시퀀스 투 시퀀스(Seq2Seq) 아키텍처와 어텐션(Attention) 메커니즘의 완벽 이해
자연어 처리(NLP)와 인공지능(AI) 분야에서 기계 번역, 텍스트 요약, 대화 생성 능력은 혁신적인 변화를 겪었습니다. 이러한 변화의 중심에는 시퀀스 투 시퀀스(Seq2Seq) 아키텍처와 선구적인 어텐션(Attention) 메커니즘이 자리 잡고 있습니다.
현대의 트랜스포머(Transformer)가 등장하기 전, 이 두 가지 혁신은 입력 시퀀스와 출력 시퀀스의 길이가 서로 다를 때 이들을 효과적으로 매핑해야 하는 딥러닝 분야의 가장 큰 난제 중 하나를 해결했습니다.
1. 기초: 시퀀스 투 시퀀스(Seq2Seq)란 무엇인가?
2014년 구글 등의 연구원들에 의해 도입된 시퀀스 투 시퀀스(Seq2Seq) 모델은 시계열 데이터를 처리하기 위해 설계된 인코더-디코더(Encoder-Decoder) 프레임워크입니다. 입력 시퀀스 길이와 출력 시퀀스 길이가 일치하지 않는 다음과 같은 작업에 널리 사용됩니다.
- 기계 번역: 영어의 “How are you?"(3단어)를 한국어의 “잘 지내시나요?"(2단어) 또는 스페인어의 “¿Cómo estás?"(2단어)로 번역하는 작업.
- 텍스트 요약: 500단어 분량의 문서를 50단어 요약본으로 압축하는 작업.
- 질의응답: 질문 시퀀스를 답변 시퀀스로 매핑하는 작업.
인코더-디코더 매커니즘
표준 Seq2Seq 모델은 일반적으로 LSTM(Long Short-Term Memory) 또는 GRU(Gated Recurrent Units)로 구성된 두 개의 순환 신경망(RNN)으로 이루어집니다.
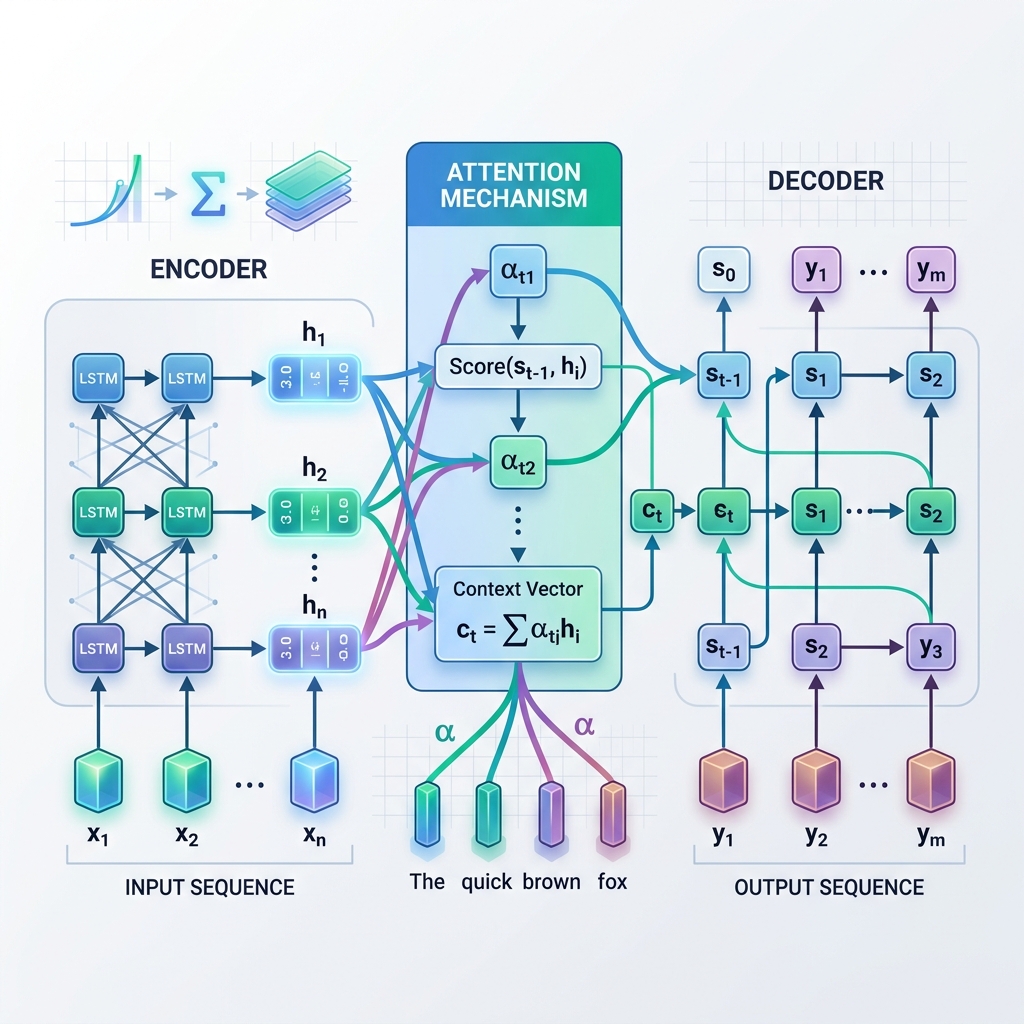
- 인코더(Encoder): 입력 시퀀스를 토큰 단위로 순차적으로 처리합니다. 각 시점(step)에서 현재 입력 토큰과 이전 은닉 상태(hidden state)를 기반으로 은닉 상태를 업데이트합니다. 입력 전체가 처리되면 인코더의 최종 은닉 상태가 캡처됩니다. 이 최종 상태를 문맥 벡터(Context Vector)(또는 병목 벡터)라고 부릅니다.
- 디코더(Decoder): 문맥 벡터를 초기 은닉 상태로 받아 출력 시퀀스를 자기회귀(autoregressive) 방식으로 토큰 단위로 생성합니다. 각 시점에서 현재 은닉 상태와 이전에 생성된 단어를 기반으로 다음 단어를 예측합니다.
2. 병목 현상 문제 (Information Bottleneck)
클래식 인코더-디코더 모델은 거대한 기술적 돌파구였으나, 정보의 병목 현상이라는 근본적인 한계를 안고 있었습니다.
표준 Seq2Seq 모델에서 인코더는 입력 문장의 전체 의미를 문장의 길이에 관계없이(5단어이든 100단어이든) 단 하나의 고정된 크기를 가진 문맥 벡터로 압축해야만 합니다.
이로 인해 다음과 같은 문제가 발생합니다.
- 장기 기억 상실: 문장이 길어질수록, 인코더가 마지막 단어에 도달할 때 시퀀스 앞부분의 정보는 유실되거나 희석됩니다.
- 성능 저하: 입력 문장의 길이가 길어질수록 번역이나 요약의 품질이 급격히 저하됩니다.
복잡한 문단을 단 하나의 벡터로 압축하는 것은 책 한 장 전체를 번역하기 전에 단 한 문장으로 요약하려는 시도와 같습니다. 이 과정에서 정보의 손실은 불가피합니다.
3. 어텐션 메커니즘: 패러다임의 전환
이러한 정보 병목 현상을 해결하기 위해 드미트리 바흐다나우(Dzmitry Bahdanau) 연구팀은 2015년에 **어텐션 메커니즘(어텐션 기능)**을 도입했습니다.
인코더의 마지막 단계에서 출력되는 정적이고 단일한 문맥 벡터에만 의존하는 대신, 어텐션은 디코더가 생성 단계의 매 시점마다 인코더의 모든 은닉 상태를 ‘되돌아볼 수 있도록’ 지원합니다. 이는 모델이 현재 생성하고 있는 단어에 맞춰 입력 시퀀스의 서로 다른 부분에 동적으로 초점을 맞추는(어텐션을 주는) 것을 의미합니다.
어텐션 작동 원리: 단계별 해체
매 디코딩 시점 $t$에서:
- 어라인먼트 스코어 계산 ($e_{t, j}$): 디코더의 현재 은닉 상태 $s_{t-1}$과 인코더의 각 은닉 상태 $h_j$를 비교하여, 인코더 상태 $j$가 현재 디코더 단계와 얼마나 관련이 있는지 측정합니다. $$e_{t, j} = \text{score}(s_{t-1}, h_j)$$
- 어텐션 가중치 계산 ($\alpha_{t, j}$): 어라인먼트 스코어를 softmax 함수를 통해 정규화하여 합이 1이 되는 확률(가중치) 분포로 변환합니다. $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$
- 동적 문맥 벡터 생성 ($c_t$): 인코더의 모든 은닉 상태를 가중합하여 최종 문맥 벡터를 계산합니다. $$c_t = \sum_j \alpha_{t, j} h_j$$
- 토큰 예측: 디코더는 동적 문맥 벡터 $c_t$와 현재 상태 $s_t$를 결합하여 다음 출력 토큰을 예측합니다.
4. Seq2Seq 및 어텐션 매커니즘의 상세 동작 방식
이 메커니즘의 엔지니어링 과정을 깊이 이해하기 위해, 클래식 Sequence-to-Sequence 아키텍처의 수학적 및 연산 단계를 먼저 살펴본 후, Bahdanau(덧셈) 및 Luong(곱셈) 어텐션 기법의 세부 과정을 추적해 보겠습니다.
베이스라인: 클래식 Sequence-to-Sequence 아키텍처 동작 방식 (어텐션 미적용)
어텐션을 배우기 전에, 표준 Sequence-to-Sequence (Encoder-Decoder) 아키텍처가 정보를 순차적으로 처리하는 방식을 살펴보겠습니다.
- 인코딩 단계:
입력 시퀀스 $x_1, x_2, \dots, x_T$에 대해:
- 각 시점 $t$마다 인코더 순환 셀(LSTM/GRU)은 현재 입력 토큰 $x_t$와 이전 은닉 상태 $h_{t-1}$을 기반으로 은닉 상태 $h_t$를 업데이트합니다. $$h_t = \text{RNN}{\text{enc}}(x_t, h{t-1})$$
- 컨텍스트 벡터 생성:
- 인코더의 마지막 은닉 상태 $h_T$가 고정 크기의 컨텍스트 벡터 $c$(정적 병목 표현) 역할을 합니다. $$c = h_T$$
- 디코딩 단계 초기화:
- 디코더 순환 셀의 초기 은닉 상태 $s_0$은 컨텍스트 벡터 $c$로 직접 초기화됩니다. $$s_0 = c$$
- 디코더 자기회귀 단계:
- 각 디코딩 시점 $t$마다 디코더는 이전 예측 토큰 $y_{t-1}$과 이전 은닉 상태 $s_{t-1}$을 기반으로 은닉 상태 $s_t$를 업데이트합니다. $$s_t = \text{RNN}{\text{dec}}(y{t-1}, s_{t-1})$$
- 토큰 예측:
- 다음 토큰 $y_t$의 확률 분포는 디코더 상태 $s_t$에 선형 레이어와 softmax 활성화 함수를 적용하여 계산됩니다. $$p(y_t | y_{<t}) = \text{softmax}(W_y s_t + b_y)$$
기법 1: 바흐다나우(합산/가법) 어텐션 동작 과정
바흐다나우 어텐션은 피드포워드 인공신경망 레이어를 사용하여 정렬 점수(alignment scores)를 계산하기 때문에 합산 어텐션 또는 가법 어텐션(additive attention)이라고도 불립니다. 이 기법은 ‘이전 상태(previous-state)’ 의존성 기반의 연산 흐름으로 동작합니다.
- 초기화 및 의존성: 디코딩 단계 $t$에서, 디코더는 어텐션을 계산하기 위해 자신의 이전 은닉 상태(hidden state) $s_{t-1}$와 모든 입력 단계 $j$에 대한 인코더 은닉 상태 $h_j$를 사용합니다.
- 정렬 점수 계산 (합산/가법): $$e_{t, j} = v_a^T \tanh(W_a s_{t-1} + U_a h_j)$$ 여기서 $W_a$와 $U_a$는 디코더 상태와 인코더 상태를 공유 공간으로 투영하는 학습 가능한 가중치 행렬입니다. 투영된 상태들의 합은 $\tanh$ 활성화 함수를 통과한 다음, 가중치 벡터 $v_a$를 통해 스칼라 값으로 투영됩니다.
- 어텐션 가중치 계산 (Softmax): $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$ 이를 통해 정렬 점수를 입력 시퀀스 전체에 대한 확률 분포로 정규화합니다.
- 동적 컨텍스트 벡터(Context Vector) 생성: $$c_t = \sum_j \alpha_{t, j} h_j$$ 인코더 은닉 상태들의 가중합으로, 모델이 입력 시퀀스에서 집중해야 할 부분을 나타냅니다.
- 디코더 은닉 상태 업데이트: 컨텍스트 벡터 $c_t$는 이전 출력 토큰 $y_{t-1}$의 임베딩과 결합(concatenate)되고, 디코더의 순환 셀로 전달되어 현재 디코더 상태 $s_t$를 계산합니다. $$s_t = \text{RNN}(s_{t-1}, [c_t; y_{t-1}])$$
- 토큰 예측: 현재 상태 $s_t$를 사용하여 다음 토큰이 나타날 확률을 예측합니다.
기법 2: 루옹(곱산/승법) 어텐션 동작 과정
바흐다나우 어텐션 이후 등장한 루옹 어텐션은 곱산 어텐션 또는 승법 어텐션(multiplicative attention)이라고 불립니다. 계산 과정을 단순화하였으며, ‘현재 상태(current-state)’ 의존성 기반의 연산 흐름을 따릅니다.
- 디코더 은닉 상태 우선 업데이트: 디코딩 단계 $t$에서, 디코더는 먼저 이전 상태 $s_{t-1}$와 이전 출력 토큰 $y_{t-1}$만을 사용하는 일반적인 순환 전이를 통해 은닉 상태를 $s_t$로 업데이트합니다. $$s_t = \text{RNN}(s_{t-1}, y_{t-1})$$
- 정렬 점수 계산 (곱산/승법):
루옹은 세 가지 대안 점수 함수를 제안했습니다. 가장 널리 사용되는 것은 행렬 곱셈을 사용하는 General(일반) 형태입니다.
- General: $e_{t, j} = s_t^T W_a h_j$
- Dot: $e_{t, j} = s_t^T h_j$ (차원이 같다고 가정)
- Concat: $e_{t, j} = v_a^T \tanh(W_a [s_t; h_j])$ 곱산 어텐션은 고도로 최적화된 행렬 곱셈 연산을 사용할 수 있으므로, 합산 어텐션에 비해 연산 속도가 빠르고 메모리 효율적입니다.
- 어텐션 가중치 계산 (Softmax): $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$
- 동적 컨텍스트 벡터 생성: $$c_t = \sum_j \alpha_{t, j} h_j$$
- 어텐셔널 은닉 상태(Attentional Hidden State) 계산: 예측에 디코더 상태를 직접 사용하는 대신, 컨텍스트 벡터 $c_t$와 현재 상태 $s_t$를 선형 레이어와 $\tanh$ 활성화 함수로 결합하여 어텐셔널 은닉 상태 $\tilde{s}_t$를 생성합니다. $$\tilde{s}_t = \tanh(W_c [c_t; s_t])$$
- 토큰 예측: 어텐셔널 은닉 상태 $\tilde{s}t$를 사용하여 최종 예측을 생성합니다. $$p(y_t | y{<t}, x) = \text{softmax}(W_s \tilde{s}_t)$$
아키텍처 비교
| 특징 | 바흐다나우(합산/가법) 어텐션 | 루옹(곱산/승법) 어텐션 |
|---|---|---|
| 수학적 점수 | 피드포워드 신경망 사용: $v_a^T \tanh(W_a s_{t-1} + U_a h_j)$ | 내적 또는 행렬 곱셈 사용: $s_t^T W_a h_j$ |
| 사용되는 디코더 상태 | 이전 디코더 상태 $s_{t-1}$ 사용. | 현재 디코더 상태 $s_t$ 사용. |
| 연산 속도 및 복잡도 | 복잡하고 느리지만 유연성이 높음. | 빠르고 단순하며 효율성이 극대화됨. |
5. 기술적 유산: 어텐션에서 트랜스포머로
어텐션 메커니즘은 원래 순환 신경망(RNN)을 보완하기 위한 부가 장치로 고안되었습니다. 하지만 연구자들은 곧 어텐션 계층이 핵심적인 연산을 전담하고 있으며, 순환 구조(RNN/LSTM)는 토큰을 순차적으로 처리해야만 하므로 오히려 계산상의 병목을 유발한다는 사실을 깨달았습니다.
그 결과 2017년에 연구자들은 역사적인 논문인 **“Attention Is All You Need”**를 통해 트랜스포머(Transformer) 아키텍처를 발표했습니다. 트랜스포머는 RNN을 완전히 배제하고 오직 셀프 어텐션(Self-Attention) 메커니즘만을 활용해 시퀀스 전체를 병렬로 처리했습니다.
이 혁신은 GPT-4, Gemini, Claude 등 현대 대규모 언어 모델(LLM)의 핵심 근간이 되었으며, 어텐션이 오늘날 자연어 처리 분야에서 가장 강력한 핵심 개념임을 증명하고 있습니다.