הבנת רשתות טרנספורמר ומנגנון הקשב העצמי (Self-Attention)
בשנת 2017, נוף הבינה המלאכותית השתנה לתמיד עם פרסום המאמר המכונן “Attention Is All You Need” על ידי וסוואני ואחרים (Vaswani et al). המאמר הציג את ה-Transformer, ארכיטקטורת רשת קשרים עצבית מהפכנית שזנחה לחלוטיن את הרקורסיה (RNNs, LSTMs), ובחרה במקום זאת לעבד נתונים סדרתיים במקביל באמצעות מנגנון הקשב העצמי (Self-Attention Mechanism).
כיום, טרנספורמרים מניעים כמעט את כל מודלי השפה הגדולים (LLMs) המובילים, כולל GPT-4, Gemini, Claude ו-Llama. בלוג זה מפשט את רשת הטרנספורמר ומסביר כיצد מנגנון הקשב העצמי מיושם באופן מתמטי ומעשי.
1. צוואר הבקבוק של עיבוד סדרתי (RNNs לעומת טרנספורמרים)
לפני הטרנספורמרים, מודלים כמו רשתות קשרים עצביות חוזרות (RNN) ורשתות זיכרון לטווח קצר ארוך (LSTM) היו הסטנדרט למידול רצפים. עם זאת, רשתות RNN מעבדות אסימונים (tokens) באופן סדרתי—מילה אחת בכל פעם. כדי לחשב את המצב הנסתר עבור המילה ה-10, המודל חייב תחילה לחשב את המצבים הנסתרים עבור מילים 1 עד 9.
טבע סדרתי זה מציג שתי מגבלות חמורות:
- אין מקביליות: לא ניתן לנצל מעבדים גרפיים (GPUs) מודרניים ביעילות מכיוون שהחישובים חייבים להמתיن להשלמת השלב הקודם.
- גרדיאנטים נעלמים/מתפוצצים: מידע מתחילת רצף אروך נדחס ונעלם עד שהמודל מגיע לסוף (בעיית צוואר הבקבוק).
טרנספורמרים פותרים את שתי הבעיות. על ידי החלפת הרקורסיה ב-Self-Attention, טרנספורמר מעבד את כל רצף הקלט בו-זמנית, מה שמאפשר מקביליות עצוمة ונתיב ישיר בין כל שני אסימונים ברצף, ללא קשר למרחק ביניהם.
2. מהו מנגנון הקשב העצמי?
קשב עצמי (Self-attention) מאפשר למודל להעריך את מערכת היחסים בין מילים שונות באותו רצף. במקום לעבד מילה בבידוד, המודל מייצג כל מילה על ידי לקיחת הקשר מכל המילים האחרות במשפט.
לדוגמה, במשפטים הבאים:
- “היה קר מאוד על גדת הנהר.”
- “הפקיד קיبل אותי בחיוך בגדת הבנק.”
למילה “גדת” יש משמעויות שונות בהתאם להקשר. קשב עצמי מאפשר למודל להסתכל על “הנהר” במשפט הראשון ועל “הבנק” במשפט השני כדי להתאים נכון את הייצוג של המילה “גדת”.
האנלוגיה למסדי נתונים: Queries, Keys ו-Values
הניסוח המתמטי של קשב עצמי מבוסس על שאילתות חיפוש במסדי נתונים. עבור כל אסימون קלט, אנו מייצרים שלושה ייצוגי וקטורים:
- שאילתה ($Q$ - Query): מה שהאסימون הנוכחי מחפש.
- מפתח ($K$ - Key): התווית או הפרופיל של האסימונים ברצף.
- ערך ($V$ - Value): התוכן או המידע בפועל של האסימונים.
מנגנון הקשב מחשב ציון דמיון בין שאילתה לכל המפתחות, מנרמל את הציונים הללו למשקولות, ומחזיר סכום משוקלל של הערכים.
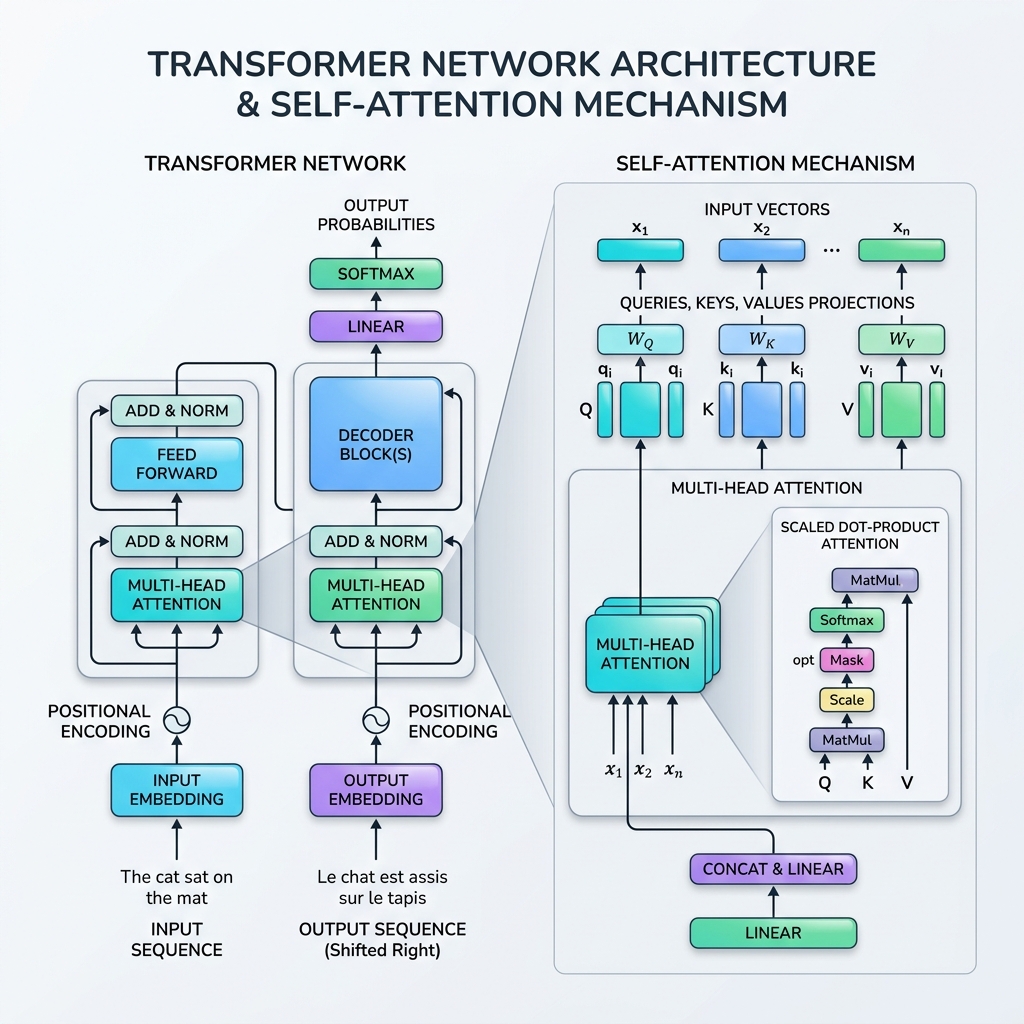
3. הסבר מתמטי של Scaled Dot-Product Attention
הנוסחה הסטנדרטית לקשב עצמי נקראת Scaled Dot-Product Attention:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
להלן הפירוט המתמטי שלב אחר שלב של אופן ביצוע הנוסחה הזו:
שלב 1: חיشוב מטריצות ההיטל
עבור מטריצת רצף קלט $X \in \mathbb{R}^{T \times d_{\text{model}}}$, אנו מכפילים במטריצות משקל למידה $W_Q, W_K, W_V$ כדי לקבל את השאילתות ($Q$), המפתחות ($K$) והערכים ($V$): $$Q = X W_Q, \quad K = X W_K, \quad V = X W_V$$
שלב 2: חיشוב ציוני דמיון (מכפלה סקלרית)
אנו מחשבים את המכפלה סקלרית של מטריצת השאילתה $Q$ עם המטריצה המשוחלפת של המפתח $K^T$ כדי למדود את ההתאמה/רלוונטיות הגולמית בין כל זוגות האסימונים: $$\text{Scores} = QK^T$$ המטריצה המתקבלת היא בעלת ממדים של $T \times T$, כאשר האיבר $(i, j)$ מייצג כמה קשב האסימون $i$ צריך להפנות לאסימون $j$.
שלב 3: הקטנת (נרמول) הציונים
הציונים מחולקים בשורש הריבועי של ממד המפתח ($d_k$): $$\text{Scaled Scores} = \frac{QK^T}{\sqrt{d_k}}$$ למה להקטין? אם $d_k$ גדול, המכפלות הסקלריות גדלות מאוד בגודלן, מה שדוחף את פונקציית ה-softmax לאזורים עם גרדיאנטים קטנים במיוחד (בעיית הגרדיאנט הנעלם). נרמול באמצעות $\sqrt{d_k}$ מייצב את תהליך האימון.
שלב 4: החלת Softmax (משקולות קשב)
אנו מפעילים פונקציית softmax לאורך כל שורה כדי לנרמל את הציונים להתפלגות הסתברות (ערכים בין 0 ל-1 שסכומם שווה ל-1): $$\text{Attention Weights} = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)$$
שלב 5: סכום משוקלל של הערכים
לבסוף, אנו מכפילים את משקولות הקשב במטריצת הערכים $V$: $$\text{Output} = \text{Attention Weights} \times V$$ שלב זה מאגד את המידע, ומאפשר לייצוג הפלט של كل אסימون להיות מושפע מאוד מהאסימונים שהוא “שם לב” אליהם.
4. Multi-Head Attention
במקום לבצע קשב עצמי פעם אחת בלבד, הטרנספורמר משתמש ב-Multi-Head Attention (קשב מרובה ראשים). הוא מחלק את וקטורי השאילתה, המפתח והערך ל-$h$ ממדים קטנים יותר (ראשים), מבצע קשב על כל תת-מרחב באופן עצמאי ובמקביל, ואז משרשר (concatenates) את התוצאות.
זה קריטי מכיוون שזה מאפשר למודל לשים לב לסוגים שונים של מערכות יחסים בו-זמנית. לדוגמה, ראש אחד עשוי להתמקד בהתאמה בין נושא לפועל, בעוד שראש אחר מתמקד בפתרון כינויי גוף או התייחסויות לזמן.
5. מימוש מנגנון הקשב ב-Python/NumPy
כדי להבין את המימוש, נכתוב סימולציית Python פשוטה ועצמאית של Scaled Dot-Product Attention ו-Multi-Head Attention באמצעות NumPy:
import numpy as np
def softmax(x):
# פונקציית softmax מיוצבת למניעת גלישה
exp_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return exp_x / np.sum(exp_x, axis=-1, keepdims=True)
def scaled_dot_product_attention(Q, K, V, mask=None):
"""
מחשב Scaled Dot-Product Attention.
Q: [batch_size, seq_len, d_k]
K: [batch_size, seq_len, d_k]
V: [batch_size, seq_len, d_v]
mask: מסכה בינארית אופציונלית [batch_size, seq_len, seq_len]
"""
d_k = Q.shape[-1]
# שלבים 2 ו-3: חישוב מכפלה סקלרית ונרמول
scores = np.matmul(Q, K.swapaxes(-2, -1)) / np.sqrt(d_k)
# מסכה אופציונלית (למשל מסכה סיבתית במפענחים)
if mask is not None:
scores = np.where(mask == 0, -1e9, scores)
# שלב 4: החלת softmax לקבלת משקולות הקשב
attention_weights = softmax(scores)
# שלב 5: סכום משוקלל של הערכים
output = np.matmul(attention_weights, V)
return output, attention_weights
# --- דוגמת הרצה ---
if __name__ == "__main__":
np.random.seed(42)
batch_size = 1
seq_len = 4
d_k = 8
d_v = 8
# יצירת וקטורים אקראיים עבור Query, Key, ו-Value
Q = np.random.randn(batch_size, seq_len, d_k)
K = np.random.randn(batch_size, seq_len, d_k)
V = np.random.randn(batch_size, seq_len, d_v)
output, weights = scaled_dot_product_attention(Q, K, V)
print("מטריצת משקולות קשב (אורך רצף x אורך רצף):")
print(np.round(weights[0], 4))
print("\nAttention Output Shape:", output.shape)
6. השוואת ארכיטקטורה
| תכונה | RNN / LSTM | טרנספורמר (Transformer) |
|---|---|---|
| עיבוד סדרתי | כן (אסימون אחר אסימون) | לא (רצף מקבילי) |
| סיבוכיות חישובית | $O(T)$ סדרתי | $O(1)$ סדרתי, $O(T^2)$ פעולות כוללות |
| תלויות לטווח ארוך | חלש (הזיכרון נעלם עם הצעדים) | מצוין (קישור ישיר ללא קשר למרחק) |
| מקביליות | בלתי אפשרי לאורך ציר הזמן | מקביליות טבעית |
| מודעות למיקום | משתמעת (טבועה בצעד הסדרתי) | מפורשת (דורש Positional Encoding) |
7. רכיבים נוספים בבלוק טרנספורמר
כדי לגרום לקשב עצמי לעבוד ברשת מלאה, ארכיטקטורת הטרנספורמר כוללת מספר שכבות קריטיות בכל בלוק:
- קידود מיקום (Positional Encoding): מכיוون שטרנספורמרים מעבדים את כל האסימונים בבת אחת, אין להם תחושה מובנית של סדר. אנו מזריקים וקטורי קידود מיקום (באמצעות גלי סינוס וקוסינוס בתדרים שונים) ישירות לייצוגי הקלט כדי לייצג את סדר האסימונים.
- חיבורי שארית (Residual Connections): חיבורי מעקף (skip-connections) סביب כל תת-שכבה (קשב ורשת הזנה קדימה) עוזרים לגרדיאנטים להתקדם ברשתות עמוקות מאוד מבלי להיעלם.
- נרמول שכבה (Layer Normalization): מנרמל את האקטיבציות של כל שכבה, מייצב ומאיץ את האימون.
- רשתות הזנה קדימה (FFN): רשת רב-שکבתית (MLP) המוחלת על כל אסימون באופן עצמאי, המוסיפה כושר ייצוג לא-ליניאری.
סיכום
המעבר של הטרנספורمر מרקורسיה לקשב עצמי מקבילי פתח את חוקی הנרמول של הבינה המלאכותية המודרנית. על ידי הבנת שאילתות, מפתחות וערכים, אנו רואים כיצد מודלים יכולים לקשר מושגים באופן דינמי ולבנות משמעות בזمن אמת, ובכך להניח את היסودות ליכולות הקוגניטיביות של מודלי שפה גדולים מודרניים.