Comprensión de las Redes Transformer y el Mecanismo de Self-Attention
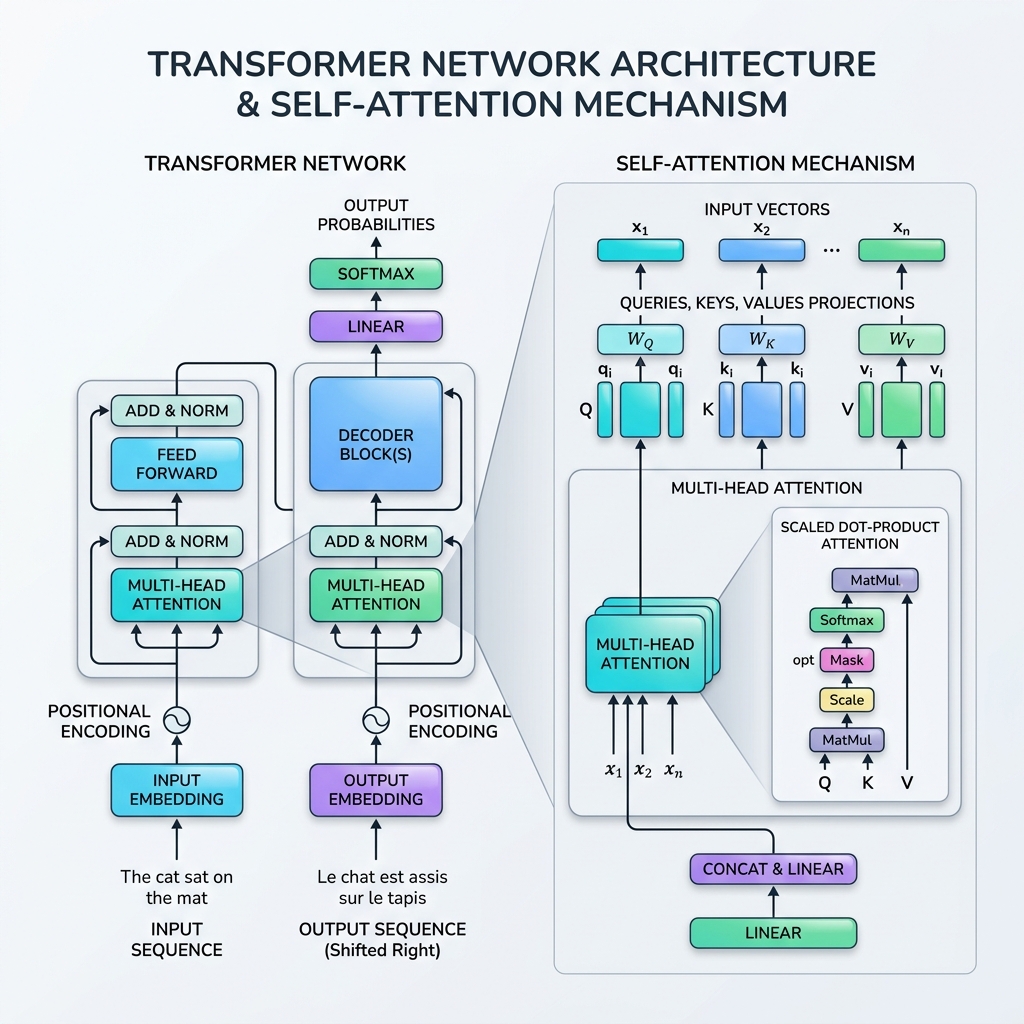
En 2017, el panorama de la inteligencia artificial cambió para siempre con la publicación del influyente artículo “Attention Is All You Need” por Vaswani et al. El artículo introdujo el Transformer, una revolucionaria arquitectura de red neuronal que descartó por completo la recurrencia (RNN, LSTM), optando en su lugar por procesar datos secuenciales en paralelo utilizando el Mecanismo de Self-Attention (Autoatención).
Hoy en día, los Transformers impulsan casi todos los modelos de lenguaje grande (LLM) de última generación, incluidos GPT-4, Gemini, Claude y Llama. Este blog desmitifica la red Transformer y explica cómo se implementa el mecanismo de self-attention matemática y prácticamente.
1. El cuello de botella del procesamiento secuencial (RNN frente a Transformer)
Antes de los Transformers, los modelos como las redes neuronales recurrentes (RNN) y las redes de memoria a corto y largo plazo (LSTM) eran el estándar para el modelado de secuencias. Sin embargo, las RNN procesan los tokens de forma secuencial, una palabra a la vez. Para calcular el estado oculto de la décima palabra, el modelo primero debe calcular los estados ocultos de las palabras 1 a 9.
Esta naturaleza secuencial introduce dos graves limitaciones:
- Sin paralelización: Las GPU modernas no se pueden utilizar de manera eficiente porque los cálculos deben esperar a que se complete el paso anterior.
- Gradientes que se desvanecen o explotan: La información del principio de una secuencia larga se comprime y se pierde cuando el modelo llega al final (el problema del cuello de botella).
Los Transformers resuelven ambos problemas. Al reemplazar la recurrencia con la Self-Attention, un Transformer procesa toda la secuencia de entrada simultáneamente, lo que permite una paralelización masiva y una ruta directa entre dos tokens cualesquiera en una secuencia, independientemente de la distancia.
2. ¿Qué es el mecanismo de Self-Attention?
La self-attention permite al modelo evaluar la relación entre diferentes palabras en la misma secuencia. En lugar de procesar una palabra de forma aislada, el modelo representa cada palabra tomando el contexto de todas las demás palabras de la oración.
Para lograrlo, en las oraciones:
- “El banco de arena estaba caliente.”
- “El dinero fue depositado en el banco.”
La palabra “banco” tiene diferentes significados según el contexto. La self-attention permite al modelo mirar “arena” en la primera oración y “dinero” en la segunda para ajustar correctamente la representación de “banco”.
La analogía de la base de datos: Queries, Keys y Values
La formulación matemática de la self-attention se modela a partir de las búsquedas de recuperación de información (bases de datos). Para cada token de entrada, proyectamos tres representaciones vectoriales:
- Query ($Q$): Lo que busca el token actual.
- Key ($K$): La etiqueta o perfil de los tokens en la secuencia.
- Value ($V$): El contenido o información real de los tokens.
El mecanismo de atención calcula una puntuación de similitud entre una Query y todas las Keys, normaliza estas puntuaciones en pesos y devuelve una suma ponderada de los Values.
3. Tutorial matemático de Scaled Dot-Product Attention
La fórmula estándar para la self-attention se llama Scaled Dot-Product Attention:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
Aquí está el desglose matemático paso a paso de cómo se ejecuta esta fórmula:
Paso 1: Calcular las matrices de proyección
Para una matriz de secuencia de entrada $X \in \mathbb{R}^{T \times d_{\text{model}}}$, multiplicamos por matrices de peso entrenables $W_Q, W_K, W_V$ para obtener las Queries ($Q$), Keys ($K$) y Values ($V$): $$Q = X W_Q, \quad K = X W_K, \quad V = X W_V$$
Paso 2: Calcular las puntuaciones de similitud (producto punto)
Calculamos el producto punto de la matriz Query $Q$ con la transpuesta de la matriz Key $K^T$ para medir la alineación/relevancia bruta entre todos los pares de tokens: $$\text{Scores} = QK^T$$ La matriz resultante tiene dimensiones $T \times T$, donde la entrada $(i, j)$ representa cuánta atención debe prestar el token $i$ al token $j$.
Paso 3: Escalar las puntuaciones
Las puntuaciones se dividen por la raíz cuadrada de la dimensión de la clave ($d_k$): $$\text{Scaled Scores} = \frac{QK^T}{\sqrt{d_k}}$$ ¿Por qué escalar? Si $d_k$ es grande, los productos punto crecen mucho en magnitud, empujando la función softmax a regiones con gradientes extremadamente pequeños (problema del gradiente desvanecido). Escalar por $\sqrt{d_k}$ estabiliza el proceso de entrenamiento.
Paso 4: Aplicar Softmax (pesos de atención)
Aplicamos una función softmax a lo largo de cada fila para normalizar las puntuaciones en una distribución de probabilidad (valores entre 0 y 1 que suman 1): $$\text{Attention Weights} = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)$$
Paso 5: Suma ponderada de Values
Finalmente, multiplicamos los pesos de atención por la matriz Value $V$: $$\text{Output} = \text{Attention Weights} \times V$$ Este paso agrega la información, lo que permite que la representación de salida de cada token esté fuertemente influenciada por los tokens a los que “prestó atención”.
4. Multi-Head Attention
En lugar de realizar la self-attention una vez, el Transformer utiliza Multi-Head Attention (Atención multicabezal). Divide los vectores Query, Key y Value en $h$ dimensiones más pequeñas (cabezales), realiza la atención en cada subespacio de forma independiente en paralelo y luego concatena los resultados.
Esto es crítico porque permite al modelo atender a diferentes tipos de relaciones simultáneamente. Por ejemplo, un cabezal puede centrarse en la concordancia sujeto-verbo, mientras que otro se centra en la resolución de pronombres o referencias temporales.
5. Implementación Python/NumPy de Attention
Para comprender la implementación, escribamos una simulación simple y autónoma en Python de Scaled Dot-Product Attention y Multi-Head Attention usando NumPy:
import numpy as np
def softmax(x):
# Softmax estabilizado para evitar desbordamiento
exp_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return exp_x / np.sum(exp_x, axis=-1, keepdims=True)
def scaled_dot_product_attention(Q, K, V, mask=None):
"""
Computa Scaled Dot-Product Attention.
Q: [batch_size, seq_len, d_k]
K: [batch_size, seq_len, d_k]
V: [batch_size, seq_len, d_v]
mask: Máscara binaria opcional [batch_size, seq_len, seq_len]
"""
d_k = Q.shape[-1]
# Pasos 2 y 3: Calcular producto punto y escalar
scores = np.matmul(Q, K.swapaxes(-2, -1)) / np.sqrt(d_k)
# Enmascaramiento opcional (por ejemplo, enmascaramiento causal en decodificadores)
if mask is not None:
scores = np.where(mask == 0, -1e9, scores)
# Paso 4: Aplicar softmax para obtener pesos de atención
attention_weights = softmax(scores)
# Paso 5: Suma ponderada de values
output = np.matmul(attention_weights, V)
return output, attention_weights
# --- Ejemplo de ejecución ---
if __name__ == "__main__":
np.random.seed(42)
batch_size = 1
seq_len = 4
d_k = 8
d_v = 8
# Generar vectores aleatorios de Query, Key y Value
Q = np.random.randn(batch_size, seq_len, d_k)
K = np.random.randn(batch_size, seq_len, d_k)
V = np.random.randn(batch_size, seq_len, d_v)
output, weights = scaled_dot_product_attention(Q, K, V)
print("Matriz de pesos de atención (Longitud de secuencia x Longitud de secuencia):")
print(np.round(weights[0], 4))
print("\nForma de la salida de atención:", output.shape)
6. Comparación arquitectónica
| Característica | RNN / LSTM | Transformer |
|---|---|---|
| Procesamiento secuencial | Sí (token por token) | No (secuencia paralelizada) |
| Complejidad computacional | $O(T)$ secuencial | $O(1)$ secuencial, $O(T^2)$ operaciones totales |
| Dependencias de largo alcance | Deficiente (la memoria se desvanece en los pasos) | Excelente (enlace directo independientemente de la distancia) |
| Paralelización | Imposible a lo largo del eje del tiempo | Paralelización nativa |
| Conciencia posicional | Implícita (inherente al paso secuencial) | Explícita (requere codificación posicional) |
7. Componentes adicionales del bloque Transformer
Para que la self-attention funcione en una pila completa, la arquitectura Transformer incluye varias capas cruciales en cada bloque:
- Positional Encoding: Dado que los Transformers procesan todos los tokens a la vez, no tienen un sentido de orden inherente. Inyectamos vectores de codificación posicional directamente en las incrustaciones de entrada para representar el orden de los tokens.
- Residual Connections: Las conexiones directas alrededor de cada subcapa (Atención y Feed-Forward) ayudan a que los gradientes se propaguen a través de redes muy profundas sin desvanecerse.
- Layer Normalization: Normaliza las activaciones de cada capa, estabilizando y acelerando el entrenamiento.
- Feed-Forward Networks (FFN): Un MLP de posición aplicado a cada token de forma independiente, agregando capacidad de representación no lineal.
Conclusión
El cambio del Transformer de la recurrencia a la self-attention paralelizada desbloqueó las leyes de escala de la IA moderna. Al comprender las queries, keys y values, vemos cómo los modelos pueden vincular conceptos dinámicamente y construir significado en tiempo real, sentando las bases para las capacidades cognitivas de los LLM modernos.