شرح بنية Sequence-to-Sequence وآلية الانتباه (Attention Mechanism) بالتفصيل
في مجال معالجة اللغة الطبيعية (NLP) والذكاء الاصطناعي، شهدت القدرة على ترجمة اللغات، وتلخيص المقالات، وتوليد الردود الحوارية ثورة حقيقية. وفي قلب هذا التحول تكمن بنية Sequence-to-Sequence (Seq2Seq) وآلية الانتباه (Attention Mechanism) الرائدة.
قبل ظهور نماذج Transformer الحديثة، نجح هذان الابتكاران في حل أحد أكبر تحديات التعلم العميق: كيفية ربط تسلسلات المدخلات بتسلسلات المخرجات عندما تختلف أطوالها.
1. التأسيس: ما هي بنية Sequence-to-Sequence (Seq2Seq)؟
تم تقديم نموذج Sequence-to-Sequence (Seq2Seq) في عام 2014 من قبل باحثين في Google وآخرين، وهو عبارة عن إطار عمل يعتمد على المشفر والمفكك (Encoder-Decoder) ومصمم لمعالجة البيانات المتسلسلة. ويستخدم على نطاق واسع في المهام التي لا يتطابق فيها طول تسلسل المدخلات مع طول تسلسل المخرجات، مثل:
- الترجمة الآلية: ترجمة “How are you؟” (3 كلمات) إلى العربية “كيف حالك؟” (كلمتان) أو الإسبانية “¿Cómo estás؟” (كلمتان).
- تلخيص النصوص: ضغط مقال مكون من 500 كلمة إلى ملخص مكون من 50 كلمة.
- أنظمة الإجابة عن الأسئلة: ربط تسلسل الأسئلة بتسلسل الإجابات المناسبة.
آلية المشفر والمفكك (Encoder-Decoder)
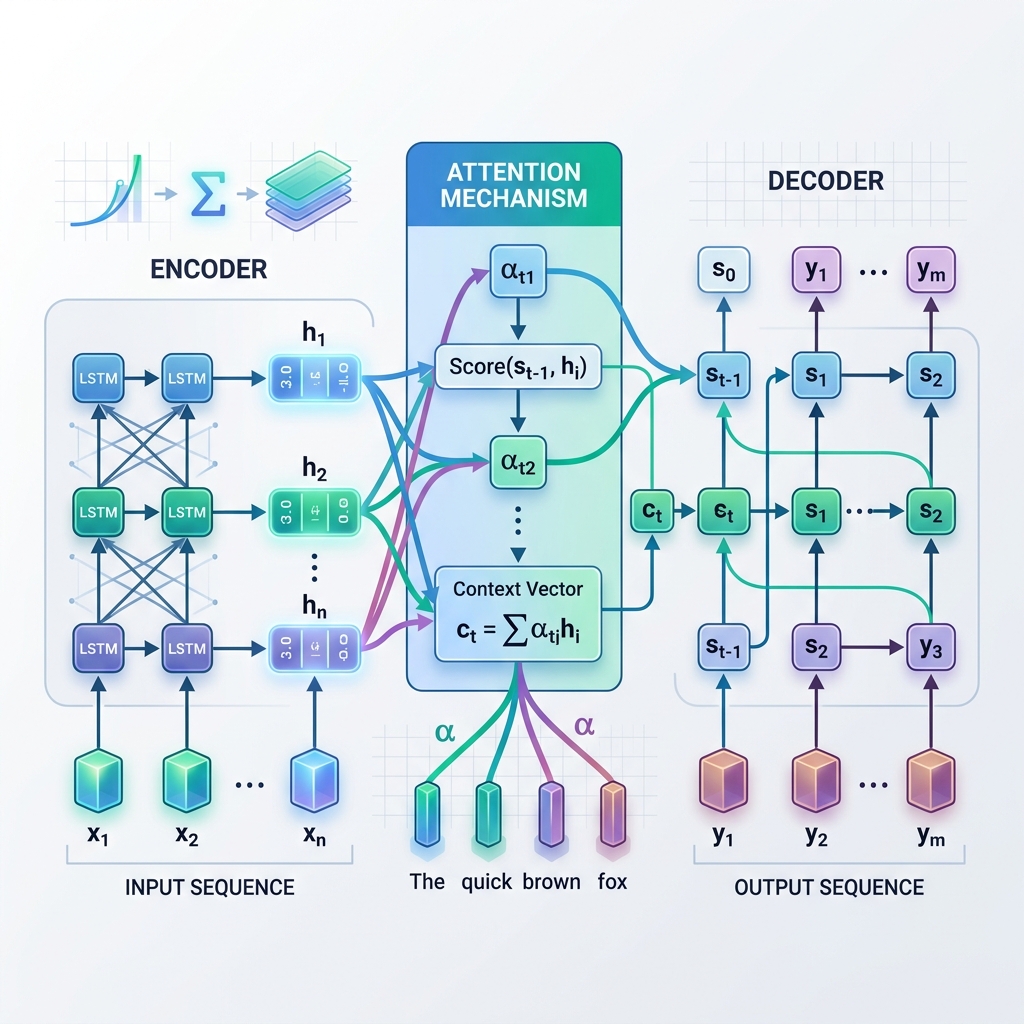
يتكون نموذج Seq2Seq القياسي من شبكتين عصبيتين متكررتين (RNNs)، وعادة ما تكونان شبكات الذاكرة الطويلة قصيرة المدى (LSTM) أو الوحدات المتكررة ذات البوابة (GRU):
- المشفر (Encoder): يعالج تسلسل المدخلات رمزاً تلو الآخر (token by token). وفي كل خطوة، يقوم بتحديث حالته المخفية بناءً على رمز الإدخال الحالي والحالة المخفية السابقة. وبمجرد معالجة المدخلات بالكامل، يتم التقاط الحالة المخفية النهائية للمشفر. تسمى هذه الحالة النهائية بـ متجه السياق (Context Vector) (أو متجه عنق الزجاجة).
- المفكك (Decoder): يأخذ متجه السياق كحالة مخفية أولية له ويولد تسلسل المخرجات رمزاً تلو الآخر بشكل ذاتي الانحدار. وفي كل خطوة، يتنبأ بالكلمة التالية بناءً على حالته المخفية الحالية والكلمة التي تم توليدها سابقاً.
2. مشكلة عنق الزجاجة (Information Bottleneck)
على الرغم من أن نموذج المشفر والمفكك الكلاسيكي كان بمثابة اختراق كبير، إلا أنه عانى من قيد أساسي يُعرف باسم عنق زجاجة المعلومات.
في نموذج Seq2Seq القياسي، يُجبر المشفر على ضغط المعنى الكامل لجملة الإدخال—سواء كانت تتكون من 5 كلمات أو 100 كلمة—في متجه سياق واحد ثابت الحجم.
ونتيجة لذلك:
- فقدان الذاكرة طويلة المدى: بالنسبة للجمل الطويلة، يتم نسيان الأجزاء الأولى من التسلسل بحلول الوقت الذي يصل فيه المشفر إلى النهاية.
- تراجع الأداء: تنخفض جودة الترجمة أو التلخيص بشكل كبير مع زيادة طول جملة الإدخال.
إن ضغط فقرة معقدة في متجه واحد يعادل محاولة تلخيص فصل كامل من كتاب في جملة واحدة قبل ترجمته، مما يؤدي حتماً إلى فقدان المعلومات الحيوية.
3. آلية الانتباه (Attention): تحول جذري في المفاهيم
لحل مشكلة عنق زجاجة المعلومات، قدم ديزميتري باهداناو (Dzmitry Bahdanau) وزملاؤه آلية الانتباه في عام 2015.
بدلاً من الاعتماد فقط على متجه سياق ثابت واحد من الخطوة النهائية للمشفر، يتيح الانتباه للمفكك “النظر إلى الوراء” في جميع الحالات المخفية المتوسطة للمشفر في كل خطوة من عملية فك التشفير. هذا يعني أن النموذج يركز ديناميكياً (يوجه انتباهه) إلى أجزاء مختلفة من تسلسل الإدخال اعتماداً على الكلمة التي يقوم بتوليدها حالياً.
كيف تعمل آلية الانتباه: خطوة بخطوة
عند كل خطوة فك تشفير $t$:
- حساب درجات المحاذاة ($e_{t, j}$): يقارن النموذج حالة المفكك المخفية الحالية $s_{t-1}$ مع كل حالة مشفر مخفية $h_j$ لقياس مدى ارتباط حالة المشفر $j$ بخطوة المفكك الحالية. $$e_{t, j} = \text{score}(s_{t-1}, h_j)$$
- حساب أوزان الانتباه ($\alpha_{t, j}$): يتم تطبيع درجات المحاذاة باستخدام دالة softmax لتحويلها إلى احتمالات (أوزان) مجموعها يساوي 1. $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$
- توليد متجه السياق الديناميكي ($c_t$): يتم حساب متجه السياق كمجموع موزون لجميع الحالات المخفية للمشفر. $$c_t = \sum_j \alpha_{t, j} h_j$$
- التنبؤ بالرمز (Token): يدمج المفكك متجه السياق الديناميكي $c_t$ مع حالته الحالية $s_t$ للتنبؤ برمز المخرجات التالي.
4. شرح تفصيلي لهيكل Seq2Seq وآليات الانتباه
لتقدير الهندسة الكامنة وراء هذه الآليات حقًا، دعنا نتتبع الخطوات الرياضية والتشغيلية لهيكل Sequence-to-Sequence الكلاسيكي أولاً، يليه كلا نهجي آلية الانتباه لـ Bahdanau (الجمعية) و Luong (الضربية).
النموذج الأساسي: شرح تفصيلي لهيكل Sequence-to-Sequence الكلاسيكي (بدون آلية الانتباه)
قبل استكشاف آلية الانتباه، دعنا نتتبع كيف يقوم هيكل Sequence-to-Sequence القياسي (المشفر والمفكك) ومعالجة المعلومات بشكل تسلسلي:
- مرحلة الترميز (Encoding Phase):
لسلسلة الإدخال $x_1, x_2, \dots, x_T$:
- عند كل خطوة زمنية $t$، تقوم الخلية المتكررة للمشفر (LSTM/GRU) بتحديث حالتها المخفية $h_t$ بناءً على رمز الإدخال الحالي $x_t$ والحالة المخفية السابقة $h_{t-1}$: $$h_t = \text{RNN}{\text{enc}}(x_t, h{t-1})$$
- توليد متجه السياق (Context Vector):
- الحالة المخفية الأخيرة للمشفر $h_T$ تعمل بمثابة متجه السياق $c$ (التمثيل الثابت لعنق الزجاجة): $$c = h_T$$
- تهيئة مرحلة تفكيك الترميز:
- يتم تهيئة الحالة المخفية الأولية $s_0$ لخلية مفكك الترميز مباشرة باستخدام متجه السياق $c$: $$s_0 = c$$
- خطوة التفكيك ذاتية الانحدار (Autoregressive Step):
- عند كل خطوة زمنية لتفكيك الترميز $t$، يقوم مفكك الترميز بتحديث حالته المخفية $s_t$ بناءً على الرمز المتوقع السابق $y_{t-1}$ والحالة المخفية السابقة $s_{t-1}$: $$s_t = \text{RNN}{\text{dec}}(y{t-1}, s_{t-1})$$
- التنبؤ بالرمز (Token Prediction):
- يتم حساب توزيع الاحتمالات للرمز التالي $y_t$ باستخدام طبقة خطية وتنشيط softmax المطبق على حالة مفكك الترميز $s_t$: $$p(y_t | y_{<t}) = \text{softmax}(W_y s_t + b_y)$$
النهج الأول: شرح آلية انتباه باهداناو (الجمعي)
يُطلق على انتباه باهداناو أيضاً اسم الانتباه الجمعي (Additive Attention) لأنه يقوم بحساب درجات المحاذاة (alignment scores) باستخدام طبقة شبكة عصبية للتغذية الأمامية (Feed-forward). وتعتمد عملياته على تدفق التدريب المرتبط بـ “الحالة السابقة” (previous-state):
- التهيئة والاعتمادية: عند خطوة فك التشفير $t$، تستخدم وحدة فك التشفير حالتها المخفية السابقة $s_{t-1}$ والحالات المخفية لوحدة الترميز $h_j$ (لجميع خطوات الإدخال $j$) لحساب الانتباه.
- حساب درجات المحاذاة (الجمعي): $$e_{t, j} = v_a^T \tanh(W_a s_{t-1} + U_a h_j)$$ حيث أن $W_a$ و $U_a$ عبارة عن مصفوفات أوزان قابلة للتدريب، تقوم بإسقاط حالة مفكك التشفير وحالات المرمز في مساحة مشتركة. ويمر مجموعهما عبر دالة التنشيط $\tanh$، ثم يُسقط الناتج إلى قيمة عددية (scalar) باستخدام متجه الأوزان $v_a$.
- حساب أوزان الانتباه (Softmax): $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$ يعمل هذا على تحويل درجات المحاذاة إلى توزيع احتمالي عبر تسلسل الإدخال.
- توليد متجه السياق الديناميكي: $$c_t = \sum_j \alpha_{t, j} h_j$$ هذا المتجه هو المجموع الموزون لحالات المرمز المخفية، ويمثل أجزاء تسلسل الإدخال التي يجب على النموذج التركيز عليها.
- تحديث الحالة المخفية لمفكك التشفير: يتم دمج متجه السياق $c_t$ مع التمثيل الرقمي (embedding) للرمز البرمجي المخرج السابق $y_{t-1}$، ويُمرر إلى الخلية التكرارية لمفكك التشفير لحساب حالة مفكك التشفير الحالية $s_t$: $$s_t = \text{RNN}(s_{t-1}, [c_t; y_{t-1}])$$
- التنبؤ بالرمز: تُستخدم الحالة الحالية $s_t$ للتنبؤ باحتمالية الرمز التالي.
النهج الثاني: شرح آلية انتباه لونج (الضربي)
يُشار إلى انتباه لونج (Luong Attention)، الذي تم تقديمه بعد فترة وجيزة من باهداناو، باسم الانتباه الضربي (Multiplicative Attention). ويتميز بتبسيط العمليات الحسابية والاعتماد على تدفق الحالة الحالية (current-state):
- تحديث الحالة المخفية لمفكك التشفير أولاً: عند خطوة فك التشفير $t$، يقوم مفكك التشفير أولاً بتحديث حالته المخفية إلى $s_t$ باستخدام الانتقال التكراري العادي، بالاعتماد فقط على الحالة السابقة $s_{t-1}$ والرمز المخرج السابق $y_{t-1}$: $$s_t = \text{RNN}(s_{t-1}, y_{t-1})$$
- حساب درجات المحاذاة (الضربي):
اقترح لونج ثلاث دوال حسابية بديلة لدرجات المحاذاة. الأكثر استخداماً هو النموذج العام (General) الذي يستخدم ضرب المصفوفات (ومن هنا جاءت التسمية بالضربي):
- العام (General): $e_{t, j} = s_t^T W_a h_j$
- الضرب النقطي (Dot): $e_{t, j} = s_t^T h_j$ (يفترض تساوي الأبعاد)
- الدمج (Concat): $e_{t, j} = v_a^T \tanh(W_a [s_t; h_j])$ يعتبر الانتباه الضربي أسرع حسابياً وأكثر كفاءة في استخدام المساحة من الانتباه الجمعي، لأنه يعتمد على عمليات ضرب المصفوفات عالية التحسين.
- حساب أوزان الانتباه (Softmax): $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$
- توليد متجه السياق الديناميكي: $$c_t = \sum_j \alpha_{t, j} h_j$$
- حساب الحالة المخفية للانتباه: بدلاً من استخدام حالة مفكك التشفير مباشرة للتنبؤ، يتم دمج متجه السياق $c_t$ والحالة الحالية $s_t$ باستخدام طبقة خطية وتنشيط $\tanh$ لإنتاج حالة مخفية ديناميكية للانتباه $\tilde{s}_t$: $$\tilde{s}_t = \tanh(W_c [c_t; s_t])$$
- التنبؤ بالرمز: تُستخدم الحالة المخفية للانتباه $\tilde{s}t$ لتوليد التنبؤ النهائي: $$p(y_t | y{<t}, x) = \text{softmax}(W_s \tilde{s}_t)$$
مقارنة معمارية
| الميزة | انتباه باهداناو (الجمعي / Additive) | انتباه لونج (الضربي / Multiplicative) |
|---|---|---|
| النتيجة الرياضية | يستخدم شبكة تغذية أمامية: $v_a^T \tanh(W_a s_{t-1} + U_a h_j)$ | يستخدم الضرب النقطي أو ضرب المصفوفات: $s_t^T W_a h_j$ |
| حالة وحدة فك التشفير المستخدمة | يستخدم حالة وحدة فك التشفير السابقة $s_{t-1}$. | يستخدم حالة وحدة فك التشفير الحالية $s_t$. |
| الحساب | أكثر تعقيداً، وأبطأ ولكنه مرن للغاية. | أسرع، وأبسط، وفعال للغاية. |
5. الإرث العلمي: من آلية الانتباه إلى نماذج Transformer
تم تصميم آلية الانتباه في البداية كأداة إضافية لتحسين الشبكات المتكررة RNNs. ومع ذلك، سرعان ما أدرك الباحثون أن طبقات الانتباه كانت تقوم بكل العمل الشاق، في حين كانت الهياكل المتكررة (RNN/LSTM) تعمل كعنق زجاجة حسابي لأنها تضطر إلى معالجة الرموز بشكل تسلسلي متتابع.
وفي عام 2017، نشر الباحثون الورقة البحثية الشهيرة “Attention Is All You Need”، والتي قدمت بنية Transformer. ألغت هذه البنية الشبكات المتكررة تماماً، واعتمدت فقط على الانتباه الذاتي (Self-Attention) لمعالجة التسلسلات بالكامل على التوازي.
هذا الاختراق العلمي هو الأساس الذي تقوم عليه نماذج اللغة الكبيرة الحديثة (LLMs) مثل GPT-4 وGemini وClaude، مما يثبت أن الانتباه هو بالفعل المفهوم الأكثر قوة وتأثيراً في معالجة اللغة الطبيعية الحديثة.