Entendendo Redes Transformer e o Mecanismo de Self-Attention
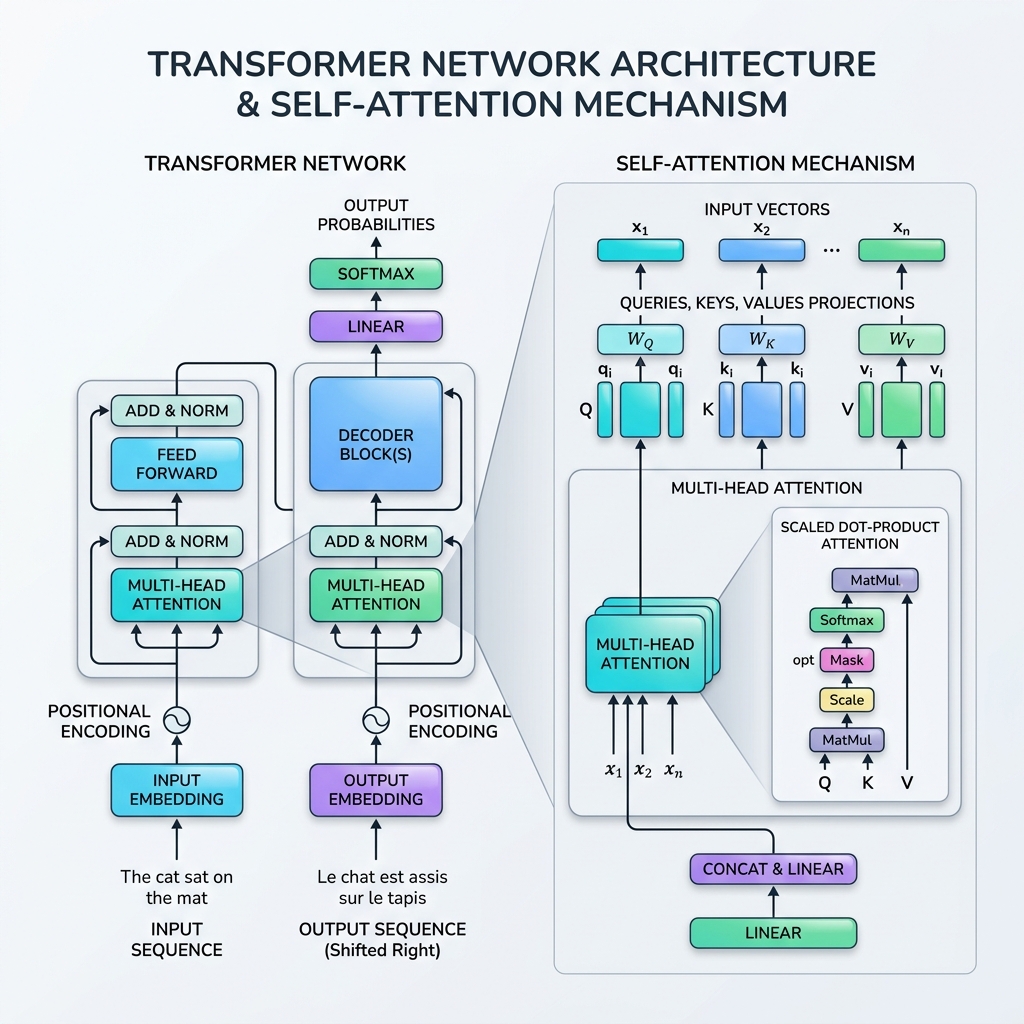
Em 2017, o cenário da inteligência artificial mudou para sempre com a publicação do seminal artigo “Attention Is All You Need” por Vaswani et al. O artigo introduziu o Transformer, uma arquitetura de rede neural revolucionária que descartou completamente a recorrência (RNNs, LSTMs), optando por processar dados sequenciais em paralelo usando o Mecanismo de Self-Attention (Autoatendimento).
Hoje, os Transformers alimentam quase todos os modelos de linguagem de grande escala (LLMs) de ponta, incluindo GPT-4, Gemini, Claude e Llama. Este blog desmistifica a rede Transformer e explica como o mecanismo de self-attention é implementado matemática e praticamente.
1. O Gargalo do Processamento Sequencial (RNNs vs. Transformers)
Antes dos Transformers, modelos como as Redes Neurais Recorrentes (RNNs) e as redes de Long Short-Term Memory (LSTM) eram o padrão para modelagem de sequências. No entanto, as RNNs processam os tokens sequencialmente — uma palavra de cada vez. Para calcular o estado oculto da 10ª palavra, o modelo deve primeiro calcular os estados ocultos das palavras de 1 a 9.
Esta natureza sequencial introduz duas limitações graves:
- Sem Paralelização: GPUs modernas não podem ser utilizadas eficientemente porque as computações devem esperar que a etapa anterior seja concluída.
- Gradientes que Desaparecem/Explodem: As informações do início de uma sequência longa são comprimidas e perdidas no momento em que o modelo atingir o final (o problema do gargalo).
Os Transformers resolvem ambos os problemas. Ao substituir a recorrência pelo Self-Attention, o Transformer processa toda a sequência de entrada simultaneamente, permitindo uma paralelização massiva e um caminho direto entre quaisquer dois tokens em uma sequência, independentemente da distância.
2. O que é o Mecanismo de Self-Attention?
O self-attention permite ao modelo avaliar a relação entre diferentes palavras na mesma sequência. Em vez de processar uma palavra de forma isolada, o modelo representa cada palavra levando em consideração o contexto de todas as outras palavras na frase.
Por exemplo, nas frases:
- “A manga da camisa está rasgada.”
- “Eu adoro comer manga madura.”
A palavra “manga” tem significados diferentes dependendo do contexto. O self-attention permite ao modelo olhar para “camisa” na primeira frase e “comer” na segunda para ajustar corretamente a representação de “manga”.
A Analogia do Banco de Dados: Queries, Keys e Values
A formulação matemática do self-attention é inspirada nas buscas de recuperação de informações em bancos de dados. Para cada token de entrada, projetamos três representações vetoriais:
- Query ($Q$): O que o token atual está procurando.
- Key ($K$): A etiqueta ou perfil dos tokens na sequência.
- Value ($V$): O conteúdo ou informação real dos tokens.
O mecanismo de atenção computa um score de similaridade entre uma Query e todas as Keys, normaliza esses scores em pesos e retorna uma soma ponderada dos Values.
3. Passo a Passo Matemático do Scaled Dot-Product Attention
A fórmula padrão para o self-attention é chamada de Scaled Dot-Product Attention:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
Aqui está o detalhamento matemático passo a passo de como essa fórmula é executada:
Passo 1: Computar as Matrizes de Projeção
Za uma matriz de sequência de entrada $X \in \mathbb{R}^{T \times d_{\text{model}}}$, multiplicamos por matrizes de peso aprendíveis $W_Q, W_K, W_V$ para obter as Queries ($Q$), Keys ($K$) e Values ($V$): $$Q = X W_Q, \quad K = X W_K, \quad V = X W_V$$
Passo 2: Calcular os Scores de Similaridade (Produto Escalar)
Calculamos o produto escalar da matriz Query $Q$ con a transposta da matriz Key $K^T$ para medir o alinhamento/relevância bruta entre todos os pares de tokens: $$\text{Scores} = QK^T$$ A matriz resultante tem dimensões $T \times T$, onde a entrada $(i, j)$ representa quanta atenção o token $i$ deve prestar ao token $j$.
Passo 3: Escalar os Scores
Os scores são divididos pela raiz quadrada da dimensão da chave ($d_k$): $$\text{Scaled Scores} = \frac{QK^T}{\sqrt{d_k}}$$ Por que escalar? Se $d_k$ for grande, os produtos escalares crescem muito em magnitude, empurrando a função softmax para regiões com gradientes extremamente pequenos (problema do gradiente desaparecendo). Escalar por $\sqrt{d_k}$ estabiliza o processo de treinamento.
Passo 4: Aplicar Softmax (Pesos de Atenção)
Aplicamos uma função softmax ao longo de cada linha para normalizar os scores em uma distribuição de probabilidade (valores entre 0 e 1 que somam 1): $$\text{Attention Weights} = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)$$
Passo 5: Soma Ponderada dos Values
Finalmente, multiplicamos os pesos de atenção pela matriz Value $V$: $$\text{Output} = \text{Attention Weights} \times V$$ Esta etapa agrega a informação, permitindo que a representação de saída de cada token seja fortemente influenciada pelos tokens aos quais ele “prestou atenção”.
4. Multi-Head Attention
Em vez de realizar o self-attention apenas uma vez, o Transformer usa o Multi-Head Attention (Atenção Multi-Cabeça). Ele divide os vetores Query, Key e Value em $h$ dimensões menores (cabeças), realiza a atenção em cada subespaço de forma independente e paralela, e depois concatena os resultados.
Isso é crítico porque permite ao modelo prestar atenção a diferentes tipos de relações simultaneamente. Por exemplo, uma cabeça pode focar na concordância sujeito-verbo, enquanto outra cabeça se concentra na resolução de pronomes ou referências temporais.
5. Implementação Python/NumPy do Mecanismo de Atenção
Para entender a implementação, vamos escrever uma simulação simples e autocontida em Python do Scaled Dot-Product Attention e do Multi-Head Attention usando o NumPy:
import numpy as np
def softmax(x):
# Softmax estabilizado para evitar estouro
exp_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return exp_x / np.sum(exp_x, axis=-1, keepdims=True)
def scaled_dot_product_attention(Q, K, V, mask=None):
"""
Computa o Scaled Dot-Product Attention.
Q: [batch_size, seq_len, d_k]
K: [batch_size, seq_len, d_k]
V: [batch_size, seq_len, d_v]
mask: Máscara binária opcional [batch_size, seq_len, seq_len]
"""
d_k = Q.shape[-1]
# Passo 2 & 3: Computar produto escalar e escalar
scores = np.matmul(Q, K.swapaxes(-2, -1)) / np.sqrt(d_k)
# Mascaramento opcional (ex. Mascaramento causal em Decoders)
if mask is not None:
scores = np.where(mask == 0, -1e9, scores)
# Passo 4: Aplicar softmax para obter os pesos de atenção
attention_weights = softmax(scores)
# Passo 5: Soma ponderada dos valores
output = np.matmul(attention_weights, V)
return output, attention_weights
# --- Exemplo de Execução ---
if __name__ == "__main__":
np.random.seed(42)
batch_size = 1
seq_len = 4
d_k = 8
d_v = 8
# Gerar vetores aleatórios de Query, Key e Value
Q = np.random.randn(batch_size, seq_len, d_k)
K = np.random.randn(batch_size, seq_len, d_k)
V = np.random.randn(batch_size, seq_len, d_v)
output, weights = scaled_dot_product_attention(Q, K, V)
print("Matriz de Pesos de Atenção (Tamanho da Sequência x Tamanho da Sequência):")
print(np.round(weights[0], 4))
print("\nFormato da Saída da Atenção:", output.shape)
6. Comparação Arquitetônica
| Característica | RNN / LSTM | Transformer |
|---|---|---|
| Processamento Sequencial | Sim (token por token) | Não (sequência paralelizada) |
| Complexidade Computacional | $O(T)$ sequencial | $O(1)$ sequencial, $O(T^2)$ operações totais |
| Dependências de Longo Alcance | Ruim (a memória desaparece nos passos) | Excelente (link direto independentemente da distância) |
| Paralelização | Impossível ao longo do eixo temporal | Paralelização nativa |
| Consciência Posicional | Implícita (inerente ao passo sequencial) | Explícita (requer Positional Encoding) |
7. Componentes Adicionais do Bloco Transformer
Para fazer o self-attention funcionar em uma pilha completa, a arquitetura Transformer inclui várias camadas cruciais em cada bloco:
- Positional Encoding: Como os Transformers processam todos os tokens de uma vez, eles não têm senso inerente de ordem. Injetamos vetores de codificação posicional (usando ondas de seno e cosseno de diferentes frequências) diretamente nos embeddings de entrada para representar a ordem dos tokens.
- Residual Connections: Skip-connections ao redor de cada subcamada (Atenção e Feed-Forward) ajudam os gradientes a se propagarem através de redes muito profundas sem desaparecerem.
- Layer Normalization: Normaliza as ativações de cada camada, estabilizando e acelerando o treinamento.
- Feed-Forward Networks (FFN): Um MLP posicional aplicado a cada token de forma independente, adicionando capacidade de representation não linear.
Conclusão
A mudança do Transformer da recorrência para o self-attention paralelizado desbloqueou as leis de escala da IA moderna. Ao entender queries, keys e values, vemos como os modelos podem ligar conceitos dinamicamente e construir significado em tempo real, estabelecendo as bases para as capacidades cognitivas dos LLMs modernos.