Comprendere le reti Transformer e il meccanismo di Self-Attention
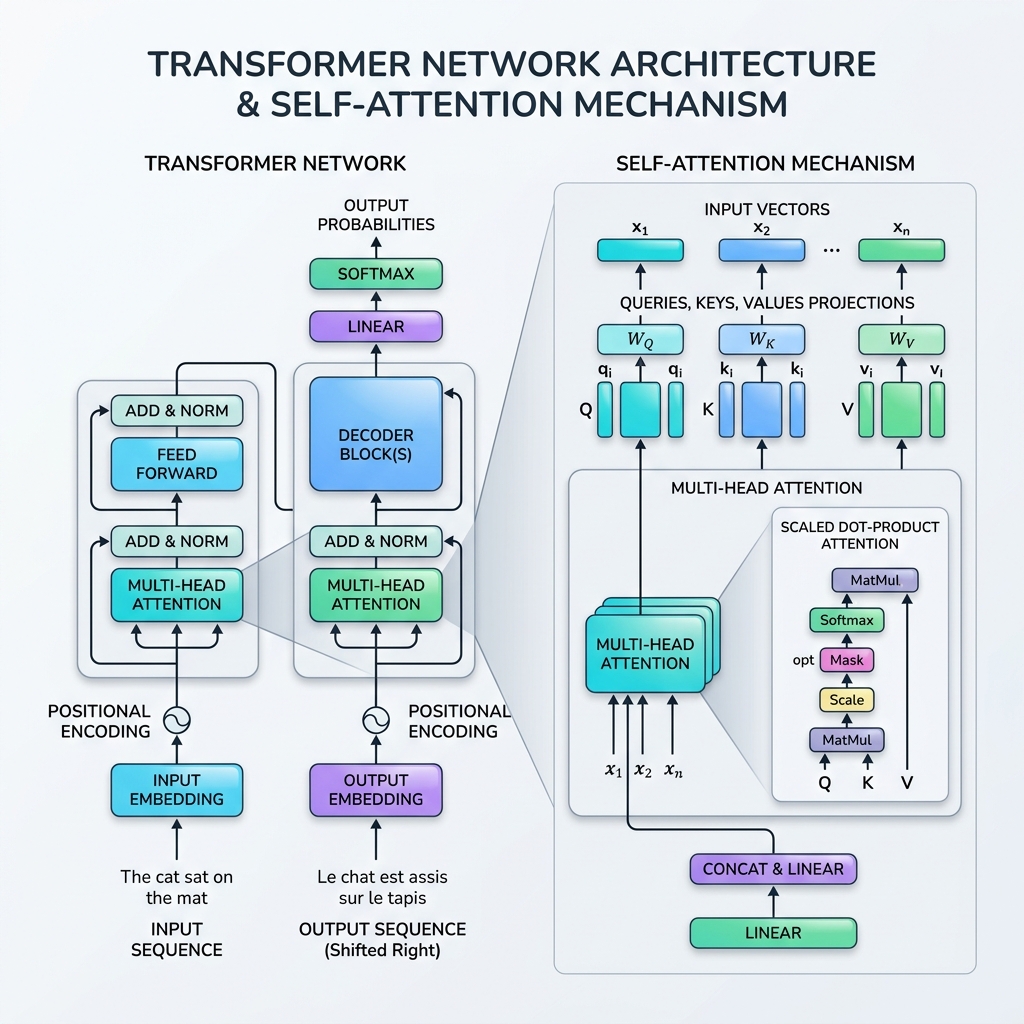
Nel 2017, il panorama dell’intelligenza artificiale è cambiato per sempre con la pubblicazione del seminale articolo “Attention Is All You Need” di Vaswani et al. L’articolo ha introdotto il Transformer, una rivoluzionaria architettura di rete neurale che ha abbandonato completamente la ricorrenza (RNN, LSTM), optando invece per l’elaborazione in parallelo di dati sequenziali tramite il Meccanismo di Self-Attention.
Oggi, i Transformer alimentano quasi tutti i modelli linguistici di grandi dimensioni (LLM) all’avanguardia, tra cui GPT-4, Gemini, Claude e Llama. Questo blog demistifica la rete Transformer e spiega come il meccanismo di self-attention viene implementato matematicamente e praticamente.
1. Il collo di bottiglia dell’elaborazione sequenziale (RNN vs. Transformer)
Prima dei Transformer, i modelli come le reti neurali ricorrenti (RNN) e le reti Long Short-Term Memory (LSTM) erano lo standard per la modellazione delle sequenze. Tuttavia, le RNN elaborano i token in modo sequenziale, una parola alla volta. Per calcolare lo stato nascosto per la decima parola, il modello deve prima calcolare gli stati nascosti per le parole da 1 a 9.
Questa natura sequenziale introduce due gravi limitazioni:
- Nessuna parallelizzazione: Le GPU moderne non possono essere utilizzate in modo efficiente perché i calcoli devono attendere il completamento del passaggio precedente.
- Gradienti che svaniscono o esplodono: Le informazioni provenienti dall’inizio di una lunga sequenza vengono compresse e vanno perse nel momento in cui il modello raggiunge la fine (il problema del collo di bottiglia).
I Transformer risolvono entrambi i problemi. Sostituendo la ricorrenza con la Self-Attention, un Transformer procesa l’intera sequenza di input contemporaneamente, consentendo una parallelizzazione massiccia e un percorso diretto tra due token qualsiasi in una sequenza, indipendentemente dalla distanza.
2. Cos’è il meccanismo di Self-Attention?
La self-attention (auto-attenzione) consente al modello di valutare la relazione tra parole diverse nella stessa sequenza. Invece di elaborare una parola in isolamento, il modello rappresenta ogni parola prendendo il contesto da tutte le altre parole nella frase.
Ad esempio, nelle frasi:
- “La pesca sull’albero è matura.”
- “La pesca sportiva richiede pazienza.”
La parola “pesca” ha significati diversi a seconda del contesto. La self-attention consente al modello di guardare “albero” nella prima frase e “sportiva” nella seconda per regolare correttamente la rappresentazione di “pesca”.
L’analogia con il database: Query, Key e Value
La formulazione matematica della self-attention è modellata sulle ricerche di recupero delle informazioni (database). Per ogni token di input, proiettiamo tre rappresentazioni vettoriali:
- Query ($Q$): Ciò che il token corrente sta cercando.
- Key ($K$): L’etichetta o il profilo dei token nella sequenza.
- Value ($V$): Il contenuto reale o le informazioni dei token.
Il meccanismo di attenzione calcola un punteggio di somiglianza tra una Query e tutte le Key, normalizza questi punteggi in pesi e restituisce una somma ponderata dei Value.
3. Procedura matematica della Scaled Dot-Product Attention
La formula standard per la self-attention si chiama Scaled Dot-Product Attention:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
Ecco la scomposizione matematica passo dopo passo di come viene eseguita questa formula:
Passaggio 1: Calcolare le matrici di proiezione
Per una matrice di sequenza di input $X \in \mathbb{R}^{T \times d_{\text{model}}}$, moltiplichiamo per matrici di peso apprendibili $W_Q, W_K, W_V$ per ottenere Query ($Q$), Key ($K$) e Value ($V$): $$Q = X W_Q, \quad K = X W_K, \quad V = X W_V$$
Passaggio 2: Calcolare i punteggi di somiglianza (Prodotto scalare)
Calcoliamo il prodotto scalare della matrice Query $Q$ con la trasposta della matrice Key $K^T$ per misurare l’allineamento/rilevanza tra tutte le coppie di token: $$\text{Scores} = QK^T$$ La matrice risultante ha dimensioni $T \times T$, dove la voce $(i, j)$ rappresenta quanta attenzione il token $i$ dovrebbe prestare al token $j$.
Passaggio 3: Scalare i punteggi
I punteggi vengono divisi per la radice quadrata della dimensione delle chiavi ($d_k$): $$\text{Scaled Scores} = \frac{QK^T}{\sqrt{d_k}}$$ Perché scalare? Se $d_k$ è grande, i prodotti scalari crescono molto in termini di grandezza, spingendo la funzione softmax in regioni con gradienti estremamente piccoli (problema del gradiente svanente). La scalabilità per $\sqrt{d_k}$ stabilizza il processo di addestramento.
Passaggio 4: Applicare Softmax (Pesi di attenzione)
Applichiamo una funzione softmax lungo ciascuna riga per normalizzare i punteggi in una distribuzione di probabilità (valori compresi tra 0 e 1 che sommano a 1): $$\text{Attention Weights} = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)$$
Passaggio 5: Somma ponderata dei Value
Infine, moltiplichiamo i pesi di attenzione per la matrice Value $V$: $$\text{Output} = \text{Attention Weights} \times V$$ Questo passaggio aggrega le informazioni, consentendo alla rappresentazione di output di ciascun token di essere fortemente influenzata dai token a cui ha “prestato attenzione”.
4. Multi-Head Attention
Invece di eseguire la self-attention una sola volta, il Transformer utilizza la Multi-Head Attention (attenzione multi-testa). Suddivide i vettori Query, Key e Value in $h$ dimensioni più piccole (teste), esegue l’attenzione su ciascun sottospazio in modo indipendente e in parallelo, quindi concatena i risultati.
Ciò è fondamentale perché consente al modello di prestare attenzione a diversi tipi di relazioni contemporaneamente. Ad esempio, una testa potrebbe concentrarsi sull’accordo soggetto-verbo, mentre un’altra si concentra sulla risoluzione dei pronomi o sui riferimenti temporali.
5. Implementazione Python/NumPy dell’Attenzione
Per comprendere l’implementazione, scriviamo una simulazione Python semplice e autosufficiente della Scaled Dot-Product Attention e della Multi-Head Attention utilizzando NumPy:
import numpy as np
def softmax(x):
# Softmax stabilizzato per evitare l'overflow
exp_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return exp_x / np.sum(exp_x, axis=-1, keepdims=True)
def scaled_dot_product_attention(Q, K, V, mask=None):
"""
Calcola la Scaled Dot-Product Attention.
Q: [batch_size, seq_len, d_k]
K: [batch_size, seq_len, d_k]
V: [batch_size, seq_len, d_v]
mask: Maschera binaria opzionale [batch_size, seq_len, seq_len]
"""
d_k = Q.shape[-1]
# Passaggio 2 & 3: Calcolo del prodotto scalare e scala
scores = np.matmul(Q, K.swapaxes(-2, -1)) / np.sqrt(d_k)
# Mascheramento opzionale (es. Mascheramento causale nei decoder)
if mask is not None:
scores = np.where(mask == 0, -1e9, scores)
# Passaggio 4: Applicazione del softmax per ottenere i pesi di attenzione
attention_weights = softmax(scores)
# Passaggio 5: Somma ponderata dei value
output = np.matmul(attention_weights, V)
return output, attention_weights
# --- Esempio di esecuzione ---
if __name__ == "__main__":
np.random.seed(42)
batch_size = 1
seq_len = 4
d_k = 8
d_v = 8
# Generazione di vettori Query, Key e Value casuali
Q = np.random.randn(batch_size, seq_len, d_k)
K = np.random.randn(batch_size, seq_len, d_k)
V = np.random.randn(batch_size, seq_len, d_v)
output, weights = scaled_dot_product_attention(Q, K, V)
print("Matrice dei pesi di attenzione (Lunghezza sequenza x Lunghezza sequenza):")
print(np.round(weights[0], 4))
print("\nShape dell'output dell'attenzione:", output.shape)
6. Confronto Architetturale
| Caratteristica | RNN / LSTM | Transformer |
|---|---|---|
| Elaborazione sequenziale | Sì (token per token) | No (sequenza parallelizzata) |
| Complessità computazionale | $O(T)$ sequenziale | $O(1)$ sequenziale, $O(T^2)$ operazioni totali |
| Dipendenze a lungo raggio | Scarsa (la memoria svanisce nei passaggi) | Eccellente (collegamento diretto indipendentemente dalla distanza) |
| Parallelizzazione | Impossibile lungo l’asse temporale | Parallelizzazione nativa |
| Consapevolezza posizionale | Implicita (insita nel passaggio sequenziale) | Esplicita (richiede la codifica posizionale) |
7. Componenti aggiuntivi del blocco Transformer
Per far funzionare la self-attention in uno stack completo, l’architettura Transformer include diversi livelli cruciali in ogni blocco:
- Positional Encoding: Poiché i Transformer elaborano tutti i token contemporaneamente, non hanno un senso intrinseco dell’ordine. Iniettiamo vettori di codifica posicionali direttamente negli embedding di input per rappresentare l’ordine dei token.
- Residual Connections: Le connessioni skip attorno a ciascun sotto-livello (Attenzione e Feed-Forward) aiutano i gradienti a propagarsi attraverso reti molto profonde senza svanire.
- Layer Normalization: Normalizza le attivazioni di ciascun livello, stabilizzando e velocizzando l’addestramento.
- Feed-Forward Networks (FFN): Una MLP applicata a ciascun token in modo indipendente, aggiungendo capacità di rappresentazione non lineare.
Conclusione
Il passaggio del Transformer dalla ricorrenza alla self-attention parallelizzata ha sbloccato le leggi di scala dell’IA moderna. Comprendendo query, key e value, vediamo come i modelli possono collegare dinamicamente i concetti e costruire il significato in tempo reale, gettando le basi per le capacità cognitive dei moderni LLM.
Esplora altre prospettive tecnologiche sul Blog di Ghaznix →