درک شبکههای ترنسفورمر و مکانیزم خودتوجهی (Self-Attention)
در سال ۲۰۱۷، چشمانداز هوش مصنوعی با انتشار مقاله جریانساز “Attention Is All You Need” توسط واسوانی و همکارانش برای همیشه تغییر کرد. این مقاله ترنسفورمر (Transformer) را معرفی کرد؛ یک معماری انقلابی در شبکههای عصبی که تکرار (RNNs, LSTMs) را به طور کامل کنار گذاشت و در عوض، پردازش موازی دادههای متوالی را با استفاده از مکانیزم خودتوجهی (Self-Attention Mechanism) ترجیح داد.
امروزه، ترنسفورمرها قدرتبخش تقریباً تمامی مدلهای زبانی بزرگ (LLMs) پیشرو از جمله GPT-4، Gemini، Claude و Llama هستند. این وبلاگ به ابهامزدایی از شبکه ترنسفورمر پرداخته و نحوه پیادهسازی ریاضی و عملی مکانیزم خودتوجهی را توضیح میدهد.
۱. گلگاه پردازش متوالی (RNNها در مقابل ترنسفورمرها)
قبل از ترنسفورمرها, مدلهایی مانند شبکههای عصبی بازگشتی (RNN) و شبکههای حافظه طولانی کوتاهمدت (LSTM) استاندارد مدلسازی توالی بودند. با این حال، RNNها توکنها را به صورت متوالی (یک کلمه در هر زمان) پردازش میکنند. برای محاسبه حالت پنهان (hidden state) برای کلمه دهم، مدل باید ابتدا حالتهای پنهان کلمههای اول تا نهم را محاسبه کند.
این ماهیت متوالی دو محدودیت شدید ایجاد میکند:
- عدم امکان موازیسازی: پردازندههای گرافیکی (GPUs) مدرن را نمیتوان به طور کارآمد استفاده کرد زیرا محاسبات باید منتظر بمانند تا مرحله قبلی کامل شود.
- محو شدن/انفجار گرادیانها (Vanishing/Exploding Gradients): اطلاعات ابتدای یک توالی طولانی تا زمانی که مدل به پایان توالی برسد، فشرده شده و از دست میرود (مشکل گلگاه).
ترنسفورمرها هر دو مشکل را حل میکنند. با جایگزینی تکرار با خودتوجهی، یک ترنسفورمر کل توالی ورودی را به طور همزمان پردازش میکند که امکان موازیسازی عظیم و مسیر مستقیم بین هر دو توکن در توالی را بدون توجه به فاصله آنها فراهم میسازد.
۲. مکانیزم خودتوجهی چیست؟
خودتوجهی (Self-attention) به مدل اجازه میدهد تا رابطه بین کلمات مختلف را در یک توالی ارزیابی کند. مدل به جای پردازش یک کلمه به صورت جداگانه، هر کلمه را با گرفتن بافت و زمینه از تمام کلمات دیگر در جمله نشان میدهد.
به عنوان مثال در جملات زیر:
- “او روی نیمکت پارک نشسته بود.”
- “پرونده در دادگاه روی نیمکت ذخیره قرار گرفت.”
کلمه “نیمکت” با توجه به بافت جمله معانی متفاوتی دارد. خودتوجهی به مدل اجازه میدهد تا در جمله اول به “پارک” و در جمله دوم به “دادگاه” نگاه کند تا نمایش کلمه “نیمکت” را به درستی تنظیم کند.
تشبیه پایگاه داده: پرسوجوها (Queries)، کلیدها (Keys) و مقادیر (Values)
فرمولبندی ریاضی خودتوجهی بر اساس جستجوهای بازیابی اطلاعات (پایگاه داده) مدلسازی شده است. برای هر توکن ورودی، ما سه نمایش برداری را به دست میآوریم:
- پرسوجو ($Q$ - Query): آنچه توکن فعلی به دنبال آن است.
- کلید ($K$ - Key): برچسب یا نمایه توکنها در توالی.
- مقدار ($V$ - Value): محتوا یا اطلاعات واقعی توکنها.
مکانیزم توجه امتیاز شباهت بین یک پرسوجو و تمامی کلیدها را محاسبه میکند، این امتیازها را به صورت وزن نرمالسازی میکند و مجموع وزنی مقادیر را بازمیگرداند.
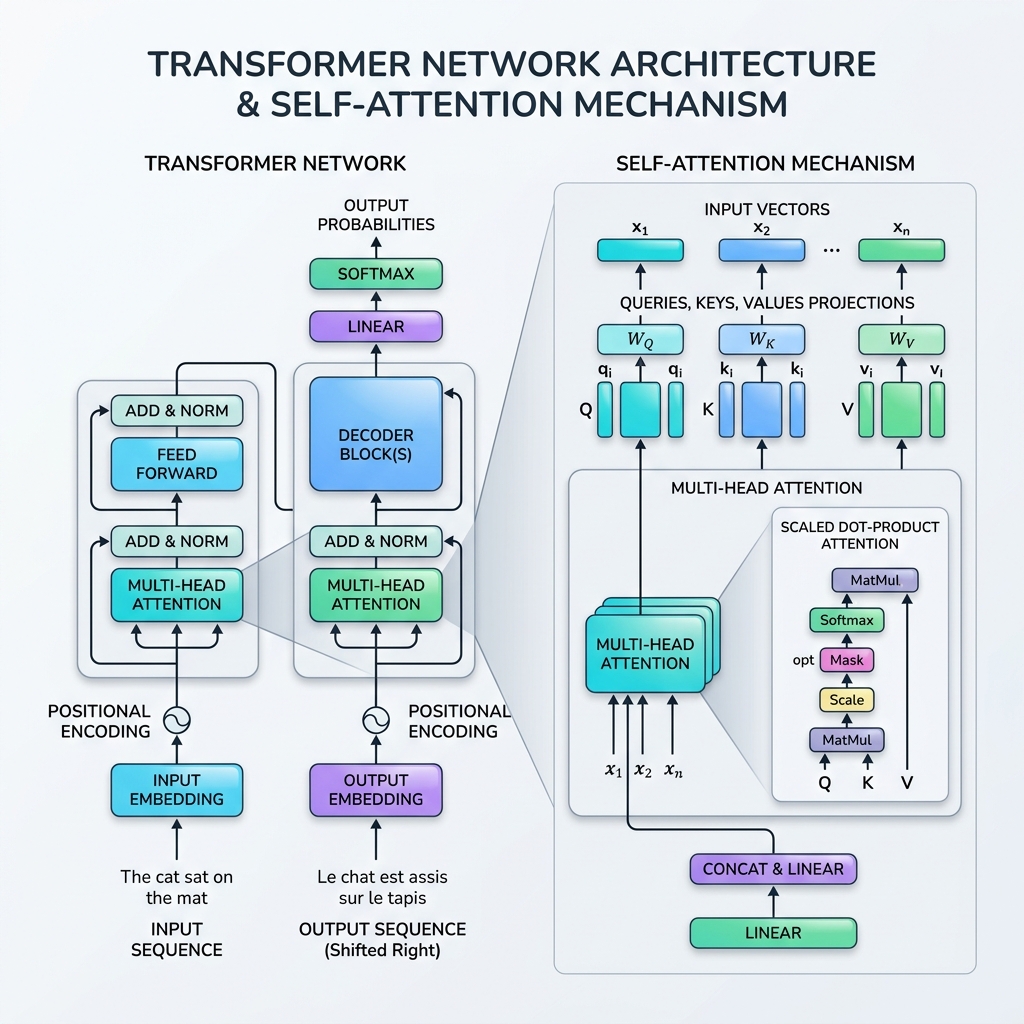
۳. مراحل ریاضی Scaled Dot-Product Attention
فرمول استاندارد خودتوجهی Scaled Dot-Product Attention (توجه ضرب نقطهای مقیاسشده) نامیده میشود:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
در اینجا تجزیه و تحلیل گام به گام ریاضی نحوه اجرای این فرمول آورده شده است:
گام ۱: محاسبه ماتریسهای تصویر
برای ماتریس توالی ورودی $X \in \mathbb{R}^{T \times d_{\text{model}}}$, ما آن را در ماتریسهای وزنی قابل یادگیری $W_Q، W_K، W_V$ ضرب میکنیم تا پرسوجوها ($Q$)، کلیدها ($K$) و مقادیر ($V$) را به دست آوریم: $$Q = X W_Q, \quad K = X W_K, \quad V = X W_V$$
گام ۲: محاسبه امتیازهای شباهت (ضرب نقطهای)
ما ضرب نقطهای ماتریس پرسوجوی $Q$ را در ترانهاده ماتریس کلید $K^T$ محاسبه میکنیم تا میزان همترازی/ارتباط خام بین تمامی جفتهای توکن را اندازهگیری کنیم: $$\text{Scores} = QK^T$$ ماتریس حاصل دارای ابعاد $T \times T$ است، جایی که درایه $(i, j)$ نشان میدهد که توکن $i$ چقدر باید به توکن $j$ توجه کند.
گام ۳: مقیاسگذاری امتیازها
امتیازها بر جذر بعد کلید ($d_k$) تقسیم میشوند: $$\text{Scaled Scores} = \frac{QK^T}{\sqrt{d_k}}$$ چرا مقیاسگذاری؟ اگر $d_k$ بزرگ باشد، مقادیر ضرب نقطهای بسیار بزرگ میشوند که این امر تابع softmax را به مناطقی با گرادیانهای بسیار کوچک سوق میدهد (مشکل محو شدن گرادیان). مقیاسگذاری با $\sqrt{d_k}$ فرآیند آموزش را پایدار میکند.
گام ۴: اعمال Softmax (وزنهای توجه)
ما یک تابع softmax را در طول هر سطر اعمال میکنیم تا امتیازها را به توزیع احتمالی (مقادیری بین ۰ و ۱ که مجموع آنها برابر ۱ است) نرمالسازی کنیم: $$\text{Attention Weights} = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)$$
گام ۵: مجموع وزنی مقادیر
در نهایت، وزنهای توجه را در ماتریس مقادیر $V$ ضرب میکنیم: $$\text{Output} = \text{Attention Weights} \times V$$ این مرحله اطلاعات را جمعآوری میکند و اجازه میدهد نمایش خروجی هر توکن به شدت تحت تأثیر توکنهایی قرار گیرد که به آنها “توجه” کرده است.
۴. توجه چندسر (Multi-Head Attention)
ترنسفورمر به جای اینکه خودتوجهی را یک بار انجام دهد، از توجه چندسر استفاده میکند. این مکانیزم بردارهای پرسوجو، کلید و مقدار را به $h$ بعد کوچکتر (سرها) تقسیم میکند، توجه را در هر زیرفضا به طور مستقل و موازی انجام میدهد و سپس نتایج را به هم متصل (concatenate) میکند.
این ویژگی حیاتی است زیرا به مدل اجازه میدهد به طور همزمان به انواع مختلف روابط توجه کند. به عنوان مثال، یک سر ممکن است روی تطابق فاعل و فعل تمرکز کند، در حالی که سر دیگر روی مرجع ضمیر یا ارجاعات زمانی متمرکز باشد.
۵. پیادهسازی مکانیزم توجه با Python/NumPy
برای درک بهتر پیادهسازی، بیایید یک شبیهسازی ساده و مستقل در پایتون برای Scaled Dot-Product Attention و Multi-Head Attention با استفاده از NumPy بنویسیم:
import numpy as np
def softmax(x):
# سافتمکس پایدار برای جلوگیری از سرریز
exp_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return exp_x / np.sum(exp_x, axis=-1, keepdims=True)
def scaled_dot_product_attention(Q, K, V, mask=None):
"""
Scaled Dot-Product Attention را محاسبه میکند.
Q: [batch_size, seq_len, d_k]
K: [batch_size, seq_len, d_k]
V: [batch_size, seq_len, d_v]
mask: ماسک باینری اختیاری [batch_size, seq_len, seq_len]
"""
d_k = Q.shape[-1]
# گام ۲ و ۳: محاسبه ضرب نقطهای و مقیاسگذاری
scores = np.matmul(Q, K.swapaxes(-2, -1)) / np.sqrt(d_k)
# اعمال ماسک اختیاری (به عنوان مثال ماسک علّی در ردیابها)
if mask is not None:
scores = np.where(mask == 0, -1e9, scores)
# گام ۴: اعمال softmax برای دریافت وزنهای توجه
attention_weights = softmax(scores)
# گام ۵: مجموع وزنی مقادیر
output = np.matmul(attention_weights, V)
return output, attention_weights
# --- نمونه اجرا ---
if __name__ == "__main__":
np.random.seed(42)
batch_size = 1
seq_len = 4
d_k = 8
d_v = 8
# تولید بردارهای تصادفی Query، Key و Value
Q = np.random.randn(batch_size, seq_len, d_k)
K = np.random.randn(batch_size, seq_len, d_k)
V = np.random.randn(batch_size, seq_len, d_v)
output, weights = scaled_dot_product_attention(Q, K, V)
print("ماتریس وزنهای توجه (طول توالی x طول توالی):")
print(np.round(weights[0], 4))
print("\nAttention Output Shape:", output.shape)
۶. مقایسه معماریها
| ویژگی | RNN / LSTM | ترنسفورمر |
|---|---|---|
| پردازش متوالی | بله (توکن به توکن) | خیر (توالی موازیسازی شده) |
| پیچیدگی محاسباتی | متوالی $O(T)$ | متوالی $O(1)$، مجموع عملیات $O(T^2)$ |
| وابستگیهای طولانیمدت | ضعیف (حافظه با گامها محو میشود) | عالی (پیوند مستقیم بدون توجه به فاصله) |
| موازیسازی | غیرممکن در امتداد محور زمان | موازیسازی بومی |
| آگاهی از موقعیت | ضمنی (ذاتی در گامهای متوالی) | صریح (نیاز به Positional Encoding) |
۷. اجزای اضافی بلوک ترنسفورمر
برای اینکه خودتوجهی در یک پشته کامل کار کند، معماری ترنسفورمر شامل چندین لایه حیاتی در هر بلوک است:
- کدگذاری موقعیت (Positional Encoding): از آنجا که ترنسفورمرها همه توکنها را به طور همزمان پردازش میکنند، هیچ حس ذاتی از ترتیب ندارند. ما بردارهای کدگذاری موقعیت (با استفاده از موجهای سینوسی و کسینوسی با فرکانسهای مختلف) را مستقیماً به جاسازیهای ورودی اضافه میکنیم تا ترتیب توکنها را نشان دهیم.
- اتصالات باقیمانده (Residual Connections): اتصالات میانبر در اطراف هر زیرلایه (توجه و پیشرو) به گرادیانها کمک میکنند تا بدون محو شدن در شبکههای بسیار عمیق منتشر شوند.
- نرمالسازی لایه (Layer Normalization): فعالسازیهای هر لایه را نرمالسازی میکند که باعث پایداری و تسریع آموزش میشود.
- شبکههای پیشرو (FFN): یک MLP موقعیتمحور که به طور مستقل روی هر توکن اعمال میشود و ظرفیت نمایش غیرخطی را اضافه میکند.
نتیجهگیری
تغییر ترنسفورمر از تکرار به خودتوجهی موازی، قوانین مقیاسگذاری هوش مصنوعی مدرن را فعال کرد. با درک پرسوجوها، کلیدها و مقادیر، میبینیم که چگونه مدلها میتوانند مفاهیم را به صورت پویا پیوند دهند و معنا را در زمان واقعی بسازند و پایهای را برای تواناییهای شناختی LLMهای مدرن ایجاد کنند.