Transformer-Netzwerke und den Self-Attention-Mechanismus verstehen
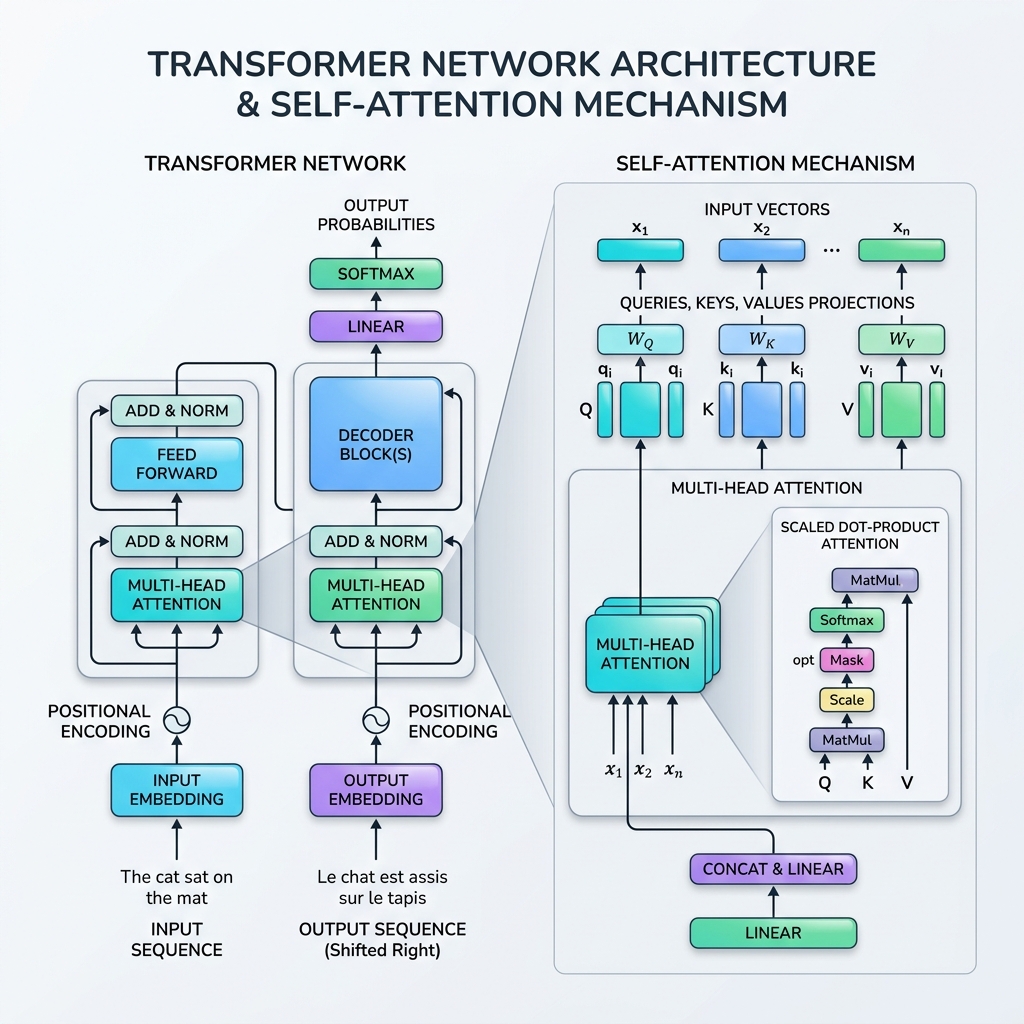
Im Jahr 2017 veränderte sich die Landschaft der künstlichen Intelligenz durch die Veröffentlichung des bahnbrechendenden Papers „Attention Is All You Need“ von Vaswani et al. für immer. Das Paper stellte den Transformer vor, eine revolutionäre neuronale Netzwerkarchitektur, die Rekursion (RNNs, LSTMs) vollständig verwarf und sich stattdessen dafür entschied, sequentielle Daten mithilfe des Self-Attention-Mechanismus parallel zu verarbeiten.
Heute bilden Transformer das Fundament fast aller modernen Large Language Models (LLMs) wie GPT-4, Gemini, Claude und Llama. Dieser Blogbeitrag entmystifiziert das Transformer-Netzwerk und erklärt, wie der Self-Attention-Mechanismus mathematisch und praktisch implementiert wird.
1. Der Engpass sequentieller Verarbeitung (RNNs vs. Transformer)
Vor den Transformern waren Modelle wie Recurrent Neural Networks (RNNs) und Long Short-Term Memory (LSTM) Netzwerke der Standard für die Sequenzmodellierung. RNNs verarbeiten Token jedoch sequentiell – ein Wort nach dem anderen. Um den verborgenen Zustand für das 10. Wort zu berechnen, muss das Modell zuerst die Zustände für die Wörter 1 bis 9 berechnen.
Diese sequentielle Natur bringt zwei gravierende Nachteile mit sich:
- Keine Parallelisierung: Moderne GPUs können nicht effizient ausgelastet werden, da Berechnungen auf den Abschluss des vorherigen Schritts warten müssen.
- Verschwindende/Explodierende Gradienten: Informationen vom Anfang einer langen Sequenz werden komprimiert und gehen verloren, bis das Modell das Ende erreicht (das Bottleneck-Problem).
Transformer lösen beide Probleme. Durch den Ersatz von Rekursion durch Self-Attention verarbeitet ein Transformer die gesamte Eingabesequenz gleichzeitig. Dies ermöglicht eine massive Parallelisierung und einen direkten Pfad zwischen zwei beliebigen Token in einer Sequenz, unabhängig von deren Abstand.
2. Was ist der Self-Attention-Mechanismus?
Self-Attention (Selbstaufmerksamkeit) ermöglicht es dem Modell, die Beziehung zwischen verschiedenen Wörtern in derselben Sequenz zu bewerten. Anstatt ein Wort isoliert zu verarbeiten, repräsentiert das Modell jedes Wort unter Einbeziehung des Kontexts aller anderen Wörter im Satz.
Ein Beispiel in den Sätzen:
- „Die Bank im Park war frisch gestrichen.“
- „Ich habe Geld auf der Bank eingezahlt.“
Das Wort „Bank“ hat je nach Kontext unterschiedliche Bedeutungen. Self-Attention ermöglicht es dem Modell, im ersten Satz auf „Park“ und im zweiten Satz auf „Geld“ zu schauen, um die Repräsentation von „Bank“ korrekt anzupassen.
Die Datenbank-Analogie: Queries, Keys und Values
Die mathematische Formulierung der Self-Attention ist der Informationssuche in Datenbanken nachempfunden. Für jeden Eingabe-Token projizieren wir drei Vektorrepräsentationen:
- Query ($Q$): Wonach der aktuelle Token sucht.
- Key ($K$): Die Bezeichnung oder das Profil der Token in der Sequenz.
- Value ($V$): Der tatsächliche Inhalt oder die Information der Token.
Der Attention-Mechanismus berechnet einen Ähnlichkeitswert zwischen einer Query und allen Keys, normalisiert diese Werte in Gewichte und gibt eine gewichtete Summe der Values zurück.
3. Mathematischer Walkthrough der Scaled Dot-Product Attention
Die Standardformel für Self-Attention wird als Scaled Dot-Product Attention bezeichnet:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
Hier ist die schrittweise mathematische Aufschlüsselung der Formel:
Schritt 1: Berechnung der Projektionsmatrizen
Für eine Eingabesequenzmatrix $X \in \mathbb{R}^{T \times d_{\text{model}}}$ multiplizieren wir mit lernbaren Gewichtsmatrizen $W_Q, W_K, W_V$, um Queries ($Q$), Keys ($K$) und Values ($V$) zu erhalten: $$Q = X W_Q, \quad K = X W_K, \quad V = X W_V$$
Schritt 2: Ähnlichkeitswerte berechnen (Skalarprodukt)
Wir berechnen das Skalarprodukt der Query-Matrix $Q$ mit der transponierten Key-Matrix $K^T$, um die Relevanz zwischen allen Token-Paaren zu messen: $$\text{Scores} = QK^T$$ Die resultierende Matrix hat die Dimensionen $T \times T$, wobei der Eintrag $(i, j)$ angibt, wie viel Aufmerksamkeit Token $i$ dem Token $j$ schenken sollte.
Schritt 3: Skalierung der Werte
Die Werte werden durch die Quadratwurzel der Key-Dimension ($d_k$) dividiert: $$\text{Scaled Scores} = \frac{QK^T}{\sqrt{d_k}}$$ Warum skalieren? Wenn $d_k$ groß ist, wachsen die Skalarprodukte stark an. Dies treibt die Softmax-Funktion in Regionen mit extrem kleinen Gradienten (Problem des verschwindenden Gradienten). Die Skalierung mit $\sqrt{d_k}$ stabilisiert den Trainingsprozess.
Schritt 4: Softmax anwenden (Attention-Gewichte)
Wir wenden eine Softmax-Funktion entlang jeder Zeile an, um die Werte in eine Wahrscheinlichkeitsverteilung zu normalisieren (Werte zwischen 0 und 1, die sich zu 1 aufsummieren): $$\text{Attention Gewichte} = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)$$
Schritt 5: Gewichtete Summe der Values
Schließlich multiplizieren wir die Attention-Gewichte mit der Value-Matrix $V$: $$\text{Output} = \text{Attention Gewichte} \times V$$ Dieser Schritt aggregiert die Informationen und ermöglicht es, dass die Output-Repräsentation jedes Tokens stark von den Token beeinflusst wird, auf die es sich bezogen hat.
4. Multi-Head Attention
Anstatt Self-Attention nur einmal durchzuführen, verwendet der Transformer Multi-Head Attention (Mehrkopf-Aufmerksamkeit). Dabei werden Query-, Key- und Value-Vektoren in $h$ kleinere Dimensionen (Heads/Köpfe) aufgeteilt, die Attention in jedem Subraum unabhängig und parallel berechnet und die Ergebnisse anschließend verkettet.
Dies ist entscheidend, da es dem Modell ermöglicht, sich gleichzeitig auf verschiedene Arten von Beziehungen zu konzentrieren. Beispielsweise kann sich ein Kopf auf die Subjekt-Verb-Kongruenz konzentrieren, während ein anderer Kopf Pronomen-Bezüge oder zeitliche Referenzen analysiert.
5. Python/NumPy-Implementierung von Attention
Um die Implementierung zu verstehen, schreiben wir eine einfache, in sich geschlossene Python-Simulation der Scaled Dot-Product Attention und Multi-Head Attention mit NumPy:
import numpy as np
def softmax(x):
# Stabilisiertes Softmax zur Vermeidung von Überlauf
exp_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return exp_x / np.sum(exp_x, axis=-1, keepdims=True)
def scaled_dot_product_attention(Q, K, V, mask=None):
"""
Berechnet die Scaled Dot-Product Attention.
Q: [batch_size, seq_len, d_k]
K: [batch_size, seq_len, d_k]
V: [batch_size, seq_len, d_v]
mask: Optionaler binärer Masken-Vektor [batch_size, seq_len, seq_len]
"""
d_k = Q.shape[-1]
# Schritt 2 & 3: Skalarprodukt berechnen und skalieren
scores = np.matmul(Q, K.swapaxes(-2, -1)) / np.sqrt(d_k)
# Optionales Maskieren (z. B. Kausale Maskierung in Decodern)
if mask is not None:
scores = np.where(mask == 0, -1e9, scores)
# Schritt 4: Softmax anwenden, um Attention-Gewichte zu erhalten
attention_weights = softmax(scores)
# Schritt 5: Gewichtete Summe der Values
output = np.matmul(attention_weights, V)
return output, attention_weights
# --- Ausführungsbeispiel ---
if __name__ == "__main__":
np.random.seed(42)
batch_size = 1
seq_len = 4
d_k = 8
d_v = 8
# Zufällige Query-, Key- und Value-Vektoren generieren
Q = np.random.randn(batch_size, seq_len, d_k)
K = np.random.randn(batch_size, seq_len, d_k)
V = np.random.randn(batch_size, seq_len, d_v)
output, weights = scaled_dot_product_attention(Q, K, V)
print("Attention-Gewichtsmatrix (Sequenzlänge x Sequenzlänge):")
print(np.round(weights[0], 4))
print("\nAttention Output Shape:", output.shape)
6. Architektonischer Vergleich
| Merkmal | RNN / LSTM | Transformer |
|---|---|---|
| Sequentielle Verarbeitung | Ja (Token für Token) | Nein (parallelisierte Sequenz) |
| Berechnungskomplexität | $O(T)$ sequentiell | $O(1)$ sequentiell, $O(T^2)$ Gesamtoperationen |
| Langfristige Abhängigkeiten | Schlecht (Gedächtnis schwindet) | Exzellent (direkte Verbindung unabhängig von Distanz) |
| Parallelisierung | Unmöglich entlang der Zeitachse | Native Parallelisierung |
| Positionsbewusstsein | Implizit (durch sequentiellen Schritt) | Explizit (erfordert Positionskodierung) |
7. Weitere Komponenten eines Transformer-Blocks
Damit Self-Attention in einem vollständigen Stack funktioniert, enthält die Transformer-Architektur in jedem Block mehrere wichtige Schichten:
- Positional Encoding: Da Transformer alle Token auf einmal verarbeiten, haben sie kein eingebautes Gefühl für Reihenfolge. Wir fügen Positionskodierungsvektoren (mit Sinus- und Kosinuswellen verschiedener Frequenzen) direkt in die Eingabebettungen ein, um die Token-Reihenfolge darzustellen.
- Residual Connections: Skip-Connections um jede Teilschicht (Attention und Feed-Forward) helfen den Gradienten, sich ohne Verschwinden durch sehr tiefe Netzwerke auszubreiten.
- Layer Normalization: Normalizes die Aktivierungen jeder Schicht, was das Training stabilisiert und beschleunigt.
- Feed-Forward Networks (FFN): Ein positionsweises MLP, das unabhängig auf jeden Token angewendet wird und nicht-lineare Repräsentationskapazität hinzufügt.
Fazit
Die Abkehr des Transformers von der Rekursion hin zur parallelisierten Self-Attention legte das Fundament für die Skalierungsgesetze moderner KI. Durch das Verständnis von Queries, Keys und Values sehen wir, wie Modelle Konzepte dynamisch verknüpfen und Bedeutung in Echtzeit konstruieren – der Grundstein für die kognitiven Fähigkeiten moderner LLMs.
Entdecken Sie weitere technische Einblicke im Ghaznix-Blog →