Transformer Ağlarını ve Self-Attention Mekanizmasını Anlamak
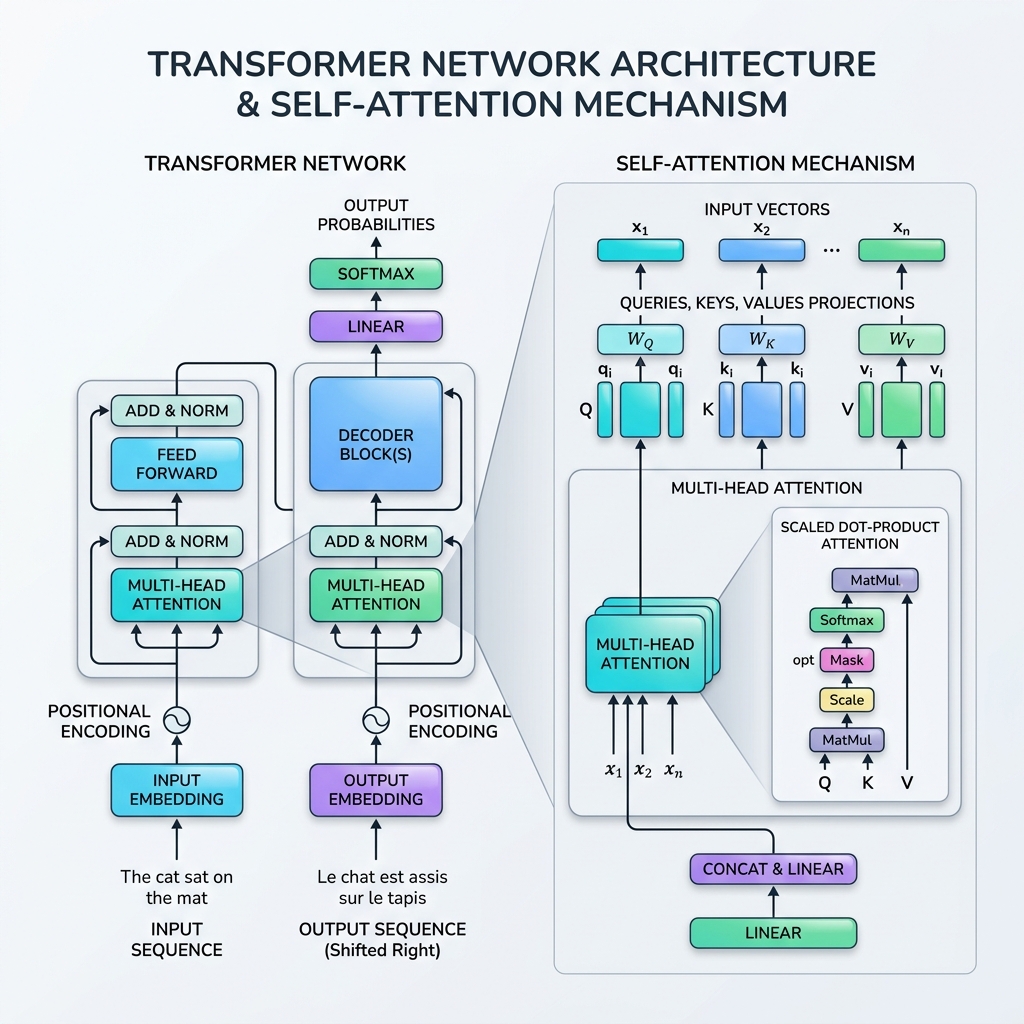
2017 yılında Vaswani ve arkadaşları tarafından yayınlanan çığır açıcı “Attention Is All You Need” makalesiyle yapay zeka dünyası kalıcı olarak değişti. Makale, tekrarlamalı yapıları (RNN’ler, LSTM’ler) tamamen bir kenara bırakıp ardışık verileri Self-Attention Mekanizması aracılığıyla paralel olarak işlemeyi tercih eden devrim niteliğindeki Transformer sinir ağı mimarisini tanıttı.
Bugün Transformer’lar; GPT-4, Gemini, Claude ve Llama dahil olmak üzere neredeyse tüm gelişmiş Büyük Dil Modellerinin (LLM’ler) temel gücünü oluşturmaktadır. Bu blog yazısında, Transformer ağlarını gizeminden arındıracak ve self-attention mekanizmasının matematiksel ve pratik olarak nasıl uygulandığını açıklayacağız.
1. Ardışık İşlemenin Darboğazı (RNN’ler ve Transformer’lar)
Transformer’lardan önce, Tekrarlayan Sinir Ağları (RNN) ve Uzun Kısa Süreli Bellek (LSTM) ağları gibi modeller, dizi modelleme için standarttı. Ancak RNN’ler token’ları ardışık olarak, yani her seferinde bir kelime olacak şekilde işler. Modelin 10. kelimenin gizli durumunu hesaplayabilmesi için öncelikle 1’den 9’a kadar olan kelimelerin gizli durumlarını hesaplaması gerekir.
Bu ardışık yapı iki ciddi sınırlama getirir:
- Paralelleştirme Yapılamaz: Hesaplamaların bir önceki adımın tamamlanmasını beklemesi gerektiğinden modern GPU’lar verimli kullanılamaz.
- Kaybolan/Patlayan Gradyanlar: Uzun bir dizinin başındaki bilgiler, model sonuna ulaşana kadar sıkışır ve kaybolur (darboğaz problemi).
Transformer mimarisi her iki sorunu da çözer. Tekrarlamayı Self-Attention ile değiştiren Transformer, girdi dizisinin tamamını aynı anda işleyerek devasa paralelleştirmeye imkan tanır ve mesafe ne olursa olsun dizideki herhangi iki token arasında doğrudan bir bağlantı yolu sağlar.
2. Self-Attention Mekanizması Nedir?
Self-attention (öz-dikkat), modelin aynı dizi içerisindeki farklı kelimeler arasındaki ilişkiyi değerlendirmesini sağlar. Model, bir kelimeyi yalıtılmış olarak işlemek yerine, cümledeki diğer tüm kelimelerin bağlamını hesaba katarak her kelimeyi temsil eder.
Örneğin, şu cümlelerde:
- “Nehrin kenarındaki bank çamurluydu.”
- “Parayı bankaya yatırdım.”
“bank” veya “banka” kelimeleri bağlama bağlı olarak farklı anlamlara sahiptir. Self-attention, modelin birinci cümledeki “nehir” ve ikinci cümledeki “para” kelimelerine bakarak bu kelimelerin temsillerini doğru şekilde ayarlamasına olanak tanır.
Veritabanı Benzetmesi: Queries (Sorgular), Keys (Anahtarlar) ve Values (Değerler)
Self-attention mimarisinin matematiksel formülü, bilgi erişim (veritabanı) aramalarına dayanarak modellenmiştir. Her girdi token’ı için üç vektör projeksiyonu elde ederiz:
- Query ($Q$): Mevcut token’ın ne aradığı.
- Key ($K$): Dizideki token’ların etiketi veya profili.
- Value ($V$): Token’ların gerçek içeriği veya bilgisi.
Dikkat mekanizması, bir Query ile tüm Keys arasındaki benzerlik skorunu hesaplar, bu skorları ağırlıklara normalize eder ve Values’un ağırlıklı toplamını döndürür.
3. Scaled Dot-Product Attention’ın Matematiksel Detayları
Self-attention için standart formül Scaled Dot-Product Attention (Ölçeklendirilmiş Nokta Çarpım Dikkat) olarak adlandırılır:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
İşte bu formülün adım adım matematiksel analizi:
Adım 1: Projeksiyon Matrislerini Hesaplama
Bir girdi dizisi matrisi $X \in \mathbb{R}^{T \times d_{\text{model}}}$ için, öğrenilebilir ağırlık matrisleri $W_Q, W_K, W_V$ ile çarparak Queries ($Q$), Keys ($K$) ve Values ($V$) elde ederiz: $$Q = X W_Q, \quad K = X W_K, \quad V = X W_V$$
Adım 2: Benzerlik Skorlarını Hesaplama (Nokta Çarpımı)
Tüm token çiftleri arasındaki ham uyumu/ilişkiyi ölçmek için Query matrisi $Q$ ile Key matrisinin transpozu olan $K^T$‘yi çarparız: $$\text{Scores} = QK^T$$ Elde edilen matris $T \times T$ boyutlarındadır ve buradaki $(i, j)$ girdisi, $i$ token’ının $j$ token’ına ne kadar dikkat etmesi gerektiğini temsil eder.
Adım 3: Skorları Ölçeklendirme
Skorlar, anahtar boyutunun ($d_k$) kareköküne bölünür: $$\text{Scaled Scores} = \frac{QK^T}{\sqrt{d_k}}$$ Neden ölçeklendirme yapılır? Şayet $d_k$ büyük olduğunda, nokta çarpımları büyüklük açısından çok büyür ve softmax fonksiyonunu son derece küçük gradyanlara sahip bölgelere iter (kaybolan gradyan problemi). $\sqrt{d_k}$ ile ölçeklendirme, eğitim sürecini kararlı hale getirir.
Adım 4: Softmax Uygulama (Dikkat Ağırlıkları)
Skorları bir olasılık dağılımına (toplamı 1 olan ve 0 ile 1 arasındaki değerler) normalize etmek için her satır boyunca softmax uygularız: $$\text{Attention Weights} = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)$$
Adım 5: Değerlerin Ağırlıklı Toplamı
Son olarak, dikkat ağırlıklarını Value matrisi $V$ ile çarparız: $$\text{Output} = \text{Attention Weights} \times V$$ Bu adım bilgiyi bir araya getirerek her bir token’ın çıktı temsilinin, “dikkat ettiği” token’lardan güçlü bir şekilde etkilenmesini sağlar.
4. Multi-Head Attention
Transformer, self-attention işlemini bir kez gerçekleştirmek yerine Multi-Head Attention (Çok Kafalı Dikkat) kullanır. Query, Key ve Value vektörlerini $h$ adet daha küçük boyuta (kafalara) böler, her bir alt uzayda bağımsız ve paralel olarak dikkat işlemi gerçekleştirir ve ardından sonuçları birleştirir (concatenate).
Bu durum kritiktir çünkü modelin aynı anda farklı ilişki türlerine dikkat etmesini sağlar. Örneğin, bir kafa özne-yüklem uyumuna odaklanırken, başka bir kafa zamir çözümlemesine veya zamansal referanslara odaklanabilir.
5. Attention Mekanizmasının Python/NumPy Uygulaması
Uygulamayı anlamak için, NumPy kullanarak Scaled Dot-Product Attention ve Multi-Head Attention’ın basit, kendi kendine yeten bir Python simülasyonunu yazalım:
import numpy as np
def softmax(x):
# Taşmayı önlemek için kararlı hale getirilmiş softmax
exp_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return exp_x / np.sum(exp_x, axis=-1, keepdims=True)
def scaled_dot_product_attention(Q, K, V, mask=None):
"""
Scaled Dot-Product Attention hesaplar.
Q: [batch_size, seq_len, d_k]
K: [batch_size, seq_len, d_k]
V: [batch_size, seq_len, d_v]
mask: İsteğe bağlı ikili maske [batch_size, seq_len, seq_len]
"""
d_k = Q.shape[-1]
# Adım 2 & 3: Nokta çarpımını hesaplama ve ölçeklendirme
scores = np.matmul(Q, K.swapaxes(-2, -1)) / np.sqrt(d_k)
# İsteğe bağlı Maskeleme (örneğin Decoder'larda Nedensel Maskeleme)
if mask is not None:
scores = np.where(mask == 0, -1e9, scores)
# Adım 4: Dikkat ağırlıklarını elde etmek için softmax uygulama
attention_weights = softmax(scores)
# Adım 5: Değerlerin ağırlıklı toplamı
output = np.matmul(attention_weights, V)
return output, attention_weights
# --- Çalıştırma Örneği ---
if __name__ == "__main__":
np.random.seed(42)
batch_size = 1
seq_len = 4
d_k = 8
d_v = 8
# Rastgele Query, Key ve Value vektörleri üretme
Q = np.random.randn(batch_size, seq_len, d_k)
K = np.random.randn(batch_size, seq_len, d_k)
V = np.random.randn(batch_size, seq_len, d_v)
output, weights = scaled_dot_product_attention(Q, K, V)
print("Dikkat Ağırlıkları Matrisi (Dizi Uzunluğu x Dizi Uzunluğu):")
print(np.round(weights[0], 4))
print("\nAttention Output Shape:", output.shape)
6. Mimari Karşılaştırma
| Özellik | RNN / LSTM | Transformer |
|---|---|---|
| Ardışık İşleme | Evet (token bazlı) | Hayır (paralelleştirilmiş dizi) |
| Hesaplama Karmaşıklığı | $O(T)$ ardışık | $O(1)$ ardışık, $O(T^2)$ toplam işlem |
| Uzun Vadeli İlişkiler | Zayıf (bellek adımlarla birlikte kaybolur) | Mükemmel (mesafeden bağımsız doğrudan bağ) |
| Paralelleştirme | Zaman ekseni boyunca imkansız | Doğal paralelleştirme |
| Konumsal Farkındalık | Örtük (ardışık adımdan gelen doğal yapı) | Açık (Positional Encoding gerektirir) |
7. İlave Transformer Bloğu Bileşenleri
Self-attention mekanizmasının tam bir yığında çalışabilmesi için Transformer mimarisi her blokta birkaç kritik katman içerir:
- Positional Encoding: Transformer’lar tüm token’ları aynı anda işlediğinden, doğal bir sıra algıları yoktur. Token sırasını temsil etmek için doğrudan girdi embedding’lerine konumsal kodlama vektörleri (farklı frekanslardaki sinüs ve kosinüs dalgaları kullanılarak) enjekte ederiz.
- Residual Connections (Artık Bağlantılar): Her alt katmanın (Attention ve Feed-Forward) etrafındaki atlama bağlantıları (skip-connections), gradyanların kaybolmadan çok derin ağlarda yayılmasına yardımcı olur.
- Layer Normalization: Her katmanın aktivasyonlarını normalize ederek eğitimi kararlı hale getirir ve hızlandırır.
- Feed-Forward Networks (FFN): Her token’a bağımsız olarak uygulanan, doğrusal olmayan temsil kapasitesi ekleyen konumsal bir MLP.
Sonuç
Transformer’ın tekrarlamadan paralel self-attention mimarisine geçişi, modern yapay zekanın ölçeklenme yasalarının önünü açtı. Queries, keys ve values kavramlarını anlayarak, modellerin kavramları nasıl dinamik olarak ilişkilendirdiğini ve gerçek zamanlı olarak anlam inşa ettiğini görebiliriz; bu da modern LLM’lerin bilişsel yeteneklerinin temelini oluşturur.