理解 Transformer 网络与自注意力(Self-Attention)机制
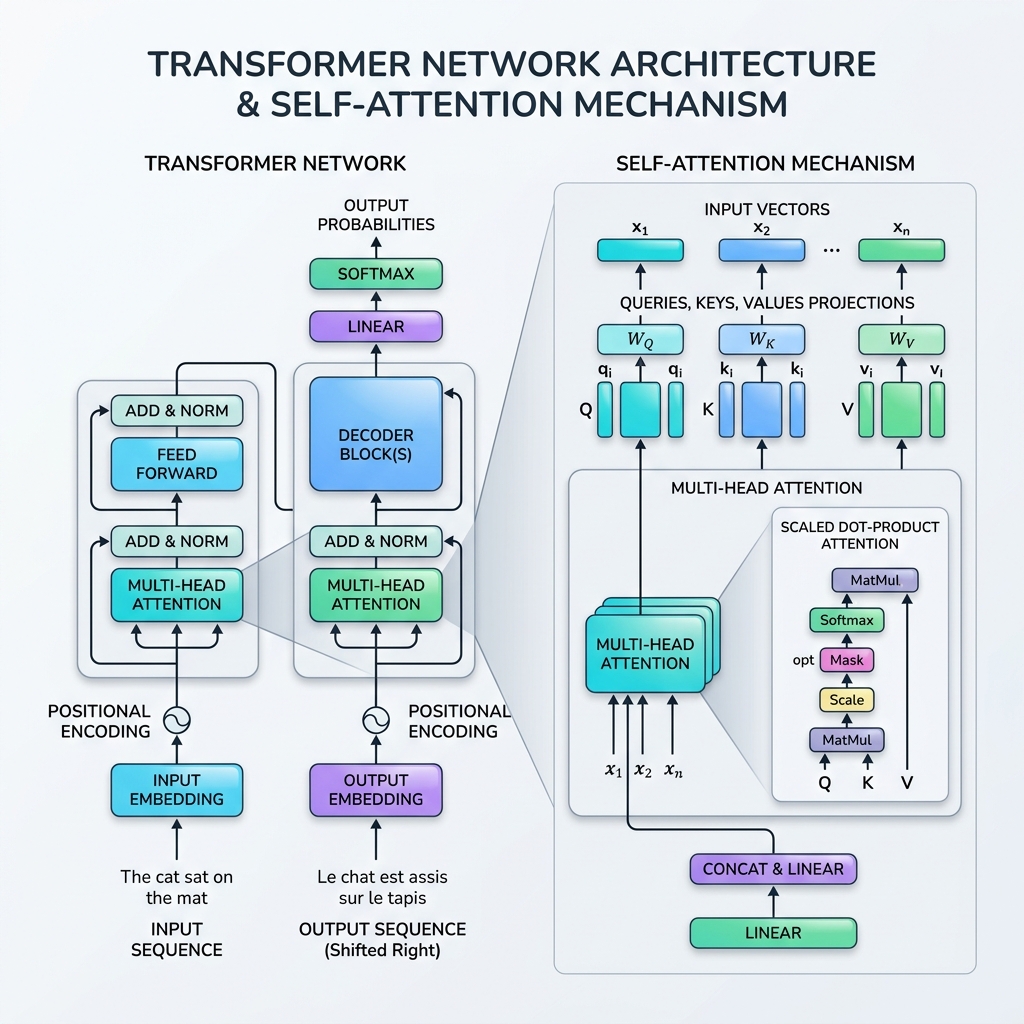
2017年,随着 Vaswani 等人发表了里程碑式的论文 《Attention Is All You Need》,人工智能领域发生了翻天覆地的变化。该论文引入了 Transformer,一种革命性的神经网络架构,它完全摒弃了循环结构(RNN、LSTM),转而使用**自注意力机制(Self-Attention Mechanism)**并行处理序列数据。
如今,Transformer 驱动着几乎所有最先进的大语言模型(LLM),包括 GPT-4、Gemini, Claude 和 Llama。本篇博客将揭开 Transformer 网络的神秘面纱,并从数学和实践的角度解析自注意力机制是如何实现的。
1. 串行处理的瓶颈(RNN 与 Transformer 的对比)
在 Transformer 出现之前,循环神经网络(RNN)和长短期记忆(LSTM)网络是序列建模的标准方法。然而,RNN 必须按顺序(一次处理一个词)处理 Token。为了计算第 10 个词的隐藏状态,模型必须先计算第 1 到第 9 个词的隐藏状态。
这种串行特性带来了两个严重的局限性:
- 无法并行化: 现代 GPU 的计算能力无法得到高效利用,因为每一步计算都必须等待上一步完成。
- 梯度消失/爆炸: 当模型处理到长序列的末尾时,序列开头的早期信息会被压缩并丢失(即瓶颈问题)。
Transformer 同时解决了这两个问题。通过用自注意力取代循环结构,Transformer 可以同时处理整个输入序列,实现了海量的并行化计算,并在序列中的任意两个 Token 之间建立直接联系,无论它们相距多远。
2. 什么是自注意力机制?
自注意力允许模型评估同一序列中不同词之间的关系。模型不再孤立地处理每个词,而是通过结合句子中所有其他词的上下文来表示当前词。
例如在以下句子中:
- “The bank of the river was muddy.”(河岸很泥泞。)
- “The money was deposited in the bank.”(钱存进了银行。)
单词“bank”根据上下文具有不同的含义。自注意力机制使模型能够在第一个句子中关注“river”(河流),在第二个句子中关注“money”(金钱),从而正确调整“bank”的特征表示。
数据库类比:查询(Queries)、键(Keys)和值(Values)
自注意力的数学表述模仿了信息检索(数据库)的查找过程。对于每个输入 Token,我们将其映射为三个向量表示:
- 查询(Query, $Q$): 当前 Token 正在“寻找”什么。
- 键(Key, $K$): 序列中各个 Token 的“标签”或特征概况。
- 值(Value, $V$): 各个 Token 包含的实际内容或信息。
自注意力机制计算 Query 与所有 Keys 之间的相似度得分,将 these 得分归一化为权重,然后返回 Values 的加权和。
3. 缩放点积注意力(Scaled Dot-Product Attention)数学解析
自注意力的标准公式被称为缩放点积注意力:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
以下是该公式执行的逐步数学分解:
第一步:计算投影矩阵
对于输入序列矩阵 $X \in \mathbb{R}^{T \times d_{\text{model}}}$,我们将其与可学习的权重矩阵 $W_Q, W_K, W_V$ 相乘,得到查询($Q$)、键($K$)和值($V$): $$Q = X W_Q, \quad K = X W_K, \quad V = X W_V$$
第二步:计算相似度得分(点积)
我们将查询矩阵 $Q$ 与键矩阵的转置 $K^T$ 进行点积,以测量所有 Token 对之间的原始对齐程度/相关性: $$\text{Scores} = QK^T$$ 得到的矩阵维度为 $T \times T$,其中位置 $(i, j)$ 表示 Token $i$ 应该对 Token $j$ 投入多少注意力。
第三步:缩放得分
将得分除以键维度($d_k$)的平方根: $$\text{Scaled Scores} = \frac{QK^T}{\sqrt{d_k}}$$ 为什么要缩放? 如果 $d_k$ 很大,点积的值在量级上会变得非常大,从而将 softmax 函数推向梯度极小的区域(梯度消失问题)。除以 $\sqrt{d_k}$ 可以使训练过程更加稳定。
第四步:应用 Softmax(注意力权重)
我们在每行上应用 softmax 函数,将得分归一化为概率分布(值在 0 到 1 之间,且每行之和为 1): $$\text{Attention Weights} = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)$$
第五步:Values 的加权和
最后,我们将注意力权重与值矩阵 $V$ 相乘: $$\text{Output} = \text{Attention Weights} \times V$$ 这一步将信息进行整合,使每个 Token 的输出表示能够深受其所“关注”的那些 Token 的影响。
4. 多头注意力机制(Multi-Head Attention)
Transformer 并不只进行一次自注意力计算,而是使用多头注意力。它将 Query、Key 和 Value 向量分割到 $h$ 个更小维度的子空间(称为“头”),在每个子空间中并行、独立地进行注意力计算,最后将所有头的输出拼接起来。
这至关重要,因为它允许模型同时关注不同类型的关系。例如,一个头可能专注于主谓一致,而另一个头专注于代词指代消解或时间关联。
5. 注意力机制的 Python/NumPy 实现
为了更好地理解其实现过程,让我们用 NumPy 编写一个简单且自包含的缩放点积注意力和多头注意力的 Python 模拟代码:
import numpy as np
def softmax(x):
# 稳定的 softmax,防止溢出
exp_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return exp_x / np.sum(exp_x, axis=-1, keepdims=True)
def scaled_dot_product_attention(Q, K, V, mask=None):
"""
计算缩放点积注意力。
Q: [batch_size, seq_len, d_k]
K: [batch_size, seq_len, d_k]
V: [batch_size, seq_len, d_v]
mask: 可选的二进制掩码 [batch_size, seq_len, seq_len]
"""
d_k = Q.shape[-1]
# 第二和第三步:计算点积并缩放
scores = np.matmul(Q, K.swapaxes(-2, -1)) / np.sqrt(d_k)
# 可选的 Mask 掩码操作(例如解码器中的因果掩码)
if mask is not None:
scores = np.where(mask == 0, -1e9, scores)
# 第四步:应用 softmax 获得注意力权重
attention_weights = softmax(scores)
# 第五步:特征值的加权和
output = np.matmul(attention_weights, V)
return output, attention_weights
# --- 执行示例 ---
if __name__ == "__main__":
np.random.seed(42)
batch_size = 1
seq_len = 4
d_k = 8
d_v = 8
# 生成随机的 Query、Key 和 Value 向量
Q = np.random.randn(batch_size, seq_len, d_k)
K = np.random.randn(batch_size, seq_len, d_k)
V = np.random.randn(batch_size, seq_len, d_v)
output, weights = scaled_dot_product_attention(Q, K, V)
print("注意力权重矩阵 (序列长度 x 序列长度):")
print(np.round(weights[0], 4))
print("\n注意力输出维度:", output.shape)
6. 架构对比
| 特性 | RNN / LSTM | Transformer |
|---|---|---|
| 串行处理 | 是(逐个 Token 处理) | 否(并行序列处理) |
| 计算复杂度 | 串行 $O(T)$ | 串行 $O(1)$,总操作 $O(T^2)$ |
| 长距离依赖 | 较差(记忆随着步数增加而衰减) | 极佳(无论距离多远均能直接关联) |
| 并行化能力 | 在时间轴上无法并行 | 原生支持并行化 |
| 位置感知 | 隐式(蕴含在串行步骤中) | 显式(需要位置编码) |
7. Transformer 块的其他核心组件
为了使自注意力在完整网络中发挥作用,Transformer 架构在每个块中还包含了以下关键层:
- 位置编码(Positional Encoding): 由于 Transformer 一次性处理所有 Token,它本身没有顺序概念。我们直接在输入嵌入中注入位置编码向量(利用不同频率的正弦和余弦波)来表征 Token 的顺序。
- 残差连接(Residual Connections): 围绕每个子层(注意力层 and 前馈网络)的跳跃连接,有助于梯度在极深的网络中传播而不会发生消失。
- 层归一化(Layer Normalization): 归一化每个层的激活值,稳定并加速训练过程。
- 前馈网络(Feed-Forward Networks, FFN): 独立应用于每个 Token 的逐位置双层感知机(MLP),增加了非线性表达能力。
结论
Transformer 从循环结构向并行自注意力的转变,释放了现代 AI 的扩展定律。通过理解查询、键和值,我们可以直观看到模型如何在实时计算中动态关联概念并构建语义,这为现代 LLM 的认知能力奠定了坚实基石。