Понимание сетей Transformer и механизма Self-Attention
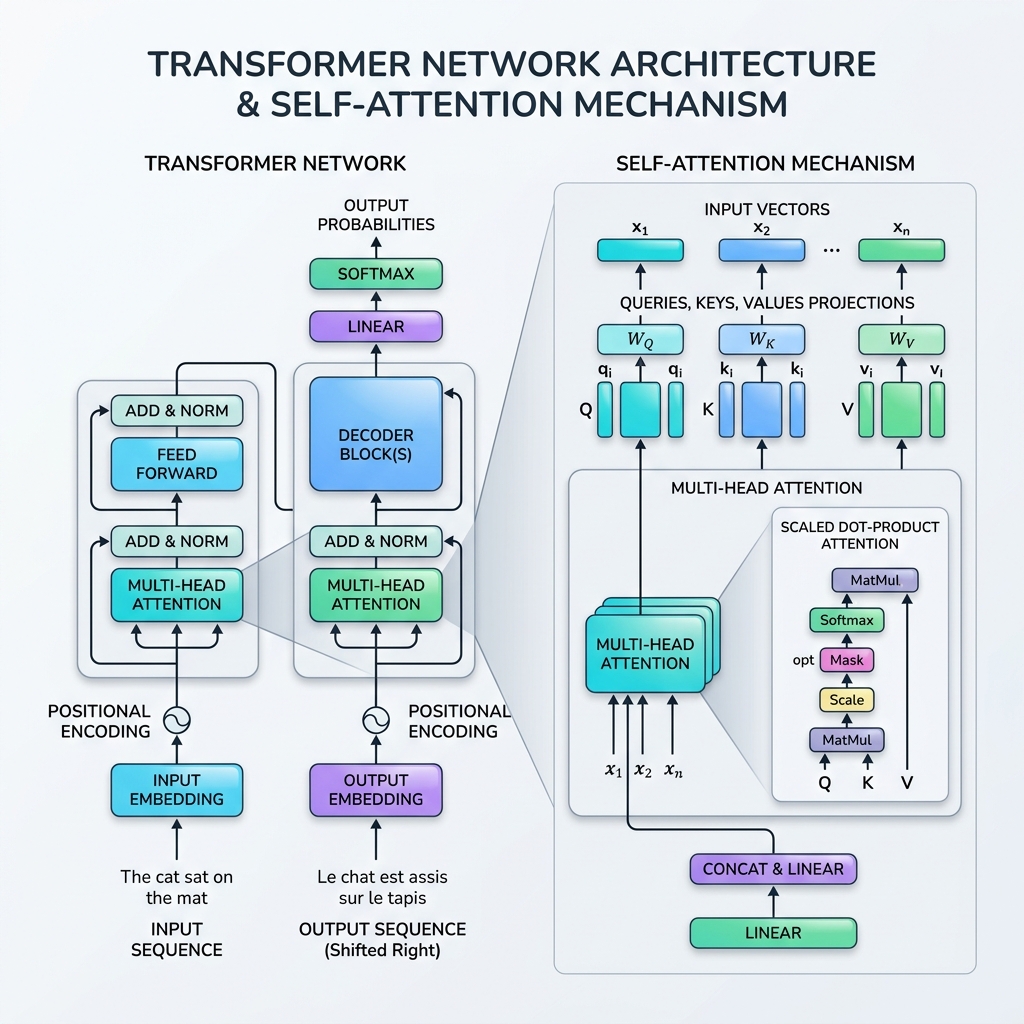
В 2017 году ландшафт искусственного интеллекта изменился навсегда после публикации фундаментальной работы «Attention Is All You Need» команды исследователей под руководством Vaswani. В работе была представлена архитектура Transformer — революционная архитектура нейронных сетей, которая полностью отказалась от рекуррентности (RNN, LSTM), сделав выбор в пользу параллельной обработки последовательностей данных с использованием Механизма Self-Attention (самовнимания).
Сегодня архитектура Transformer лежит в основе практически всех передовых больших языковых моделей (LLM), включая GPT-4, Gemini, Claude и Llama. В этой статье мы раскроем устройство сетей Transformer и математические основы реализации механизма самовнимания.
1. Проблема узкого места последовательной обработки (RNN против Transformer)
До появления моделей Transformer стандартом для моделирования последовательностей были рекуррентные нейронные сети (RNN) и сети долгой краткосрочной памяти (LSTM). Однако RNN обрабатывают токены последовательно — по одному слову за раз. Чтобы вычислить скрытое состояние для десятого слова, модель должна сначала вычислить скрытые состояния для слов с первого по девятое.
Эта последовательная природа накладывает два серьезных ограничения:
- Невозможность параллелизации: Современные графические процессоры (GPU) не могут использоваться эффективно, поскольку вычисления должны ожидать завершения предыдущего шага.
- Затухание/взрыв градиентов: Информация из начала длинной последовательности сжимается и теряется к моменту, когда модель достигает конца (проблема узкого места).
Архитектура Transformer решает обе проблемы. Заменяя рекуррентность механизмом Self-Attention, модель Transformer обрабатывает всю входную последовательность одновременно, что обеспечивает колоссальную параллелизацию и прямую связь между любыми двумя токенами в последовательности независимо от расстояния.
2. Что такое механизм Self-Attention?
Механизм самовнимания (Self-attention) позволяет модели оценивать взаимосвязи между различными словами в одной и той же последовательности. Вместо того чтобы обрабатывать слово изолированно, модель формирует представление каждого слова с учетом контекста всех остальных слов в предложении.
Например, в предложениях:
- «Он сидел на берегу реки и смотрел на песчаный кос.»
- «Девочке заплели красивый кос.»
Слово «кос» (коса) имеет разные значения в зависимости от контекста. Механизм самовнимания позволяет модели обращать внимание на слово «реки» в первом предложении и «девочке» во втором, чтобы правильно скорректировать векторное представление слова «кос».
Аналогия с базами данных: запросы (Queries), ключи (Keys) и значения (Values)
Математическая формулировка самовнимания смоделирована по аналогии с поиском информации в базах данных. Для каждого входного токена мы получаем три векторных представления:
- Запрос ($Q$): То, что ищет текущий токен.
- Ключ ($K$): Метка или профиль токенов в последовательности.
- Значение ($V$): Фактическое содержимое или информация токенов.
Механизм внимания вычисляет оценку сходства между Запросом и всеми Ключами, нормализует эти оценки в веса внимания и возвращает взвешенную сумму Значений.
3. Математическое описание Scaled Dot-Product Attention
Стандартная формула самовнимания называется Scaled Dot-Product Attention (масштабированное внимание на основе скалярного произведения):
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
Ниже приведено пошаговое описание работы этой формулы:
Шаг 1: Вычисление матриц проекции
Для матрицы входной последовательности $X \in \mathbb{R}^{T \times d_{\text{model}}}$, мы умножаем её на обучаемые матрицы весов $W_Q, W_K, W_V$, чтобы получить Запросы ($Q$), Ключи ($K$) и Значения ($V$): $$Q = X W_Q, \quad K = X W_K, \quad V = X W_V$$
Шаг 2: Расчет оценок сходства (скалярное произведение)
Мы вычисляем скалярное произведение матрицы Запросов $Q$ на транспонированную матрицу Ключей $K^T$ для измерения соответствия/релевантности между всеми парами токенов: $$\text{Scores} = QK^T$$ Полученная матрица имеет размерность $T \times T$, где элемент $(i, j)$ показывает, насколько токен $i$ должен быть внимателен к токену $j$.
Шаг 3: Масштабирование оценок
Оценки делятся на квадратный корень из размерности ключей ($d_k$): $$\text{Scaled Scores} = \frac{QK^T}{\sqrt{d_k}}$$ Зачем масштабировать? При больших значениях $d_k$ скалярные произведения сильно возрастают, из-за чего функция softmax попадает в области с экстремально малыми градиентами (проблема затухания градиента). Масштабирование на $\sqrt{d_k}$ стабилизирует процесс обучения.
Шаг 4: Применение Softmax (веса внимания)
Мы применяем функцию softmax к каждой строке, чтобы нормализовать оценки в распределение вероятностей (значения от 0 до 1, сумма которых равна 1): $$\text{Attention Weights} = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)$$
Шаг 5: Взвешенная сумма Значений
Наконец, мы умножаем веса внимания на матрицу Значений $V$: $$\text{Output} = \text{Attention Weights} \times V$$ Этот шаг агрегирует информацию, позволяя выходному представлению каждого токена находиться под сильным влиянием токенов, на которые он «обратил внимание».
4. Multi-Head Attention
Вместо того чтобы выполнять самовнимание один раз, в Transformer используется Multi-Head Attention (многоголовое внимание). Оно разделяет векторы Запросов, Ключей и Значений на $h$ меньших размерностей («голов»), параллельно и независимо вычисляет внимание в каждом подпространстве, а затем конкатенирует результаты.
Это критически важно, так как позволяет модели одновременно обращать внимание на различные типы связей. Например, одна «голова» может фокусироваться на согласовании подлежащего и сказуемого, в то время как другая — на местоименных связях или временных отсылках.
5. Реализация внимания на Python/NumPy
Чтобы лучше понять реализацию, напишем простую симуляцию масштабированного внимания и многоголового внимания на языке Python с использованием библиотеки NumPy:
import numpy as np
def softmax(x):
# Стабилизированный softmax для предотвращения переполнения
exp_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return exp_x / np.sum(exp_x, axis=-1, keepdims=True)
def scaled_dot_product_attention(Q, K, V, mask=None):
"""
Вычисляет Scaled Dot-Product Attention.
Q: [batch_size, seq_len, d_k]
K: [batch_size, seq_len, d_k]
V: [batch_size, seq_len, d_v]
mask: Необязательная бинарная маска [batch_size, seq_len, seq_len]
"""
d_k = Q.shape[-1]
# Шаги 2 и 3: Скалярное произведение и масштабирование
scores = np.matmul(Q, K.swapaxes(-2, -1)) / np.sqrt(d_k)
# Необязательное маскирование (например, каузальная маска в декодерах)
if mask is not None:
scores = np.where(mask == 0, -1e9, scores)
# Шаг 4: Применение softmax для получения весов внимания
attention_weights = softmax(scores)
# Шаг 5: Взвешенная сумма значений
output = np.matmul(attention_weights, V)
return output, attention_weights
# --- Пример выполнения ---
if __name__ == "__main__":
np.random.seed(42)
batch_size = 1
seq_len = 4
d_k = 8
d_v = 8
# Генерация случайных векторов Query, Key и Value
Q = np.random.randn(batch_size, seq_len, d_k)
K = np.random.randn(batch_size, seq_len, d_k)
V = np.random.randn(batch_size, seq_len, d_v)
output, weights = scaled_dot_product_attention(Q, K, V)
print("Матрица весов внимания (Длина последовательности x Длина последовательности):")
print(np.round(weights[0], 4))
print("\nФорма выходного тензора внимания:", output.shape)
6. Сравнение архитектур
| Характеристика | RNN / LSTM | Transformer |
|---|---|---|
| Последовательная обработка | Да (токен за токеном) | Нет (параллельная обработка) |
| Вычислительная сложность | $O(T)$ последовательно | $O(1)$ последовательно, $O(T^2)$ всего операций |
| Длинные зависимости | Плохо (память затухает с шагами) | Отлично (прямая связь независимо от расстояния) |
| Parallelization | Невозможна по оси времени | Нативная параллелизация |
| Позиционное кодирование | Не требуется (встроено в шаги) | Требуется (Positional Encoding) |
7. Дополнительные компоненты блока Transformer
Для полноценной работы самовнимания архитектура Transformer включает в себя несколько важных слоев в каждом блоке:
- Positional Encoding (позиционное кодирование): Поскольку модели Transformer обрабатывают все токены сразу, они не имеют встроенного представления об их порядке. Мы внедряем векторы позиционного кодирования (на основе синусоид и косинусоид различной частоты) непосредственно во входные эмбеддинги.
- Residual Connections (остаточные связи): Сквозные связи вокруг каждого подслоя (внимания и полносвязного слоя) помогают градиентам распространяться через глубокие сети без затухания.
- Layer Normalization (нормализация по слоям): Нормализует активации каждого слоя, стабилизируя и ускоряя обучение.
- Feed-Forward Networks (полносвязные сети): Двухслойный перцептрон (MLP), применяемый к каждому токену независимо и добавляющий нелинейную выразительность.
Заключение
Переход Transformer от рекуррентности к параллельному самовниманию открыл путь к законам масштабирования современного ИИ. Понимание концепции запросов, ключей и значений показывает, как модели могут динамически связывать идеи и конструировать смыслы на лету, закладывая основу для когнитивных способностей современных LLM.