Transformer 네트워크와 셀프 어텐션(Self-Attention) 메커니즘의 이해
2017년, Vaswani 등이 발표한 기념비적인 논문 **“Attention Is All You Need”**에 의해 인공지능 연구 지형은 영원히 바뀌었습니다. 이 논문은 순환 신경망(RNN, LSTM)과 같은 재귀적 구조를 완전히 배제하고, 대신 셀프 어텐션(Self-Attention) 메커니즘을 사용하여 시퀀스 데이터를 병렬로 처리하는 혁신적인 신경망 아키텍처인 Transformer를 도입했습니다.
오늘날 Transformer는 GPT-4, Gemini, Claude, Llama를 포함한 거의 모든 최첨단 대규모 언어 모델(LLM)의 핵심 동력입니다. 이 블로그에서는 Transformer 네트워크의 작동 방식을 명쾌하게 밝히고 셀프 어텐션 메커니즘이 수학적 및 실무적으로 어떻게 구현되는지 설명합니다.
1. 순차적 처리의 병목 현상 (RNN vs. Transformer)
Transformer 이전에는 순환 신경망(RNN)과 장단기 메모(LSTM) 네트워크가 시퀀스 모델링의 표준이었습니다. 그러나 RNN은 토큰을 한 번에 하나씩 순차적으로 처리합니다. 10번째 단어의 은닉 상태를 계산하려면 모델이 먼저 1번째부터 9번째 단어까지의 은닉 상태를 차례로 계산해야만 합니다.
이러한 순차적 특성은 다음과 같은 치명적인 한계를 가집니다.
- 병렬화 불가능: 계산이 이전 단계의 완료를 기다려야 하므로 현대의 GPU 자원을 효율적으로 활용할 수 없습니다.
- 그레이디언트 소실/폭주: 긴 시퀀스에서 앞부분의 정보는 모델이 끝에 도달할 때쯤이면 압축되어 소실됩니다(병목 문제).
Transformer는 이 두 가지 문제를 모두 해결합니다. 재귀를 Self-Attention으로 대체함으로써 Transformer는 입력 시퀀스 전체를 동시에 처리하므로 대규모 병렬화가 가능하고, 시퀀스 내의 두 토큰 사이의 거리에 관계없이 직접적인 연결 경로를 제공합니다.
2. 셀프 어텐션(Self-Attention) 메커니즘이란 무엇인가요?
셀프 어텐션은 모델이 동일한 시퀀스 내의 서로 다른 단어 간의 관계를 평가할 수 있도록 합니다. 단어를 개별적으로 처리하는 대신 문장 내 다른 모든 단어의 컨텍스트를 통합하여 각 단어를 표현합니다.
예를 들어 다음 문장에서:
- “The bank of the river was muddy."(강둑은 진흙투성이였다.)
- “The money was deposited in the bank."(돈이 은행에 입금되었다.)
단어 “bank“는 문맥에 따라 서로 다른 의미를 가집니다. 셀프 어텐션을 사용하면 모델이 첫 번째 문장에서는 “river”(강)를, 두 번째 문장에서는 “money”(돈)를 참조하여 “bank“의 표현을 올바르게 조정할 수 있습니다.
데이터베이스 유추: 쿼리(Query), 키(Key), 값(Value)
셀프 어텐션의 수학적 정식화는 정보 검색(데이터베이스) 조회 모델을 기반으로 합니다. 각 입력 토큰에 대해 우리는 세 개의 벡터 표현을 투영합니다.
- 쿼리 (Query, $Q$): 현재 토큰이 “찾고 있는” 대상.
- 키 (Key, $K$): 시퀀스 내 토큰들의 “레이블” 또는 프로필.
- 값 (Value, $V$): 토큰들의 실제 내용 또는 정보.
어텐션 메커니즘은 Query와 모든 Key 간의 유사도 점수를 계산하고, 이 점수를 가중치로 정규화한 다음, Value들의 가중치 합을 반환합니다.
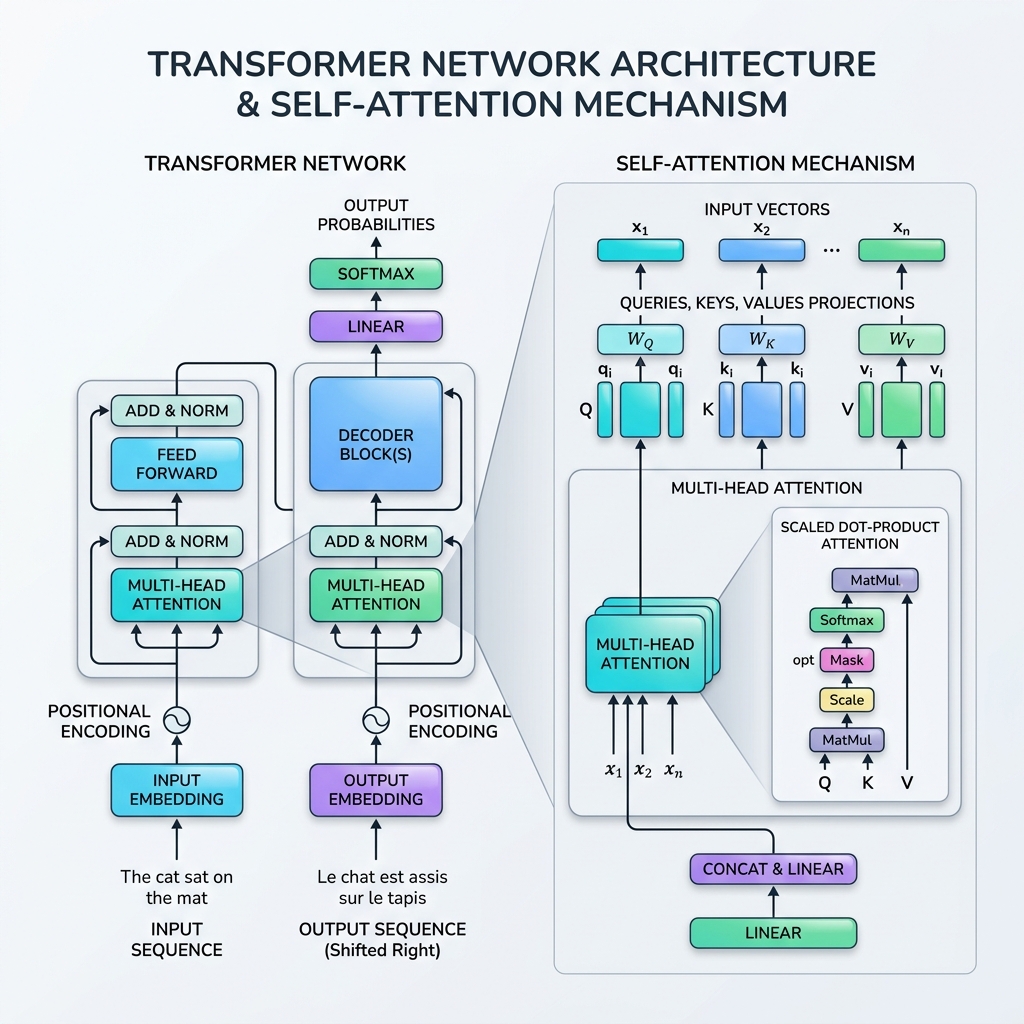
3. 스케일드 닷 프로덕트 어텐션(Scaled Dot-Product Attention)의 수학적 이해
셀프 어텐션의 표준 공식은 **스케일드 닷 프로덕트 어텐션(Scaled Dot-Product Attention)**이라고 불립니다.
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
이 공식이 실행되는 단계를 수학적으로 하나씩 짚어보겠습니다.
단계 1: 투영 행렬 계산
입력 시퀀스 행렬 $X \in \mathbb{R}^{T \times d_{\text{model}}}$에 대해, 학습 가능한 가중치 행렬 $W_Q, W_K, W_V$를 곱하여 쿼리($Q$), 키($K$), 값($V$)을 얻습니다. $$Q = X W_Q, \quad K = X W_K, \quad V = X W_V$$
단계 2: 유사도 점수 계산 (내적)
쿼리 행렬 $Q$와 키 행렬의 전치 행렬 $K^T$를 내적하여 모든 토큰 쌍 간의 원시 정렬도/관련성을 측정합니다. $$\text{Scores} = QK^T$$ 결과 행렬의 크기는 $T \times T$이며, 원소 $(i, j)$는 토큰 $i$가 토큰 $j$에 얼마나 집중해야 하는지를 나타냅니다.
단계 3: 점수 스케일링
점수를 키 차원($d_k$)의 제곱근으로 나눕니다. $$\text{Scaled Scores} = \frac{QK^T}{\sqrt{d_k}}$$ 왜 스케일링을 할까요? $d_k$ 값이 크면 내적 결과의 절댓값이 매우 커져 소프트맥스 함수가 기울기가 극도로 작은 영역(그레이디언트 소실 문제)으로 밀려납니다. $\sqrt{d_k}$로 나누어 주면 학습 과정을 안정화할 수 있습니다.
단계 4: 소프트맥스 적용 (어텐션 가중치)
각 행을 따라 소프트맥스 함수를 적용하여 점수를 확률 분포(0과 1 사이의 값으로 합이 1이 됨)로 정규화합니다. $$\text{Attention Weights} = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)$$
단계 5: 값의 가중치 합 계산
마지막으로 어텐션 가중치에 값 행렬 $V$를 곱합니다. $$\text{Output} = \text{Attention Weights} \times V$$ 이 단계를 통해 정보가 집계되며, 각 토큰의 출력 표현은 자신이 “주목한” 토큰들로부터 강한 영향을 받게 됩니다.
4. 멀티 헤드 어텐션(Multi-Head Attention)
셀프 어텐션을 한 번만 수행하는 대신, Transformer는 멀티 헤드 어텐션을 사용합니다. Query, Key, Value 벡터를 $h$개의 더 작은 차원(헤드)으로 분할하고, 각각의 하위 공간에서 독립적으로 병렬 어텐션을 수행한 후 그 결과들을 연결(concatenate)합니다.
이는 모델이 서로 다른 관계 유형에 동시에 주목할 수 있도록 하므로 매우 중요합니다. 예를 들어, 한 헤드는 주어와 동사의 일치에 집중하는 반면, 다른 헤드는 대명사 지칭 해결이나 시간적 참조에 집중할 수 있습니다.
5. 어텐션 메커니즘의 Python/NumPy 구현
구현 방식을 이해하기 위해 NumPy를 사용하여 스케일드 닷 프로덕트 어텐션과 멀티 헤드 어텐션의 간단하고 독립적인 Python 시뮬레이션 코드를 작성해 보겠습니다.
import numpy as np
def softmax(x):
# 오버플로를 방지하기 위해 안정화된 소프트맥스 사용
exp_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return exp_x / np.sum(exp_x, axis=-1, keepdims=True)
def scaled_dot_product_attention(Q, K, V, mask=None):
"""
Scaled Dot-Product Attention을 계산합니다.
Q: [batch_size, seq_len, d_k]
K: [batch_size, seq_len, d_k]
V: [batch_size, seq_len, d_v]
mask: 선택적 이진 마스크 [batch_size, seq_len, seq_len]
"""
d_k = Q.shape[-1]
# 단계 2 & 3: 내적 계산 및 스케일링
scores = np.matmul(Q, K.swapaxes(-2, -1)) / np.sqrt(d_k)
# 선택적 마스킹 (예: 디코더의 인과 마스킹)
if mask is not None:
scores = np.where(mask == 0, -1e9, scores)
# 단계 4: 소프트맥스를 적용하여 어텐션 가중치 획득
attention_weights = softmax(scores)
# 단계 5: 값의 가중치 합 계산
output = np.matmul(attention_weights, V)
return output, attention_weights
# --- 실행 예시 ---
if __name__ == "__main__":
np.random.seed(42)
batch_size = 1
seq_len = 4
d_k = 8
d_v = 8
# 무작위 Query, Key, Value 벡터 생성
Q = np.random.randn(batch_size, seq_len, d_k)
K = np.random.randn(batch_size, seq_len, d_k)
V = np.random.randn(batch_size, seq_len, d_v)
output, weights = scaled_dot_product_attention(Q, K, V)
print("어텐션 가중치 행렬 (시퀀스 길이 x 시퀀스 길이):")
print(np.round(weights[0], 4))
print("\nAttention Output Shape:", output.shape)
6. 아키텍처 비교
| 특징 | RNN / LSTM | Transformer |
|---|---|---|
| 순차적 처리 | 예 (토큰별) | 아니요 (병렬화된 시퀀스) |
| 계산 복잡도 | 순차적 $O(T)$ | 순차적 $O(1)$, 전체 연산 $O(T^2)$ |
| 장기 의존성 | 약함 (단계가 지남에 따라 메모리 소실) | 우수 (거리에 관계없이 직접 연결) |
| 병렬화 | 시간 축에 대해 불가능 | 기본적으로 병렬화 가능 |
| 위치 인지 | 암묵적 (순차적 단계에 내재) | 명시적 (위치 인코딩 필요) |
7. Transformer 블록의 기타 구성 요소
셀프 어텐션이 신경망 스택 전체에서 작동할 수 있도록 Transformer 아키텍처는 각 블록에 다음과 같은 필수적인 계층들을 포함합니다.
- 위치 인코딩(Positional Encoding): Transformer는 모든 토큰을 한 번에 처리하기 때문에 순서에 대한 내재적인 개념이 없습니다. 우리는 토큰의 순서를 나타내기 위해 다양한 주파수의 사인 및 코사인 파형을 사용하는 위치 인코딩 벡터를 입력 임베딩에 직접 더해줍니다.
- 잔차 연결(Residual Connections): 각 서브레이어(어텐션 및 피드포워드)를 우회하는 건너뛰기 연결은 그레이디언트가 소실되지 않고 깊은 네트워크를 통과하도록 돕습니다.
- 레이어 정규화(Layer Normalization): 각 레이어의 활성값을 정규화하여 학습을 안정화하고 속도를 높입니다.
- 피드포워드 네트워크(FFN): 각 토큰에 독립적으로 적용되는 위치별 MLP로, 비선형 표현 능력을 부여합니다.
결론
Transformer가 순환 구조에서 병렬화된 셀프 어텐션으로 전환되면서 현대 AI의 확장 법칙(scaling laws)이 열렸습니다. 쿼리, 키, 값을 이해함으로써 모델이 개념을 동적으로 연결하고 실시간으로 의미를 구축하는 방식을 직관적으로 파악할 수 있으며, 이는 현대 LLM의 인지 능력의 토대가 되었습니다.