Sequence-to-Sequence(Seq2Seq)アーキテクチャとアテンションメカニズムの仕組み
自然言語処理(NLP)および人工知能(AI)の領域において、言語の翻訳、文章の要約、対話の生成を行う能力は劇的な革命を遂げました。この変革の中心に位置するのが、**Sequence-to-Sequence(Seq2Seq)アーキテクチャと、先駆的なアテンションメカニズム(Attention Mechanism)**です。
現代の Transformer が登場する前、これら2つのイノベーションは、入力配列と出力配列の長さが異なる場合にそれらをマッピングするという、ディープラーニングにおける最大の課題の1つを解決しました。
1. 基礎:Sequence-to-Sequence(Seq2Seq)とは何か?
2014年にGoogleなどの研究者によって発表されたSequence-to-Sequence(Seq2Seq)モデルは、時系列データを処理するために設計されたエンコーダー・デコーダー(Encoder-Decoder)フレームワークです。入力配列の長さと出力配列の長さが一致しない以下のようなタスクで広く使用されています:
- 機械翻訳: 英語の “How are you?"(3単語)を日本語の「お元気ですか?」(6文字)やスペイン語の “¿Cómo estás?"(2単語)に翻訳する。
- テキスト要約: 500単語の論文を50単語の要約に圧縮する。
- 質問応答: 質問の配列を回答の配列にマッピングする。
エンコーダー・デコーダーの仕組み
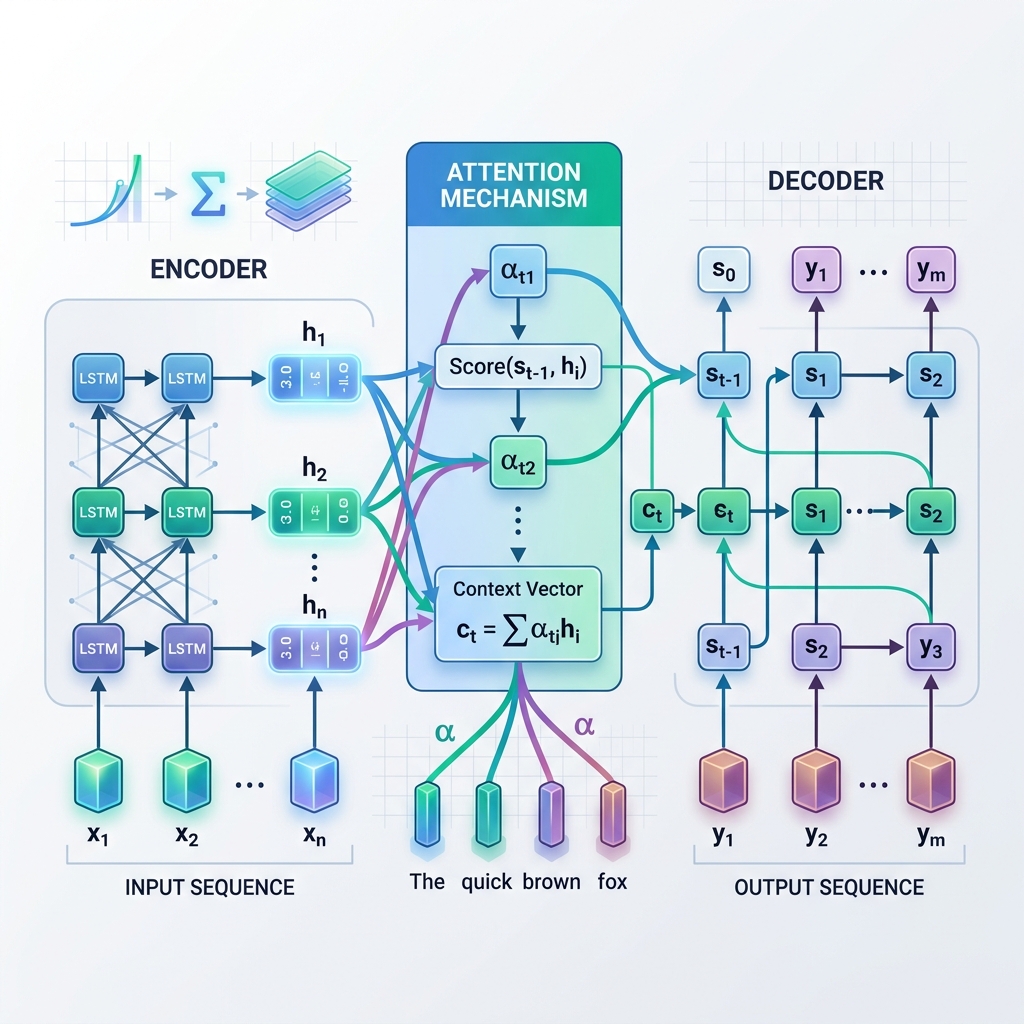
標準的なSeq2Seqモデルは、一般的にLSTM(Long Short-Term Memory)またはGRU(Gated Recurrent Units)と呼ばれる2つの再帰型ニューラルネットワーク(RNN)で構成されています:
- エンコーダー(Encoder): 入力配列をトークンごとに順次処理します。各ステップで、現在の入力トークンと前の隠れ状態に基づいて、自身の隠れ状態(hidden state)を更新します。入力全体が処理されると、エンコーダーの最後の隠れ状態が取得されます。この最終状態は文脈ベクトル(Context Vector)(またはボトルネックベクトル)と呼ばれます。
- デコーダー(Decoder): 文脈ベクトルを初期の隠れ状態として受け取り、出力配列を自帰的にトークンごとに生成します。各ステップで、現在の隠れ状態と以前に生成された単語に基づいて、次の単語を予測します。
2. ボトルネック問題(Information Bottleneck)
クラシックなエンコーダー・デコーダーモデルは大きなブレイクスルーであったものの、情報ボトルネックとして知られる根本的な限界を抱えていました。
標準的なSeq2Seqモデルでは、エンコーダーは入力文全体の意味を(それが5単語であれ100単語であれ)、固定サイズの単一の文脈ベクトルに圧縮することを強制されます。
その結果:
- 長期記憶の喪失: 長い文章では、エンコーダーが終端に達する頃には、配列の初期部分の情報が失われてしまいます。
- 性能の低下: 入力文の長さが長くなるにつれて、翻訳や要約の品質が著しく低下します。
複雑な段落を単一のベクトルに圧縮することは、本の一章全体を翻訳する前に、一言の文章で要約しようとするようなものです。情報は必然的に失われます。
3. アテンションメカニズム:パラダイムシフト
情報ボトルネックを解決するため、Dzmitry Bahdanau(バダナウ)ら研究グループは2015年に**アテンションメカニズム(注意機構)**を導入しました。
エンコーダーの最終ステップから得られる単一の静的な文脈ベクトルのみに依存する代わりに、アテンションはデコーダーがデコードプロセスの各ステップでエンコーダーのすべての隠れ状態を**「振り返る」**ことを可能にします。これは、モデルが現在生成している単語に応じて、入力配列の異なる部分に動的に焦点を当てる(注意を向ける)ことを意味します。
アテンションの仕組み:ステップ・バイ・ステップ
各デコードステップ $t$ において:
- アライメントスコアの計算 ($e_{t, j}$): デコーダーの現在の隠れ状態 $s_{t-1}$ と、エンコーダーの各隠れ状態 $h_j$ を比較し、エンコーダーの状態 $j$ がデコーダーの現在のステップにどれだけ関連しているかを測定します。 $$e_{t, j} = \text{score}(s_{t-1}, h_j)$$
- アテンション重みの計算 ($\alpha_{t, j}$): アライメントスコアを softmax 関数を使用して正規化し、合計が1になる確率(重み)に変換します。 $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$
- 動的文脈ベクトルの生成 ($c_t$): エンコーダーのすべての隠れ状態の加重平均として、文脈ベクトルを計算します。 $$c_t = \sum_j \alpha_{t, j} h_j$$
- トークンの予測: デコーダーは動的文脈ベクトル $c_t$ と現在の状態 $s_t$ を組み合わせて、次の出力トークンを予測します。
4. Seq2Seqとアテンションメカニズムの詳細な解説
これらのメカニズムの背後にある技術を真に理解するために、まず古典的な Sequence-to-Sequence アーキテクチャの数学的および操作的なステップを辿り、続いて Bahdanau(加算)と Luong(乗算)の両方のアテンション手法について解説します。
ベースライン:標準的な Sequence-to-Sequence アーキテクチャの解説(アテンションなし)
アテンションを探索する前に、標準的な Sequence-to-Sequence(エンコーダー・デコーダー)アーキテクチャが情報をどのように順次処理するかを辿ってみましょう。
- エンコーディング段階:
入力シーケンス $x_1, x_2, \dots, x_T$ に対して:
- 各タイムステップ $t$ において、エンコーダーの再帰ユニット(LSTM/GRU)は、現在の入力トークン $x_t$ と前回の隠れ状態 $h_{t-1}$ に基づいて、自身の隠れ状態 $h_t$ を更新します。 $$h_t = \text{RNN}{\text{enc}}(x_t, h{t-1})$$
- コンテキストベクトルの生成:
- エンコーダーの最終的な隠れ状態 $h_T$ は、固定のコンテキストベクトル $c$ として機能します。 $$c = h_T$$
- デコーディング段階の初期化:
- デコーダーの最初の隠れ状態 $s_0$ は、コンテキストベクトル $c$ を用いて直接初期化されます。 $$s_0 = c$$
- デコーダーの自己回帰ステップ:
- 各デコーディングタイムステップ $t$ において、デコーダーは、前回の予測トークン $y_{t-1}$ と前回の隠れ状態 $s_{t-1}$ に基づいて、自身の隠れ状態 $s_t$ を更新します。 $$s_t = \text{RNN}{\text{dec}}(y{t-1}, s_{t-1})$$
- トークンの予測:
- 次のトークン $y_t$ の確率分布は、デコーダー状態 $s_t$ に線形レイヤーと softmax 活性化関数を適用して計算されます。 $$p(y_t | y_{<t}) = \text{softmax}(W_y s_t + b_y)$$
手法 1:Bahdanau(加法)アテンションの流れ
Bahdanau アテンションは、フィードフォワードニューラルネットワーク層を使用してアライメントスコア(関連度)を計算するため、加法アテンション(Additive Attention)とも呼ばれます。この手法は、「前ステップの状態」に依存する処理フローで動作します。
- 初期化と依存関係: デコードステップ $t$ において、デコーダは自身の前ステップの隠れ状態 $s_{t-1}$ と、エンコーダのすべての入力ステップ $j$ における隠れ状態 $h_j$ を使用してアテンションを計算します。
- アライメントスコア의 計算(加法): $$e_{t, j} = v_a^T \tanh(W_a s_{t-1} + U_a h_j)$$ ここで、$W_a$ と $U_a$ は、デコーダの状態とエンコーダの状態を共通の空間に投影するための学習可能な重み行列です。それらの和が $\tanh$ 活性化関数に通され、その後、重みベクトル $v_a$ を用いてスカラー値に投影されます。
- アテンションウェイトの計算(Softmax): $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$ これにより、アライメントスコアが入力シーケンス全体にわたる確率分布に正規化されます。
- 動的なコンテキストベクトルの生成: $$c_t = \sum_j \alpha_{t, j} h_j$$ これはエンコーダの隠れ状態の加重平均であり、モデルが入力シーケンスのどの部分に集中すべきかを表します。
- デコーダの隠れ状態の更新: コンテキストベクトル $c_t$ と、前ステップの出力トークンの埋め込みベクトル $y_{t-1}$ が結合され、デコーダの回帰セルに渡されて現ステップのデコーダ状態 $s_t$ が計算されます。 $$s_t = \text{RNN}(s_{t-1}, [c_t; y_{t-1}])$$
- トークンの予測: 現ステップの状態 $s_t$ を使用して、次のトークンの出現確率を予測します。
手法 2:Luong(乗法)アテンションの流れ
Bahdanau の直後に提案された Luong アテンションは、乗法アテンション(Multiplicative Attention)と呼ばれます。計算を簡素化し、「現ステップの状態」に依存する処理フローを採用しています。
- まずデコーダの隠れ状態を更新する: デコードステップ $t$ において、デコーダはまず、前ステップの状態 $s_{t-1}$ と前ステップの出力トークン $y_{t-1}$ のみを使用して、通常の回帰遷移により隠れ状態を $s_t$ に更新します。 $$s_t = \text{RNN}(s_{t-1}, y_{t-1})$$
- アライメントスコアの計算(乗法):
Luong は3つの代替スコア関数を提案しました。最も広く使われているのは、行列の乗算を使用する General(一般)形式です。
- General: $e_{t, j} = s_t^T W_a h_j$
- Dot: $e_{t, j} = s_t^T h_j$ (次元数が同じであることを想定)
- Concat: $e_{t, j} = v_a^T \tanh(W_a [s_t; h_j])$ 乗法アテンションは、高度に最適化された行列乗算アルゴリズムを利用して計算できるため、加法アテンションに比べて計算速度が速く、メモリ効率に優れています。
- アテンションウェイトの計算(Softmax): $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$
- 動的なコンテキストベクトルの生成: $$c_t = \sum_j \alpha_{t, j} h_j$$
- アテンショナル隠れ状態の計算: 予測にデコーダの隠れ状態を直接使用するのではなく、コンテキストベクトル $c_t$ と現ステップの状態 $s_t$ を線形レイヤーと $\tanh$ 活性化関数によって結合し、アテンショナル隠れ状態 $\tilde{s}_t$ を算出します。 $$\tilde{s}_t = \tanh(W_c [c_t; s_t])$$
- トークンの予測: アテンショナル隠れ状態 $\tilde{s}t$ を用いて最終的な予測値を生成します。 $$p(y_t | y{<t}, x) = \text{softmax}(W_s \tilde{s}_t)$$
構造の比較
| 特徴 | Bahdanau(加法)アテンション | Luong(乗法)アテンション |
|---|---|---|
| 数学的スコア | フィードフォワードネットワークを使用: $v_a^T \tanh(W_a s_{t-1} + U_a h_j)$ | ドット積または行列乗算を使用: $s_t^T W_a h_j$ |
| 使用されるデコーダ状態 | 前のデコーダ状態 $s_{t-1}$ を使用します。 | 現在のデコーダ状態 $s_t$ を使用します。 |
| 計算量 | より複雑で遅いですが、非常に柔軟です。 | より高速でシンプル、かつ非常に効率的です。 |
5. 技術的遺産:アテンションから Transformer へ
アテンションメカニズムは、当初RNNを強化するためのアドオンとして設計されました。しかし、研究者たちはすぐに、アテンション層がすべての重要な処理を行っている一方で、再帰構造(RNN/LSTM)はトークンを逐次処理しなければならないため、計算上のボトルネックになっていることに気づきました。
2017年、研究者らは歴史的な論文 “Attention Is All You Need” を発表し、Transformer アーキテクチャを導入しました。Transformer はRNNを完全に排除し、配列全体を並列処理するために Self-Attention(自己注意機構) のみに依存しました。
このブレイクスルーは、GPT-4、Gemini、Claudeなどの現代の大規模言語モデル(LLM)の基盤となっており、アテンションが現代の自然言語処理における最も強力な概念であることを証明しています。