ٹرانسفارمر نیٹ ورکس اور سیلف اٹینشن (Self-Attention) میکانزم کو سمجھنا
2017 میں، واسوانی اور ان کے ساتھیوں کی جانب سے شائع کردہ تاریخی مقالے “Attention Is All You Need” نے مصنوعی ذہانت (AI) کے منظر نامے کو ہمیشہ کے لیے بدل دیا۔ اس مقالے نے ٹرانسفارمر (Transformer) کو متعارف کرایا، جو کہ ایک انقلابی نیورل نیٹ ورک آرکیٹیکچر تھا جس نے تکرار (RNNs, LSTMs) کو مکمل طور پر ترک کر دیا، اور اس کے بجائے سیلف اٹینشن میکانزم (Self-Attention Mechanism) کا استعمال کرتے ہوئے سلسلہ وار ڈیٹا کو متوازی (parallel) طور پر پروسیس کرنے کا انتخاب کیا۔
آج، ٹرانسفارمرز تقریباً تمام جدید ترین لارج لینگویج ماڈلز (LLMs) کو چلاتے ہیں، بشمول GPT-4، Gemini، Claude اور Llama۔ یہ بلاگ ٹرانسفارمر نیٹ ورک کی وضاحت کرتا ہے اور یہ بتاتا ہے کہ سیلف اٹینشن میکانزم کو ریاضیاتی اور عملی طور پر کیسے لاگو کیا جاتا ہے۔
1. سلسلہ وار پروسیسنگ کی رکاوٹ (RNNs بمقابلہ ٹرانسفارمرز)
ٹرانسفارمرز سے پہلے، ریکرنٹ نیورل نیٹ ورکس (RNN) اور لانگ شارٹ ٹرم میموری (LSTM) نیٹ ورکس جیسے ماڈل نیورل نیٹ ورکس میں سلسلہ وار ڈیٹا کی پروسیسنگ کا معیار تھے۔ تاہم، RNNs ٹوکنز کو سلسلہ وار طور پر پروسیس کرتے ہیں—ایک وقت میں ایک لفظ۔ 10ویں لفظ کے پوشیدہ سٹیٹ (hidden state) کی حساب کتاب کرنے کے لیے، ماڈل کو پہلے 1 سے 9 تک کے الفاظ کے پوشیدہ سٹیٹس کی حساب کتاب کرنی ہوگی۔
یہ سلسلہ وار نوعیت دو سنگین حدود پیدا کرتی ہے:
- کوئی متوازی پروسیسنگ نہیں: جدید GPUs کو مؤثر طریقے سے استعمال نہیں کیا جا سکتا کیونکہ حسابات کو پچھلے مرحلے کے مکمل ہونے کا انتظار کرنا پڑتا ہے۔
- غائب ہوتے ہوئے/پھٹتے ہوئے گریڈینٹ (Vanishing/Exploding Gradients): جب تک ماڈل آخر تک پہنچتا ہے، تب تک طویل سلسلے کی شروعات کی معلومات سکڑ جاتی ہیں اور کھو جاتی ہیں (رکاوٹ کا مسئلہ)۔
ٹرانسفارمرز ان دونوں مسائل کو حل کرتے ہیں۔ تکرار کو سیلف اٹینشن سے بدل کر، ایک ٹرانسفارمر پورے ان پٹ سلسلے کو ایک ساتھ پروسیس کرتا ہے، جس سے بڑے پیمانے پر متوازی پروسیسنگ کی اجازت ملتی ہے اور فاصلے کی پرواہ کیے بغیر سلسلے میں کسی بھی دو ٹوکنز کے درمیان براہ راست تعلق قائم ہوتا ہے۔
2. سیلف اٹینشن (Self-Attention) میکانزم کیا ہے؟
سیلف اٹینشن ماڈل کو ایک ہی سلسلے میں مختلف الفاظ کے درمیان تعلق کا جائزہ لینے کی اجازت دیتا ہے۔ کسی لفظ کو الگ تھلگ پروسیس کرنے کے بجائے، ماڈل جملے کے دیگر تمام الفاظ کے سیاق و سباق کو لے کر ہر لفظ کی نمائندگی کرتا ہے۔
مثال کے طور پر، ان جملوں میں دیکھیں:
- “دریا کا کنارہ گیلا تھا۔”
- “میں نے اپنا کوٹ کنارے پر رکھ دیا۔”
لفظ “کنارہ” کے سیاق و سباق کے لحاظ سے مختلف معنی ہیں۔ سیلف اٹینشن ماڈل کو پہلے جملے میں “دریا” اور دوسرے جملے میں “کوٹ” کو دیکھنے کی اجازت دیتا ہے تاکہ “کنارے” کی نمائندگی کو صحیح طریقے سے ترتیب دیا جا سکے۔
ڈیٹا بیس تشبیہ: کوئریز (Queries)، کیز (Keys)، اور ویلیوز (Values)
سیلف اٹینشن کا ریاضیاتی فارمولا ڈیٹا بیس سرچ کی طرز پر تیار کیا گیا ہے۔ ہر ان پٹ ٹوکن کے لیے، ہم تین ویکٹرز تیار کرتے ہیں:
- کوئری ($Q$ - Query): موجودہ ٹوکن کیا تلاش کر رہا ہے۔
- کی ($K$ - Key): سلسلے میں ٹوکنز کا لیبل یا پروفائل۔
- ویلیو ($V$ - Value): ٹوکنز کا اصل مواد یا معلومات۔
اٹینشن میکانزم کوئری اور تمام کیز کے درمیان مماثلت کا اسکور معلوم کرتا ہے، ان اسکورز کو ویٹس (weights) میں تبدیل کرتا ہے، اور ویلیوز کا ایک وزنی مجموعہ واپس کرتا ہے۔
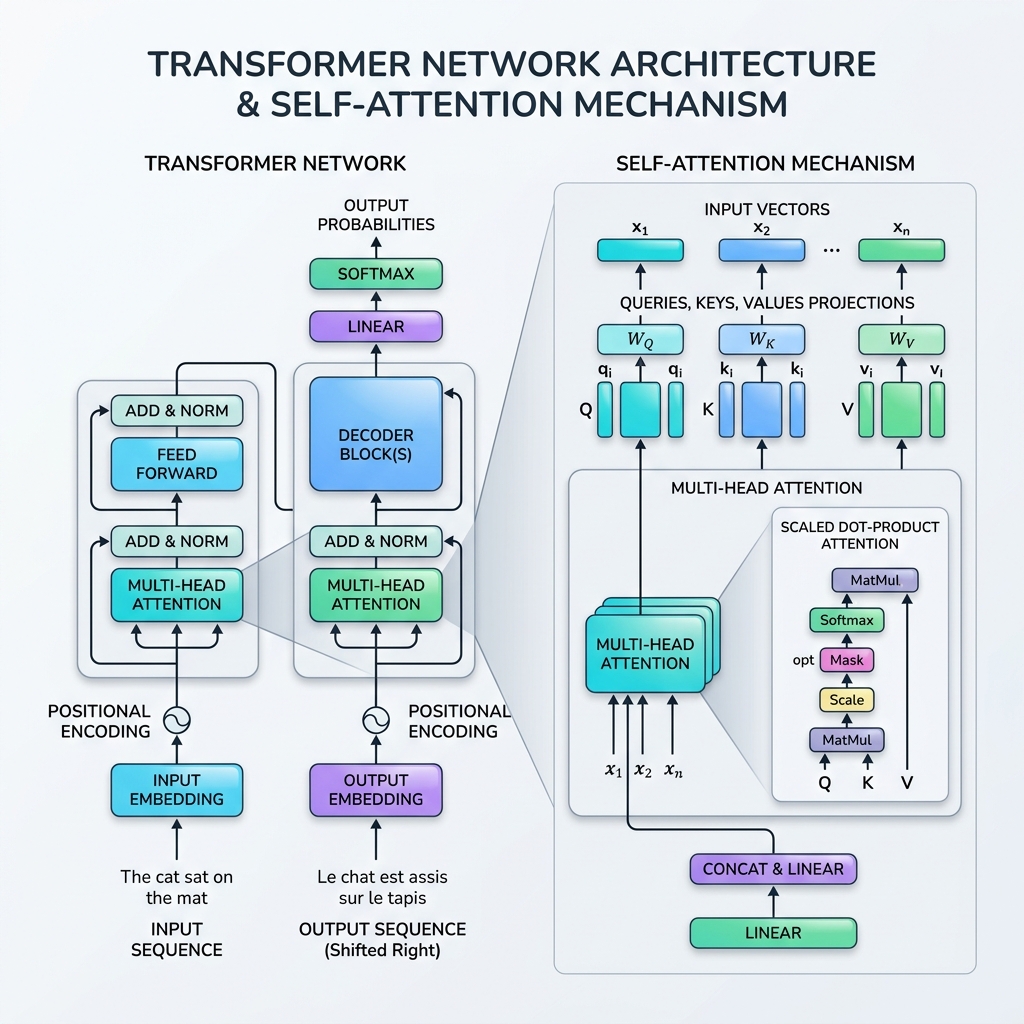
3. اسکیلڈ ڈاٹ پروڈکٹ اٹینشن کا ریاضیاتی خاکہ
سیلف اٹینشن کا معیاری فارمولا Scaled Dot-Product Attention کہلاتا ہے:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
یہاں مرحلہ وار ریاضیاتی تفصیل دی گئی ہے کہ یہ فارمولا کیسے کام کرتا ہے:
مرحلہ 1: پروجیکشن میٹرکس کا حساب لگائیں
ایک ان پٹ سلسلے کے میٹرکس $X \in \mathbb{R}^{T \times d_{\text{model}}}$ کے لیے، ہم کوئری ($Q$)، کیز ($K$)، اور ویلیوز ($V$) حاصل کرنے کے لیے سیکھنے کے قابل ویٹ میٹرکس $W_Q, W_K, W_V$ سے ضرب دیتے ہیں: $$Q = X W_Q, \quad K = X W_K, \quad V = X W_V$$
مرحلہ 2: مماثلت کے اسکور کا حساب لگائیں (ڈاٹ پروڈکٹ)
ہم تمام ٹوکن جوڑوں کے درمیان تعلق کی پیمائش کرنے کے لیے کوئری میٹرکس $Q$ کا کی میٹرکس کے ٹرانسپوز $K^T$ کے ساتھ ڈاٹ پروڈکٹ معلوم کرتے ہیں: $$\text{Scores} = QK^T$$ حاصل ہونے والا میٹرکس $T \times T$ سائز کا ہوتا ہے، جہاں پوزیشن $(i, j)$ ظاہر کرتی ہے کہ ٹوکن $i$ کو ٹوکن $j$ پر کتنا دھیان دینا چاہیے۔
مرحلہ 3: اسکور کو اسکیل کریں
اسکور کو کی کے سائز ($d_k$) کے مربع جزر سے تقسیم کیا جاتا ہے: $$\text{Scaled Scores} = \frac{QK^T}{\sqrt{d_k}}$$ اسکیل کیوں کریں؟ اگر $d_k$ بڑا ہو، تو ڈاٹ پروڈکٹ سائز میں بہت بڑے ہو جاتے ہیں، جس سے سافٹ میکس فنکشن انتہائی چھوٹے گریڈینٹ والے علاقوں میں چلا جاتا ہے (غائب گریڈینٹ کا مسئلہ)۔ $\sqrt{d_k}$ سے تقسیم کرنے سے ٹریننگ کا عمل مستحکم ہو جاتا ہے۔
مرحلہ 4: سافٹ میکس لاگو کریں (اٹینشن ویٹس)
ہم اسکورز کو امکانی تقسیم (0 اور 1 کے درمیان کی قدریں جن کا مجموعہ 1 ہوتا ہے) میں تبدیل کرنے کے لیے سافٹ میکس لاگو کرتے ہیں: $$\text{Attention Weights} = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)$$
مرحلہ 5: ویلیوز کا وزنی مجموعہ
آخر میں، ہم اٹینشن ویٹس کو ویلیو میٹرکس $V$ سے ضرب دیتے ہیں: $$\text{Output} = \text{Attention Weights} \times V$$ یہ مرحلہ معلومات کو یکجا کرتا ہے، جس سے ہر ٹوکن کا آؤٹ پٹ ان ٹوکنز سے بہت زیادہ متاثر ہوتا ہے جن پر اس نے “توجہ” دی تھی۔
4. ملٹی ہیڈ اٹینشن (Multi-Head Attention)
سیلف اٹینشن کو ایک بار کرنے کے بجائے، ٹرانسفارمر ملٹی ہیڈ اٹینشن کا استعمال کرتا ہے۔ یہ کوئری، کی، اور ویلیو ویکٹرز کو $h$ چھوٹے حصوں (ہیڈز) میں تقسیم کرتا ہے، ہر حصے پر متوازی طور پر اٹینشن کا عمل انجام دیتا ہے، اور پھر نتائج کو آپس میں جوڑتا ہے (concatenate)۔
یہ اہم ہے کیونکہ یہ ماڈل کو ایک ساتھ مختلف قسم کے تعلقات پر دھیان دینے کی اجازت دیتا ہے۔ مثال کے طور پر، ایک ہیڈ فائل اور فعل کے تعلق پر توجہ مرکوز کر سکتا ہے، جبکہ دوسرا ہیڈ ضمیر کے اشارے یا وقت کے سیاق و سباق پر توجہ مرکوز کر سکتا ہے۔
5. اٹینشن کا پائتھن/نمپائی (NumPy) کوڈ
اس عمل کو سمجھنے کے لیے، آئیے NumPy کا استعمال کرتے ہوئے اسکیلڈ ڈاٹ پروڈکٹ اٹینشن اور ملٹی ہیڈ اٹینشن کا ایک آسان، خود ساختہ پائتھن کوڈ لکھتے ہیں:
import numpy as np
def softmax(x):
# اوور فلو سے بچنے کے لیے مستحکم سافٹ میکس
exp_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return exp_x / np.sum(exp_x, axis=-1, keepdims=True)
def scaled_dot_product_attention(Q, K, V, mask=None):
"""
اسکیلڈ ڈاٹ پروڈکٹ اٹینشن کا حساب لگاتا ہے۔
Q: [batch_size, seq_len, d_k]
K: [batch_size, seq_len, d_k]
V: [batch_size, seq_len, d_v]
mask: اختیاری بائنری ماسک [batch_size, seq_len, seq_len]
"""
d_k = Q.shape[-1]
# مرحلہ 2 اور 3: ڈاٹ پروڈکٹ اور اسکیل کا حساب لگائیں
scores = np.matmul(Q, K.swapaxes(-2, -1)) / np.sqrt(d_k)
# اختیاری ماسکنگ (جیسے ڈیکوڈر میں کازل ماسکنگ)
if mask is not None:
scores = np.where(mask == 0, -1e9, scores)
# مرحلہ 4: اٹینشن ویٹس حاصل کرنے کے لیے سافٹ میکس لاگو کریں
attention_weights = softmax(scores)
# مرحلہ 5: ویلیوز کا وزنی مجموعہ
output = np.matmul(attention_weights, V)
return output, attention_weights
# --- چلانے کی مثال ---
if __name__ == "__main__":
np.random.seed(42)
batch_size = 1
seq_len = 4
d_k = 8
d_v = 8
# بے ترتیب کوئری، کی، اور ویلیو ویکٹرز بنائیں
Q = np.random.randn(batch_size, seq_len, d_k)
K = np.random.randn(batch_size, seq_len, d_k)
V = np.random.randn(batch_size, seq_len, d_v)
output, weights = scaled_dot_product_attention(Q, K, V)
print("اٹینشن ویٹس میٹرکس (سلسلے کی لمبائی x سلسلے کی لمبائی):")
print(np.round(weights[0], 4))
print("\nAttention Output Shape:", output.shape)
6. آرکیٹیکچر کا موازنہ
| خصوصیت | RNN / LSTM | ٹرانسفارمر |
|---|---|---|
| سلسلہ وار پروسیسنگ | ہاں (ٹوکن بہ ٹوکن) | نہیں (متوازی سلسلہ) |
| ریاضیاتی پیچیدگی | $O(T)$ سلسلہ وار | $O(1)$ سلسلہ وار، $O(T^2)$ کل آپریشنز |
| طویل فاصلے کا تعلق | کمزور (میموری وقت کے ساتھ ختم ہو جاتی ہے) | بہترین (فاصلے کی پرواہ کیے بغیر براہ راست لنک) |
| متوازی پروسیسنگ | وقت کے محور پر ناممکن | بنیادی متوازی خصوصیت |
| پوزیشن کا علم | پوشیدہ (سلسلہ وار قدم میں خود بخود ہوتی ہے) | واضح (پوزیشل انکوڈنگ کی ضرورت ہوتی ہے) |
7. ٹرانسفارمر بلاک کے دیگر اجزاء
پورے سسٹم میں سیلف اٹینشن کو چلانے کے لیے، ٹرانسفارمر آرکیٹیکچر میں ہر بلاک میں کئی اہم تہیں شامل ہوتی ہیں:
- پوزیشنل انکوڈنگ (Positional Encoding): چونکہ ٹرانسفارمرز تمام ٹوکنز کو ایک ساتھ پروسیس کرتے ہیں، اس لیے ان میں ترتیب کا کوئی فطری احساس نہیں ہوتا ہے۔ ہم ٹوکن کی ترتیب کو ظاہر کرنے کے لیے ان پٹ میں براہ راست پوزیشنل انکوڈنگ ویکٹرز (مختلف فریکوئنسیوں کی سائن اور کوسائن لہروں کا استعمال کرتے ہوئے) شامل کرتے ہیں۔
- ریسیڈیوئل کنکشنز (Residual Connections): ہر سب لیئر کے ارد گرد اسکیپ کنکشنز گریڈینٹس کو غائب ہوئے بغیر گہرے نیٹ ورکس سے گزرنے میں مدد کرتے ہیں۔
- لیئر نارملائزیشن (Layer Normalization): ہر لیئر کے فعال ہونے کو نارمل کرتا ہے، جس سے ٹریننگ مستحکم اور تیز ہوتی ہے۔
- فید فارورڈ نیٹ ورکس (FFN): ہر ٹوکن پر آزادانہ طور پر لاگو ایک پوزیشن وائز MLP، جو غیر لکیری نمائندگی کی صلاحیت کا اضافہ کرتا ہے۔
نتیجہ
تکرار سے متوازی سیلف اٹینشن کی طرف ٹرانسفارمرز کی منتقلی نے جدید AI کے قوانین کو آگے بڑھایا ہے۔ کوئری، کیز اور ویلیوز کو سمجھ کر، ہم دیکھ سکتے ہیں کہ کس طرح ماڈلز حقیقی وقت میں تصورات کو متحرک طور پر جوڑ سکتے ہیں اور معنی بنا سکتے ہیں، جس سے جدید LLMs کی علمی صلاحیتوں کی بنیاد رکھی گئی۔