فهم شبكات المحولات (Transformer) وآلية الانتباه الذاتي (Self-Attention)
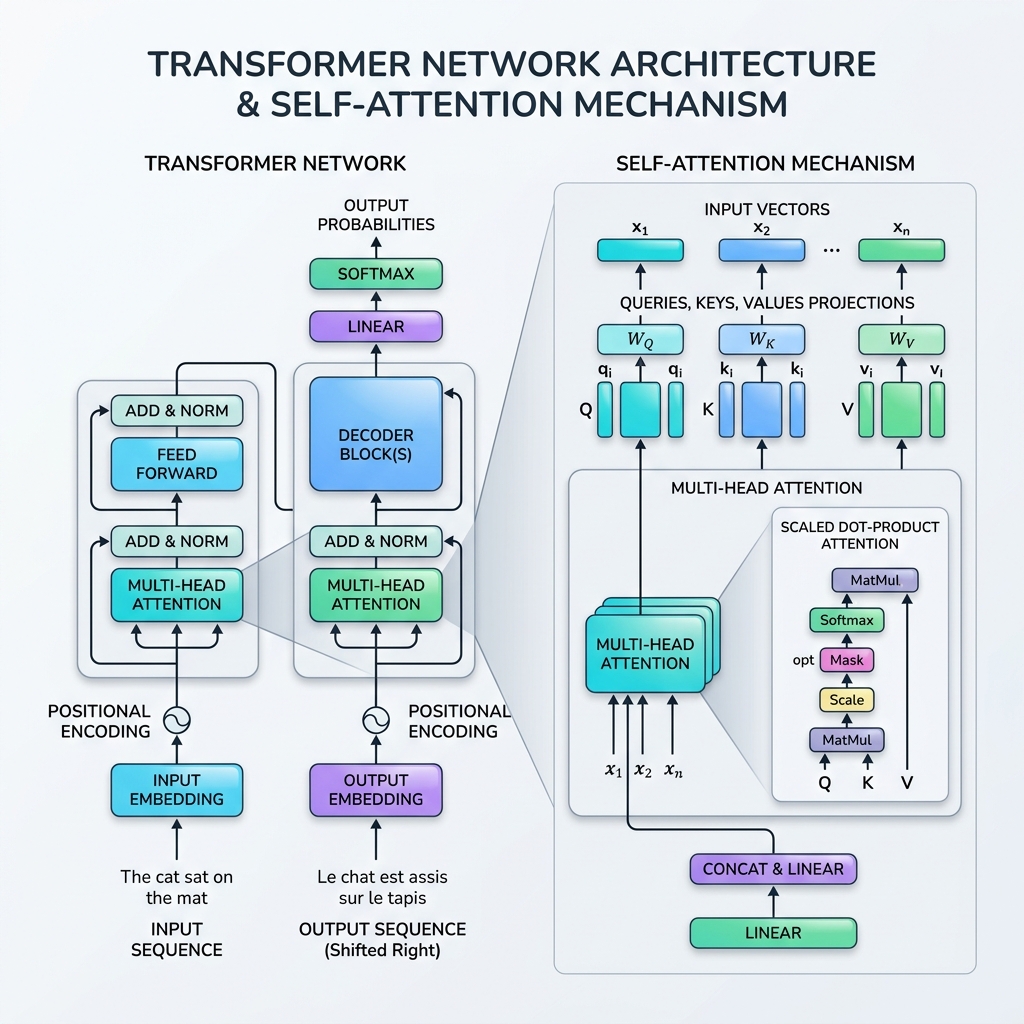
في عام 2017، تغير مشهد الذكاء الاصطناعي إلى الأبد مع نشر البحث العلمي المؤثر “Attention Is All You Need” بواسطة فريق الباحثين تحت إشراف فاسواني (Vaswani et al). قدم البحث بنية المحول (Transformer)، وهي بنية ثورية للشبكات العصبية تخلت تماماً عن التكرار (RNNs, LSTMs)، واختارت بدلاً من ذلك معالجة البيانات التسلسلية بشكل متوازٍ باستخدام آلية الانتباه الذاتي (Self-Attention Mechanism).
اليوم، تشغل المحولات جميع نماذج اللغة الكبيرة (LLMs) الحديثة تقريباً، بما في ذلك GPT-4 و Gemini و Claude و Llama. تبسط هذه المدونة فهم شبكة المحول وتشرح كيفية تنفيذ آلية الانتباه الذاتي رياضياً وعملياً.
1. عنق الزجاجة للمعالجة التسلسلية (مقارنة بين RNN والمحول)
قبل المحولات، كانت النماذج مثل الشبكات العصبية المتكررة (RNN) وشبكات الذاكرة طويلة قصيرة المدى (LSTM) هي المعيار لنمذجة التسلسلات. ومع ذلك، تعالج شبكات RNN الرموز تسلسلياً—كلمة واحدة في كل مرة. لحساب الحالة المخفية للكلمة العاشرة، يجب على النموذج أولاً حساب الحالات المخفية للكلمات من 1 إلى 9.
هذه الطبيعة التسلسلية تفرض قيوداً شديدة:
- لا يمكن إجراء المعالجة المتوازية: لا يمكن استخدام وحدات معالجة الرسومات (GPUs) الحديثة بكفاءة لأن الحسابات يجب أن تنتظر اكتمال الخطوة السابقة.
- تلاشي أو انفجار التدرجات (Gradients): تنضغط المعلومات الواردة من بداية تسلسل طويل وتضيع بحلول الوقت الذي يصل فيه النموذج إلى النهاية (مشكلة عنق الزجاجة).
تحل المحولات كلا المشكلتين. باستبدال التكرار بـ الانتباه الذاتي، يعالج المحول تسلسل الإدخال بأكمله في وقت واحد، مما يسمح بـ معالجة متوازية هائلة ومسار مباشر بين أي رمزين في التسلسل، بغض النظر عن المسافة بينهما.
2. ما هي آلية الانتباه الذاتي؟
يسمح الانتباه الذاتي للنموذج بتقييم العلاقة بين الكلمات المختلفة في نفس التسلسل. بدلاً من معالجة الكلمة بمعزل عن سياقها، يمثل النموذج كل كلمة من خلال أخذ السياق من جميع الكلمات الأخرى في الجملة.
على سبيل المثال، في الجملتين:
- “كان مصرف النهر طينياً.”
- “تم إيداع الأموال في المصرف.”
كلمة “مصرف” لها معانٍ مختلفة حسب السياق. يتيح الانتباه الذاتي للنموذج النظر إلى “النهر” في الجملة الأولى و “الأموال” في الثانية لتعديل تمثيل كلمة “مصرف” بشكل صحيح.
تشبيه قاعدة البيانات: الاستعلامات والمفاتيح والقيم
تمت صياغة الصيغة الرياضية للانتباه الذاتي على غرار عمليات البحث في قواعد البيانات. لكل رمز إدخال، نقوم بإنتاج ثلاثة تمثيلات متجهة:
- الاستعلام ($Q$ - Query): ما يبحث عنه الرمز الحالي.
- المفتاح ($K$ - Key): تصنيف أو ملف تعريف الرموز في التسلسل.
- القيمة ($V$ - Value): المحتوى الفعلي أو معلومات الرموز.
تحسب آلية الانتباه درجة التشابه بين الاستعلام وجميع المفاتيح، وتطبع هذه الدرجات في أوزان، ثم تعيد مجموعاً مرجحاً للقيم.
3. الشرح الرياضي لآلية الانتباه بالضرب النقطي المقاس
تسمى الصيغة القياسية للانتباه الذاتي Scaled Dot-Product Attention (الانتباه بالضرب النقطي المقاس):
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
إليك الشرح الرياضي خطوة بخطوة لكيفية تنفيذ هذه المعادلة:
الخطوة 1: حساب مصفوفات الإسقاط
لمصفوفة تسلسل الإدخال $X \in \mathbb{R}^{T \times d_{\text{model}}}$, نضرب في مصفوفات الأوزان القابلة للتعلم $W_Q, W_K, W_V$ للحصول على الاستعلامات ($Q$) والمفاتيح ($K$) والقيم ($V$): $$Q = X W_Q, \quad K = X W_K, \quad V = X W_V$$
الخطوة 2: حساب درجات التشابه (الضرب النقطي)
نحسب الضرب النقطي لمصفوفة الاستعلام $Q$ مع منقول مصفوفة المفاتيح $K^T$ لقياس المحاذاة/الصلة الخام بين جميع أزواج الرموز: $$\text{Scores} = QK^T$$ المصفوفة الناتجة لها أبعاد $T \times T$، حيث يمثل العنصر $(i, j)$ مقدار الانتباه الذي يجب أن يوجهه الرمز $i$ إلى الرمز $j$.
الخطوة 3: قياس (تقييس) الدرجات
تُقسم الدرجات على الجذر التربيعي لبعد المفتاح ($d_k$): $$\text{Scaled Scores} = \frac{QK^T}{\sqrt{d_k}}$$ لماذا نقوم بالتقييس؟ إذا كان $d_k$ كبيراً، تصبح قيم الضرب النقطي كبيرة جداً في الحجم، مما يدفع دالة softmax إلى مناطق ذات تدرجات صغيرة للغاية (مشكلة تلاشي التدرج). التقييس بواسطة $\sqrt{d_k}$ يضمن استقرار عملية التدريب.
الخطوة 4: تطبيق Softmax (أوزان الانتباه)
نطبق دالة softmax على طول كل صف لتحويل الدرجات إلى توزيع احتمالي (قيم بين 0 و 1 مجموعها يساوي 1): $$\text{Attention Weights} = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)$$
الخطوة 5: المجموع المرجح للقيم
أخيراً، نضرب أوزان الانتباه في مصفوفة القيم $V$: $$\text{Output} = \text{Attention Weights} \times V$$ تجمع هذه الخطوة المعلومات، مما يسمح للتمثيل الناتج لكل رمز بالتأثر بشدة بالرموز التي “انتبه” إليها.
4. الانتباه متعدد الرؤوس (Multi-Head Attention)
بدلاً من إجراء الانتباه الذاتي مرة واحدة، يستخدم المحول الانتباه متعدد الرؤوس. يقوم بتقسيم متجهات الاستعلام والمفتاح والقيمة إلى $h$ من الأبعاد الأصغر (الرؤوس)، ويؤدي الانتباه على كل فضاء فرعي بشكل مستقل ومتوازٍ، ثم يدمج النتائج معاً.
هذا أمر بالغ الأهمية لأنه يسمح للنموذج بالانتباه إلى أنواع مختلفة من العلاقات في نفس الوقت. على سبيل المثال، قد يركز رأس واحد على التوافق بين الفاعل والفعل، بينما يركز رأس آخر على الضمائر أو الإشارات الزمنية.
5. تنفيذ آلية الانتباه باستخدام Python/NumPy
لفهم كيفية التنفيذ عملياً، دعنا نكتب محاكاة بسيطة ومكتفية ذاتياً بلغة Python لحساب الانتباه بالضرب النقطي المقاس والانتباه متعدد الرؤوس باستخدام مكتبة NumPy:
import numpy as np
def softmax(x):
# دالة softmax مستقرة لتجنب طفح الأرقام
exp_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return exp_x / np.sum(exp_x, axis=-1, keepdims=True)
def scaled_dot_product_attention(Q, K, V, mask=None):
"""
يحسب الانتباه بالضرب النقطي المقاس.
Q: [batch_size, seq_len, d_k]
K: [batch_size, seq_len, d_k]
V: [batch_size, seq_len, d_v]
mask: قناع ثنائي اختياري [batch_size, seq_len, seq_len]
"""
d_k = Q.shape[-1]
# الخطوة 2 و 3: حساب الضرب النقطي والتقييس
scores = np.matmul(Q, K.swapaxes(-2, -1)) / np.sqrt(d_k)
# تطبيق القناع اختياريًا (مثل القناع السببي في فك التشفير)
if mask is not None:
scores = np.where(mask == 0, -1e9, scores)
# الخطوة 4: تطبيق softmax للحصول على أوزان الانتباه
attention_weights = softmax(scores)
# الخطوة 5: المجموع المرجح للقيم
output = np.matmul(attention_weights, V)
return output, attention_weights
# --- مثال على التشغيل ---
if __name__ == "__main__":
np.random.seed(42)
batch_size = 1
seq_len = 4
d_k = 8
d_v = 8
# توليد متجهات عشوائية للاستعلام والمفتاح والقيمة
Q = np.random.randn(batch_size, seq_len, d_k)
K = np.random.randn(batch_size, seq_len, d_k)
V = np.random.randn(batch_size, seq_len, d_v)
output, weights = scaled_dot_product_attention(Q, K, V)
print("مصفوفة أوزان الانتباه (طول التسلسل x طول التسلسل):")
print(np.round(weights[0], 4))
print("\nAttention Output Shape:", output.shape)
6. مقارنة البنية الهيكلية
| الميزة | RNN / LSTM | المحول (Transformer) |
|---|---|---|
| المعالجة التسلسلية | نعم (رمز تلو الآخر) | لا (تسلسل متوازٍ) |
| التعقيد الحسابي | $O(T)$ تسلسلي | $O(1)$ تسلسلي، $O(T^2)$ إجمالي العمليات |
| الاعتماديات طويلة المدى | ضعيفة (تتلاشى الذاكرة بمرور الخطوات) | ممتازة (رابط مباشر بغض النظر عن المسافة) |
| المعالجة المتوازية | مستحيلة على طول المحور الزمني | معالجة متوازية أصلية |
| الوعي بالمواقع | ضمني (متأصل في الخطوة التسلسلية) | صريح (يتطلب ترميزاً للمواقع) |
7. مكونات إضافية في كتلة المحول
لجعل الانتباه الذاتي يعمل في شبكة كاملة، تتضمن بنية المحول عدة طبقات حاسمة في كل كتلة:
- ترميز المواقع (Positional Encoding): نظراً لأن المحولات تعالج جميع الرموز دفعة واحدة، فليس لديها شعور متأصل بالترتيب. نقوم بحقن متجهات ترميز المواقع (باستخدام موجات الجيب وجيب التمام بترددات مختلفة) مباشرة في تضمينات المدخلات لتمثيل ترتيب الرموز.
- الاتصالات المتبقية (Residual Connections): تساعد اتصالات التخطي حول كل طبقة فرعية (الانتباه والتغذية الأمامية) التدرجات على الانتشار عبر الشبكات العميقة جداً دون أن تتلاشى.
- تقييس الطبقة (Layer Normalization): يقوم بتقييس تنشيطات كل طبقة، مما يحقق الاستقرار ويسرع التدريب.
- شبكات التغذية الأمامية (FFN): شبكة عصبية متعددة الطبقات (MLP) تُطبق على كل رمز بشكل مستقل، مما يضيف قدرة تمثيلية غير خطية.
الخلاصة
أدى تحول المحول من التكرار التسلسلي إلى الانتباه الذاتي المتوازي إلى إطلاق قوانين القياس للذكاء الاصطناعي الحديث. من خلال فهم الاستعلامات والمفاتيح والقيم، نرى كيف يمكن للنماذج ربط المفاهيم ديناميكياً وبناء المعنى في الوقت الفعلي، مما يضع الأساس للقدرات المعرفية لنماذج اللغة الكبيرة الحديثة.