रिकरेंट न्यूरल नेटवर्क (RNN) और लॉन्ग शॉर्ट-टर्म मेमोरी (LSTM) नेटवर्क जैसे मॉडल अनुक्रम मॉडलिंग (sequence modeling) के लिए मानक थे। हालाँकि, RNN टोकन को क्रमिक रूप से संसाधित करते हैं—एक समय में एक शब्द। 10वें शब्द के छिपे हुए स्टेट (hidden state) की गणना करने के लिए, मॉडल को पहले 1 से 9 तक के शब्दों के छिपे हुए स्टेट्स की गणना करनी होगी।
यह क्रमिक प्रकृति दो गंभीर सीमाएं लाती है:
- कोई समानांतरीकरण (Parallelization) नहीं: आधुनिक GPU का कुशलतापूर्वक उपयोग नहीं किया जा सकता है क्योंकि गणनाओं को पिछले चरण के पूरा होने की प्रतीक्षा करनी पड़ती.
- लुप्त होते/विस्फोटक ग्रेडिएंट (Vanishing/Exploding Gradients): जब तक मॉडल अंत तक पहुंचता है, तब तक लंबे अनुक्रम की शुरुआत की जानकारी संकुचित हो जाती है और खो जाती है (अड़चन की समस्या)।
ट्रांसफार्मर इन दोनों समस्याओं का समाधान करते हैं। पुनरावृत्ति को सेल्फ-अटेंशन से बदलकर, एक ट्रांसफार्मर संपूर्ण इनपुट अनुक्रम को एक साथ संसाधित करता है, जिससे बड़े पैमाने पर समानांतरीकरण की अनुमति मिलती है और दूरी की परवाह किए बिना अनुक्रम में किसी भी दो टोकन के बीच सीधा संबंध स्थापित होता है।
2. सेल्फ-अटेंशन (Self-Attention) तंत्र क्या है?
सेल्फ-अटेंशन मॉडल को एक ही अनुक्रम में विभिन्न शब्दों के बीच संबंधों का मूल्यांकन करने की अनुमति देता है। किसी शब्द को अलग से संसाधित करने के बजाय, मॉडल वाक्य के अन्य सभी शब्दों के संदर्भ को लेकर प्रत्येक शब्द का प्रतिनिधित्व करता है।
उदाहरण के लिए, इन वाक्यों में देखें:
- “नदी का बैंक (किनारा) कीचड़ भरा था।”
- “पैसा बैंक में जमा किया गया था।”
शब्द “बैंक” के संदर्भ के आधार पर अलग-अलग अर्थ हैं। सेल्फ-अटेंशन मॉडल को पहले वाक्य में “नदी” और दूसरे वाक्य में “पैसा” को देखने की अनुमति देता है ताकि “बैंक” के प्रतिनिधित्व को सही ढंग से समायोजित किया जा सके।
डेटाबेस सादृश्य: क्वेरी (Queries), कीज़ (Keys), और वैल्यूज़ (Values)
सेल्फ-अटेंशन का गणितीय सूत्रीकरण सूचना पुनर्प्राप्ति (डेटाबेस) लुकअप पर आधारित है। प्रत्येक इनपुट टोकन के लिए, हम तीन वेक्टर निरूपणों को प्रोजेक्ट करते हैं:
- क्वेरी ($Q$): वर्तमान टोकन क्या खोज रहा है।
- की ($K$): अनुक्रम में टोकन का लेबल या प्रोफाइल।
- वैल्यू ($V$): टोकन की वास्तविक सामग्री या जानकारी।
अटेंशन तंत्र एक क्वेरी और सभी कीज़ के बीच एक समानता स्कोर की गणना करता है, इन स्कोर्स को भार (weights) में सामान्यीकृत करता है, और वैल्यूज़ का एक भारित योग देता है।
3. स्केल्ड डॉट-प्रोडक्ट अटेंशन का गणितीय विवरण
सेल्फ-अटेंशन के मानक सूत्र को स्केल्ड डॉट-प्रोडक्ट अटेंशन (Scaled Dot-Product Attention) कहा जाता है:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
यहाँ चरण-दर-चरण गणितीय विवरण दिया गया है कि यह सूत्र कैसे निष्पादित होता है:
चरण 1: प्रोजेक्शन मैट्रिसेस की गणना करें
एक इनपुट अनुक्रम मैट्रिक्स $X \in \mathbb{R}^{T \times d_{\text{model}}}$ के लिए, हम क्वेरी ($Q$), कीज़ ($K$), और वैल्यूज़ ($V$) प्राप्त करने के लिए सीखने योग्य भार मैट्रिसेस $W_Q, W_K, W_V$ से गुणा करते हैं: $$Q = X W_Q, \quad K = X W_K, \quad V = X W_V$$
चरण 2: समानता स्कोर की गणना करें (डॉट उत्पाद)
हम सभी टोकन जोड़ियों के बीच संरेखण/प्रासंगिकता को मापने के लिए क्वेरी मैट्रिक्स $Q$ का की मैट्रिक्स के ट्रांसपोज़ $K^T$ के साथ डॉट उत्पाद (dot product) की गणना करते हैं: $$\text{Scores} = QK^T$$ परिणामी मैट्रिक्स का आयाम $T \times T$ होता है, जहां प्रविष्टि $(i, j)$ दर्शाती है कि टोकन $i$ को टोकन $j$ पर कितना ध्यान देना चाहिए।
चरण 3: स्कोर को स्केल करें
स्कोर को की आयाम ($d_k$) के वर्गमूल से विभाजित किया जाता है: $$\text{Scaled Scores} = \frac{QK^T}{\sqrt{d_k}}$$ स्केल क्यों करें? यदि $d_k$ बड़ा है, तो डॉट उत्पाद परिमाण में बड़े हो जाते हैं, जिससे सॉफ्टमैक्स फ़ंक्शन अत्यधिक छोटे ग्रेडिएंट वाले क्षेत्रों में चला जाता है (लुप्त ग्रेडिएंट समस्या)। $\sqrt{d_k}$ द्वारा स्केल करने से प्रशिक्षण प्रक्रिया स्थिर हो जाती है।
चरण 4: सॉफ्टमैक्स लागू करें (अटेंशन वेट)
हम स्कोर को एक प्रायिकता वितरण (0 और 1 के बीच के मान जिनका योग 1 होता है) में सामान्यीकृत करने के लिए प्रत्येक पंक्ति में सॉफ्टमैक्स फ़ंक्शन लागू करते हैं: $$\text{Attention Weights} = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)$$
चरण 5: वैल्यूज़ का भारित योग
अंत में, हम अटेंशन वेट को वैल्यू मैट्रिक्स $V$ से गुणा करते हैं: $$\text{Output} = \text{Attention Weights} \times V$$ यह चरण जानकारी को एकत्रित करता है, जिससे प्रत्येक टोकन का आउटपुट प्रतिनिधित्व उन टोकन से बहुत अधिक प्रभावित होता है जिन पर उसने “ध्यान” दिया था।
4. मल्टी-हेड अटेंशन (Multi-Head Attention)
सेल्फ-अटेंशन को एक बार करने के बजाय, ट्रांसफार्मर मल्टी-हेड अटेंशन का उपयोग करता है। यह क्वेरी, की, और वैल्यू वेक्टरों को $h$ छोटे आयामों (हेड्स) में विभाजित करता है, प्रत्येक सबस्पेस पर स्वतंत्र रूप से समानांतर में अटेंशन निष्पादित करता है, और फिर परिणामों को आपस में जोड़ता है (concatenate)।
यह महत्वपूर्ण है क्योंकि यह मॉडल को एक साथ विभिन्न प्रकार के संबंधों पर ध्यान देने की अनुमति देता है। उदाहरण के लिए, एक हेड कर्ता-क्रिया समझौते पर ध्यान केंद्रित कर सकता है, जबकि दूसरा हेड सर्वनाम समाधान या समय संदर्भों पर ध्यान केंद्रित कर सकता है।
5. अटेंशन का पाइथन/नमपाई (NumPy) कार्यान्वयन
कार्यान्वयन को समझने के लिए, आइए NumPy का उपयोग करके स्केल्ड डॉट-प्रोडक्ट अटेंशन और अमल करने योग्य सिमुलेशन के लिए पाइथन कोड लिखें:
import numpy as np
def softmax(x):
# ओवरफ़्लो से बचने के लिए स्थिर सॉफ्टमैक्स
exp_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return exp_x / np.sum(exp_x, axis=-1, keepdims=True)
def scaled_dot_product_attention(Q, K, V, mask=None):
"""
स्केल्ड डॉट-प्रोडक्ट अटेंशन की गणना करता है।
Q: [batch_size, seq_len, d_k]
K: [batch_size, seq_len, d_k]
V: [batch_size, seq_len, d_v]
mask: वैकल्पिक बाइनरी मास्क [batch_size, seq_len, seq_len]
"""
d_k = Q.shape[-1]
# चरण 2 और 3: डॉट-उत्पाद और स्केल की गणना करें
scores = np.matmul(Q, K.swapaxes(-2, -1)) / np.sqrt(d_k)
# वैकल्पिक मास्किंग (जैसे डिकोडर में कॉज़ल मास्किंग)
if mask is not None:
scores = np.where(mask == 0, -1e9, scores)
# चरण 4: अटेंशन वेट प्राप्त करने के लिए सॉफ्टमैक्स लागू करें
attention_weights = softmax(scores)
# चरण 5: वैल्यूज़ का भारित योग
output = np.matmul(attention_weights, V)
return output, attention_weights
# --- निष्पादन उदाहरण ---
if __name__ == "__main__":
np.random.seed(42)
batch_size = 1
seq_len = 4
d_k = 8
d_v = 8
# यादृच्छिक क्वेरी, की, और वैल्यू वेक्टर उत्पन्न करें
Q = np.random.randn(batch_size, seq_len, d_k)
K = np.random.randn(batch_size, seq_len, d_k)
V = np.random.randn(batch_size, seq_len, d_v)
output, weights = scaled_dot_product_attention(Q, K, V)
print("अटेंशन वेट मैट्रिक्स (अनुक्रम लंबाई x अनुक्रम लंबाई):")
print(np.round(weights[0], 4))
print("\nAttention Output Shape:", output.shape)
6. आर्किटेक्चरल तुलना
| विशेषता | RNN / LSTM | ट्रांसफार्मर |
|---|---|---|
| क्रमिक प्रसंस्करण | हाँ (टोकन-दर-टोकन) | नहीं (समानांतर अनुक्रम) |
| गणितीय जटिलता | $O(T)$ क्रमिक | $O(1)$ क्रमिक, $O(T^2)$ कुल संचालन |
| दीर्घकालिक निर्भरताएँ | खराब (स्मृति चरणों के साथ समाप्त हो जाती है) | उत्कृष्ट (दूरी की परवाह किए बिना सीधा संबंध) |
| समानांतरीकरण | समय अक्ष के साथ असंभव | मूल समानांतर क्षमता |
| पोजिशनल जागरूकता | अंतर्निहित (क्रमिक चरणों में स्वतः होती है) | स्पष्ट (पोजिशनल एनकोडिंग की आवश्यकता होती है) |
7. अतिरिक्त ट्रांसफार्मर ब्लॉक घटक
सेल्फ-अटेंशन को पूरे स्टैक में काम करने के लिए, ट्रांसफार्मर आर्किटेक्चर में प्रत्येक ब्लॉक में कई महत्वपूर्ण परतें शामिल होती हैं:
- पोजिशनल एनकोडिंग (Positional Encoding): चूंकि ट्रांसफार्मर सभी टोकन को एक साथ संसाधित करते हैं, इसलिए उनमें क्रम की कोई अंतर्निहित भावना नहीं होती है। हम टोकन क्रम को दर्शाने के लिए इनपुट एम्बेडिंग में सीधे पोजिशनल एनकोडिंग वेक्टर (अलग-अलग आवृत्तियों की साइन और कोसाइन तरंगों का उपयोग करके) जोड़ते हैं।
- रेसिड्यूअल कनेक्शंस (Residual Connections): प्रत्येक सब-लेयर (अटेंशन और फीड-फॉरवर्ड) के चारों ओर स्किप-कनेक्शन ग्रेडिएंट्स को बिना लुप्त हुए बहुत गहरे नेटवर्क के माध्यम से प्रसारित करने में मदद करते हैं।
- लेयर नॉर्मलाइजेशन (Layer Normalization): प्रत्येक परत के एक्टिवेशन को सामान्य करता है, जिससे प्रशिक्षण स्थिर और तेज़ होता है।
- फीड-फॉरवर्ड नेटवर्क (FFN): प्रत्येक टोकन पर स्वतंत्र रूप से लागू एक पोजिशन-वाइज MLP, जो गैर-रेखीय प्रतिनिधित्व क्षमता जोड़ता है।
निष्कर्ष
पुनरावृत्ति से समानांतर सेल्फ-अटेंशन की ओर ट्रांसफार्मर के बदलाव ने आधुनिक एआई के स्केलिंग नियमों के द्वार खोल दिए। क्वेरी, कीज़, और वैल्यूज़ को समझकर, हम देख सकते हैं कि कैसे मॉडल वास्तविक समय में अवधारणाओं को गतिशील रूप से जोड़ सकते हैं और अर्थ का निर्माण कर सकते हैं, जिससे आधुनिक LLM की संज्ञानात्मक क्षमताओं की नींव रखी जा सकी।