Comprendre les Réseaux Transformer et le Mécanisme de Self-Attention
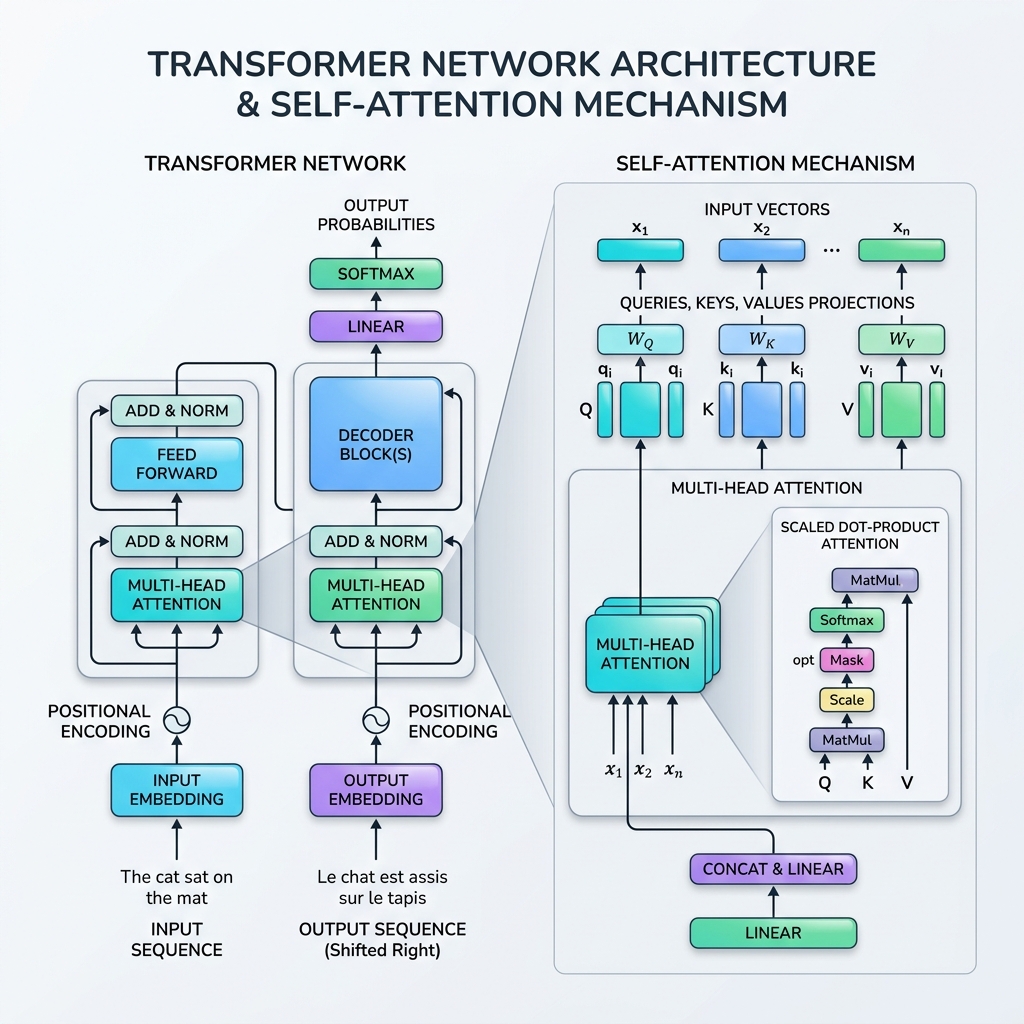
En 2017, le paysage de l’intelligence artificielle a été transformé à jamais par la publication de l’article fondateur “Attention Is All You Need” de Vaswani et al. Cet article a introduit le Transformer, une architecture de réseau de neurones révolutionnaire qui a complètement abandonné la récurrence (RNN, LSTM), choisissant plutôt de traiter les données séquentielles en parallèle grâce au Mécanisme de Self-Attention (Auto-attention).
Aujourd’hui, les Transformers alimentent la quasi-totalité des grands modèles de langage (LLM) de pointe, notamment GPT-4, Gemini, Claude et Llama. Ce blog démystifie le réseau Transformer et explique comment le mécanisme de self-attention est implémenté de manière mathématique et pratique.
1. Le goulot d’étranglement du traitement séquentiel (RNN vs. Transformer)
Avant les Transformers, les modèles tels que les réseaux de neurones récurrents (RNN) et les réseaux Long Short-Term Memory (LSTM) étaient la norme pour la modélisation de séquences. Cependant, les RNN traitent les tokens de manière séquentielle, un mot à la fois. Pour calculer l’état caché du 10e mot, le modèle doit d’abord calculer les états cachés des mots 1 à 9.
Cette nature séquentielle introduit deux limites majeures :
- Pas de parallélisation : Les GPU modernes ne peuvent pas être utilisés efficacement car les calculs doivent attendre la fin de l’étape précédente.
- Gradient qui disparaît/explose : Les informations provenant du début d’une longue séquence sont compressées et perdues le temps que le modèle atteigne la fin (le problème du goulot d’étranglement).
Les Transformers résolvent ces deux problèmes. En remplaçant la récurrence par la Self-Attention, un Transformer traite l’ensemble de la séquence d’entrée simultanément, ce qui permet une parallélisation massive et un chemin direct entre deux tokens d’une séquence, quelle que soit la distance.
2. Qu’est-ce que le mécanisme de Self-Attention ?
La self-attention permet au modèle d’évaluer la relation entre différents mots d’une même séquence. Au lieu de traiter un mot de manière isolée, le modèle représente chaque mot en intégrant le contexte de tous les autres mots de la phrase.
Par exemple, dans les phrases :
- “La pêche sur l’arbre est mûre.”
- “La pêche à la ligne exige de la patience.”
Le mot “pêche” a des significations différentes selon le contexte. La self-attention permet au modèle de regarder “arbre” dans la première phrase et “ligne” dans la deuxième pour ajuster correctement la représentation de “pêche”.
L’analogie avec les bases de données : Queries, Keys et Values
La formulation mathématique de la self-attention est inspirée de la recherche d’informations (bases de données). Pour chaque token d’entrée, nous projetons trois représentations vectorielles :
- Query ($Q$) : Ce que le token actuel recherche.
- Key ($K$) : L’étiquette ou le profil des tokens dans la séquence.
- Value ($V$) : Le contenu réel ou l’information des tokens.
Le mécanisme d’attention calcule un score de similitude entre une Query et toutes les Keys, normalise ces scores sous forme de poids, et renvoie une somme pondérée des Values.
3. Explication mathématique de la Scaled Dot-Product Attention
La formule standard de la self-attention est appelée Scaled Dot-Product Attention (Attention produit scalaire normalisé) :
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
Voici l’explication mathématique étape par étape de l’exécution de cette formule :
Étape 1 : Calculer les matrices de projection
Pour une matrice de séquence d’entrée $X \in \mathbb{R}^{T \times d_{\text{model}}}$, nous multiplions par des matrices de poids apprenables $W_Q, W_K, W_V$ pour obtenir les Queries ($Q$), Keys ($K$), et Values ($V$) : $$Q = X W_Q, \quad K = X W_K, \quad V = X W_V$$
Étape 2 : Calculer les scores de similitude (produit scalaire)
Nous calculons le produit scalaire de la matrice Query $Q$ avec la transposée de la matrice Key $K^T$ pour mesurer l’alignement/la pertinence entre toutes les paires de tokens : $$\text{Scores} = QK^T$$ La matrice résultante a pour dimensions $T \times T$, où l’entrée $(i, j)$ représente l’attention que le token $i$ doit porter au token $j$.
Étape 3 : Normaliser les scores (Scaling)
Les scores sont divisés par la racine carrée de la dimension des clés ($d_k$) : $$\text{Scaled Scores} = \frac{QK^T}{\sqrt{d_k}}$$ Pourquoi normaliser ? Si $d_k$ est grand, les produits scalaires prennent des valeurs très élevées, ce qui pousse la fonction softmax vers des régions aux gradients extrêmement faibles (problème de disparition du gradient). Diviser par $\sqrt{d_k}$ stabilise le processus d’entraînement.
Étape 4 : Appliquer Softmax (Poids d’attention)
We appliquons une fonction softmax le long de chaque ligne pour normaliser les scores en une distribution de probabilité (valeurs entre 0 et 1 dont la somme est égale à 1) : $$\text{Attention Weights} = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)$$
Étape 5 : Somme pondérée des Values
Enfin, nous multiplions les poids d’attention par la matrice Value $V$ : $$\text{Output} = \text{Attention Weights} \times V$$ Cette étape agrège l’information, permettant à la représentation finale de chaque token d’être fortement influencée par les tokens auxquels il a “prêté attention”.
4. Multi-Head Attention
Au lieu d’effectuer la self-attention une seule fois, le Transformer utilise la Multi-Head Attention (Attention multi-têtes). Elle divise les vecteurs Query, Key et Value en $h$ dimensions plus petites (têtes), applique l’attention sur chaque sous-espace de manière indépendante et parallèle, puis concatène les résultats.
Ceci est crucial car cela permet au modèle de prêter attention à différents types de relations simultanément. Par exemple, une tête peut se concentrer sur l’accord sujet-verbe, tandis qu’une autre se concentre sur les pronoms ou les références temporelles.
5. Implémentation Python/NumPy du Mécanisme d’Attention
Pour comprendre l’implémentation, écrivons une simulation Python simple et autonome de la Scaled Dot-Product Attention et de la Multi-Head Attention avec NumPy :
import numpy as np
def softmax(x):
# Softmax stabilisé pour éviter le débordement
exp_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return exp_x / np.sum(exp_x, axis=-1, keepdims=True)
def scaled_dot_product_attention(Q, K, V, mask=None):
"""
Calcule la Scaled Dot-Product Attention.
Q: [batch_size, seq_len, d_k]
K: [batch_size, seq_len, d_k]
V: [batch_size, seq_len, d_v]
mask: Masque binaire optionnel [batch_size, seq_len, seq_len]
"""
d_k = Q.shape[-1]
# Étapes 2 & 3: Calculer le produit scalaire et normaliser
scores = np.matmul(Q, K.swapaxes(-2, -1)) / np.sqrt(d_k)
# Masquage optionnel (par ex. Masquage causal dans les décodeurs)
if mask is not None:
scores = np.where(mask == 0, -1e9, scores)
# Étape 4: Appliquer softmax pour obtenir les poids d'attention
attention_weights = softmax(scores)
# Étape 5: Somme pondérée des valeurs
output = np.matmul(attention_weights, V)
return output, attention_weights
# --- Exemple d'écriture ---
if __name__ == "__main__":
np.random.seed(42)
batch_size = 1
seq_len = 4
d_k = 8
d_v = 8
# Générer des vecteurs Query, Key et Value aléatoires
Q = np.random.randn(batch_size, seq_len, d_k)
K = np.random.randn(batch_size, seq_len, d_k)
V = np.random.randn(batch_size, seq_len, d_v)
output, weights = scaled_dot_product_attention(Q, K, V)
print("Matrice des poids d'attention (Longueur sequence x Longueur sequence) :")
print(np.round(weights[0], 4))
print("\nForme de la sortie d'attention :", output.shape)
6. Comparaison des Architectures
| Caractéristique | RNN / LSTM | Transformer |
|---|---|---|
| Traitement séquentiel | Oui (token par token) | Non (séquence parallélisée) |
| Complexité algorithmique | $O(T)$ séquentiel | $O(1)$ séquentiel, $O(T^2)$ opérations totales |
| Dépendances à longue distance | Mauvaise (perte de mémoire au fil des étapes) | Excellente (lien direct sans contrainte de distance) |
| Parallélisation | Impossible sur l’axe temporel | Parallélisation native |
| Prise en compte de la position | Implicite (inhérente au traitement séquentiel) | Explicite (nécessite un Positional Encoding) |
7. Composants supplémentaires du bloc Transformer
Pour que la self-attention fonctionne dans un bloc complet, l’architecture Transformer intègre plusieurs couches indispensables :
- Positional Encoding : Les Transformers traitant tous les tokens simultanément, ils n’ont pas de notion naturelle d’ordre. Nous injectons des vecteurs de codage positionnel (à base d’ondes sinusoïdales et cosinusoïdales) directement dans les embeddings d’entrée.
- Residual Connections : Des connexions résiduelles autour de chaque sous-couche (Attention et Feed-Forward) facilitent la propagation des gradients à travers des réseaux profonds sans atténuation.
- Layer Normalization : Normalise les activations de chaque couche, ce qui accélère et stabilise l’entraînement.
- Feed-Forward Networks (FFN) : Un réseau de neurones classique appliqué indépendamment à chaque position de token, ajoutant une capacité de représentation non linéaire.
Conclusion
L’abandon de la récurrence au profit de la self-attention parallélisée par le Transformer a ouvert la voie à l’émergence de l’IA moderne. En comprenant le rôle des queries, des keys et des values, nous comprenons comment ces modèles relient dynamiquement les concepts et construisent du sens en temps réel, posant ainsi les bases des capacités cognitives des LLM actuels.