Démystifier l'architecture Sequence-to-Sequence et le mécanisme d'attention
Dans le paysage du traitement du langage naturel (NLP) et de l’intelligence artificielle, la capacité à traduire des langues, à résumer des articles et à générer des réponses conversationnelles a connu une véritable révolution. Au cœur de cette transformation se trouvent l’architecture Sequence-to-Sequence (Seq2Seq) et le révolutionnaire Mécanisme d’Attention.
Avant l’avènement des Transformers modernes, ces deux innovations ont résolu l’un des plus grands défis du deep learning : faire correspondre des séquences d’entrée à des séquences de sortie lorsque leurs longueurs diffèrent.
1. Les fondations : Qu’est-ce que Sequence-to-Sequence (Seq2Seq) ?
Introduit en 2014 par des chercheurs de Google et d’autres institutions, le modèle Sequence-to-Sequence (Seq2Seq) est une structure encodeur-décodeur (encoder-decoder) conçue pour traiter des données séquentielles. Il est largement utilisé pour des tâches où la longueur de la séquence d’entrée ne correspond pas à celle de la séquence de sortie, telles que :
- La traduction automatique : Traduire “How are you?” (3 mots) en français “Comment allez-vous ?” (3 mots) ou en espagnol “¿Cómo estás?” (2 mots).
- La synthèse de texte : Compresser un article de 500 mots en un résumé de 50 mots.
- Les systèmes de questions-réponses : Associer une séquence de questions à une séquence de réponses.
Le mécanisme Encodeur-Décodeur
Le modèle Seq2Seq standard se compose de deux réseaux de neurones récurrents (RNN), généralement des LSTM (Long Short-Term Memory) ou des GRU (Gated Recurrent Units) :
- L’Encodeur : Traite la séquence d’entrée jeton par jeton (token by token). À chaque étape, il met à jour son état caché en fonction du jeton d’entrée actuel et de l’état caché précédent. Une fois l’intégralité de l’entrée traitée, le dernier état caché de l’encodeur est capturé. Cet état final est appelé Vecteur de Contexte (ou vecteur goulot d’étranglement).
- Le Décodeur : Prend le vecteur de contexte comme état caché initial et génère la séquence de sortie jeton par jeton de manière autorégressive. À chaque étape, il prédit le mot suivant en fonction de son état caché actuel et du mot précédemment généré.
2. Le problème du goulot d’étranglement (Information Bottleneck)
Bien que le modèle classique Encodeur-Décodeur ait constitué une avancée majeure, il souffrait d’une limitation fondamentale appelée goulot d’étranglement de l’information.
Dans un modèle Seq2Seq standard, l’encodeur est contraint de compresser toute la signification d’une phrase d’entrée (qu’elle compte 5 ou 100 mots) en un seul vecteur de contexte de taille fixe.
En conséquence :
- Perte de mémoire à long terme : Pour les phrases longues, les premières parties de la séquence sont oubliées au moment où l’encodeur atteint la fin.
- Dégradation des performances : La qualité de la traduction ou du résumé diminue considérablement à mesure que la longueur de la phrase d’entrée augmente.
Compresser un paragraphe complexe en un seul vecteur équivaut à tenter de résumer un chapitre entier d’un livre en une seule phrase avant de le traduire. L’information est inévitablement perdue.
3. Le mécanisme d’attention : un changement de paradigme
Pour résoudre le problème du goulot d’étranglement, Dzmitry Bahdanau et ses collègues ont introduit le Mécanisme d’Attention en 2015.
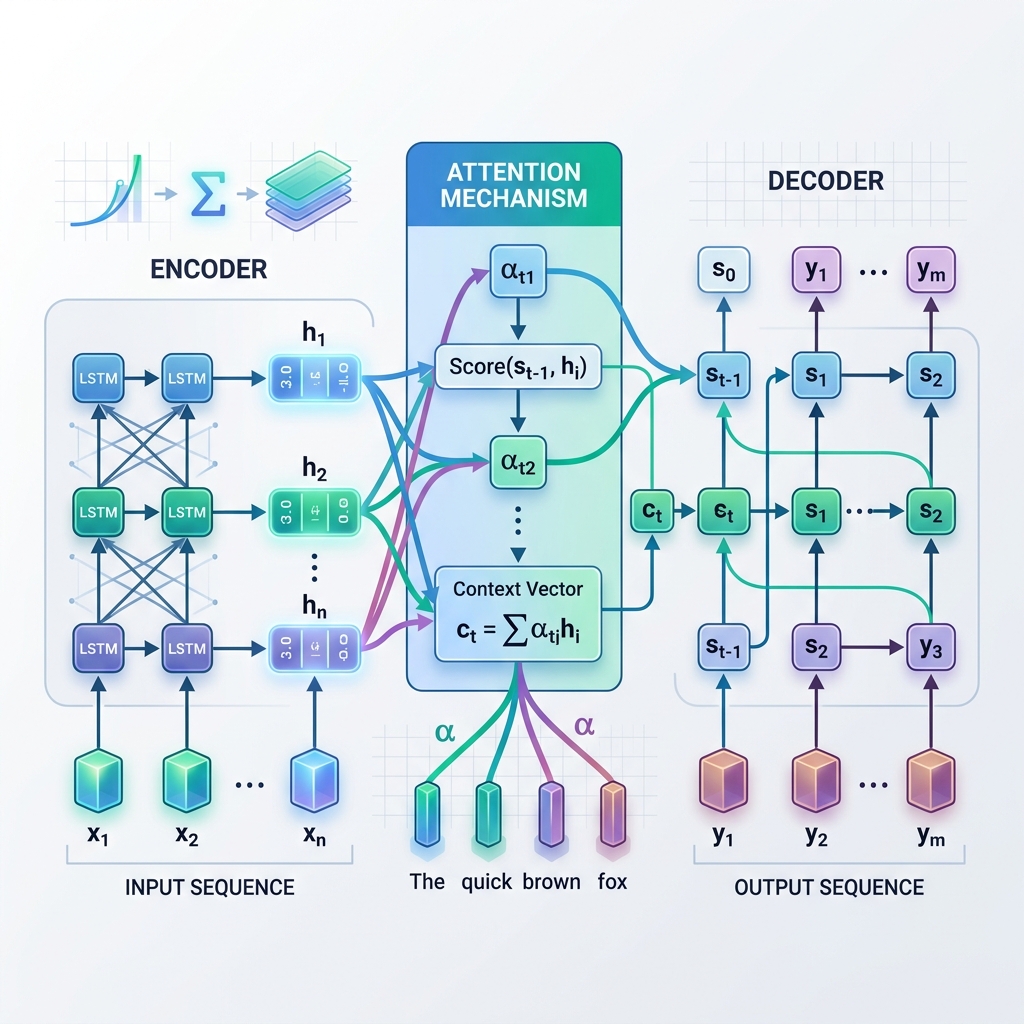
Au lieu de s’appuyer uniquement sur un vecteur de contexte unique et statique issu de l’étape finale de l’encodeur, l’attention permet au décodeur de « regarder en arrière » vers tous les états cachés intermédiaires de l’encodeur à chaque étape du processus de décodage. Cela signifie que le modèle se concentre de manière dynamique (prête attention) sur différentes parties de la séquence d’entrée en fonction du mot qu’il est en train de générer.
Comment fonctionne l’attention : étape par étape
À chaque étape de décodage $t$ :
- Calcul des scores d’alignement ($e_{t, j}$) : Le modèle compare l’état caché actuel du décodeur $s_{t-1}$ avec chaque état caché de l’encodeur $h_j$ pour mesurer la pertinence de l’état de l’encodeur $j$ par rapport à l’étape de décodage actuelle. $$e_{t, j} = \text{score}(s_{t-1}, h_j)$$
- Calcul des poids d’attention ($\alpha_{t, j}$) : Les scores d’alignement sont normalisés à l’aide d’une fonction softmax pour les convertir en probabilités (poids) dont la somme est égale à 1. $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$
- Génération du vecteur de contexte dynamique ($c_t$) : Le vecteur de contexte est calculé comme la somme pondérée de tous les états cachés de l’encodeur. $$c_t = \sum_j \alpha_{t, j} h_j$$
- Prédiction du jeton : Le décodeur combine le vecteur de contexte dynamique $c_t$ avec son état actuel $s_t$ pour prédire le jeton de sortie suivant.
4. Guide détaillé des mécanismes Seq2Seq et d’attention
Pour apprécier pleinement l’ingénierie derrière ces mécanismes, retraçons les étapes mathématiques et opérationnelles de l’architecture classique Sequence-to-Sequence, suivies des approches d’attention de Bahdanau (additive) et Luong (multiplicative).
Référence : Guide de l’architecture classique Sequence-to-Sequence (sans attention)
Avant d’explorer l’attention, retraçons comment l’architecture standard Sequence-to-Sequence (Encoder-Decoder) traite les informations de manière séquentielle :
- Phase d’Encodage :
Pour une séquence d’entrée $x_1, x_2, \dots, x_T$ :
- À chaque étape $t$, la cellule récurrente de l’Encodeur (LSTM/GRU) met à jour son état caché $h_t$ en fonction du jeton d’entrée actuel $x_t$ et de l’état caché précédent $h_{t-1}$ : $$h_t = \text{RNN}{\text{enc}}(x_t, h{t-1})$$
- Génération du Vecteur de Contexte :
- L’état caché final de l’encodeur $h_T$ sert de vecteur de contexte $c$ (la représentation statique du goulot d’étranglement) : $$c = h_T$$
- Initialisation de la Phase de Décodage :
- L’état caché initial $s_0$ de la cellule du Décodeur est directement initialisé avec le vecteur de contexte $c$ : $$s_0 = c$$
- Étape Autorégressive du Décodeur :
- À chaque étape de décodage $t$, le Décodeur met à jour son état caché $s_t$ en fonction du jeton prédit précédent $y_{t-1}$ et de l’état caché précédent $s_{t-1}$ : $$s_t = \text{RNN}{\text{dec}}(y{t-1}, s_{t-1})$$
- Prédiction du Jeton :
- La distribution de probabilité pour le prochain jeton $y_t$ est calculée à l’aide d’une couche linéaire et d’une activation softmax appliquée à l’état du décodeur $s_t$ : $$p(y_t | y_{<t}) = \text{softmax}(W_y s_t + b_y)$$
Approche 1 : Guide de l’attention de Bahdanau (additive)
L’attention de Bahdanau est également appelée attention additive car elle calcule les scores d’alignement à l’aide d’une couche de réseau neuronal à propagation avant. Elle fonctionne selon un flux de dépendance à “l’état précédent” :
- Initialisation / Dépendance : À l’étape de décodage $t$, le décodeur utilise son état caché précédent $s_{t-1}$ et les états cachés de l’encodeur $h_j$ (pour toutes les étapes d’entrée $j$) pour calculer l’attention.
- Calculer les scores d’alignement (Additif) : $$e_{t, j} = v_a^T \tanh(W_a s_{t-1} + U_a h_j)$$ Ici, $W_a$ et $U_a$ sont des matrices de poids configurables qui projettent l’état du décodeur et les états de l’encodeur dans un espace partagé. Leur somme est passée à travers une fonction d’activation $\tanh$, puis projetée sur un scalaire à l’aide du vecteur de poids $v_a$.
- Calculer les poids d’attention (Softmax) : $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$ Cela normalise les scores d’alignement en une distribution de probabilité sur la séquence d’entrée.
- Générer le vecteur de contexte dynamique : $$c_t = \sum_j \alpha_{t, j} h_j$$ Il s’agit d’une somme pondérée des états cachés de l’encodeur, représentant les parties de la séquence d’entrée sur lesquelles le modèle doit se concentrer.
- Mettre à jour l’état caché du décodeur : Le vecteur de contexte $c_t$ is concaténé avec l’embedding du token de sortie précédent $y_{t-1}$, et transmis à la cellule récurrente du décodeur pour calculer l’état actuel du décodeur $s_t$ : $$s_t = \text{RNN}(s_{t-1}, [c_t; y_{t-1}])$$
- Prédire le token : L’état actuel $s_t$ est utilisé pour prédire la probabilité du token suivant.
Approche 2 : Guide de l’attention de Luong (multiplicative)
L’attention de Luong, introduite peu après celle de Bahdanau, est appelée attention multiplicative. Elle simplifie le calcul et repose sur un flux de dépendance à “l’état actuel” :
- Mettre d’abord à jour l’état caché du décodeur : À l’étape de décodage $t$, le décodeur met d’abord à jour son état caché en $s_t$ en utilisant la transition récurrente normale, en utilisant uniquement l’état précédent $s_{t-1}$ et le token de sortie précédent $y_{t-1}$ : $$s_t = \text{RNN}(s_{t-1}, y_{t-1})$$
- Calculer les scores d’alignement (Multiplicatif) :
Luong a proposé trois fonctions de score alternatives. La plus couramment utilisée est la forme General, qui utilise une multiplication matricielle (d’où l’appellation multiplicative) :
- General : $e_{t, j} = s_t^T W_a h_j$
- Dot : $e_{t, j} = s_t^T h_j$ (suppose une dimensionnalité égale)
- Concat : $e_{t, j} = v_a^T \tanh(W_a [s_t; h_j])$ L’attention multiplicative est plus rapide à calculer et plus économe en espace que l’attention additive car elle peut être calculée à l’aide d’opérations de multiplication matricielle hautement optimisées.
- Calculer les poids d’attention (Softmax) : $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$
- Générer le vecteur de contexte dynamique : $$c_t = \sum_j \alpha_{t, j} h_j$$
- Calculer l’état caché d’attention : Au lieu d’utiliser l’état du décodeur directement pour la prédiction, le vecteur de contexte $c_t$ et l’état actuel $s_t$ sont combinés à l’aide d’une couche linéaire et d’une activation $\tanh$ pour produire un état caché d’attention $\tilde{s}_t$ : $$\tilde{s}_t = \tanh(W_c [c_t; s_t])$$
- Prédire le token : L’état caché d’attention $\tilde{s}t$ est utilisé pour générer la prédiction finale : $$p(y_t | y{<t}, x) = \text{softmax}(W_s \tilde{s}_t)$$
Comparaison Architecturale
| Caractéristique | Attention de Bahdanau (Additive) | Attention de Luong (Multiplicative) |
|---|---|---|
| Score mathématique | Utilise un réseau à propagation avant : $v_a^T \tanh(W_a s_{t-1} + U_a h_j)$ | Utilise le produit scalaire ou la multiplication matricielle : $s_t^T W_a h_j$ |
| État du décodeur utilisé | Utilise l’état précédent du décodeur $s_{t-1}$. | Utilise l’état actuel du décodeur $s_t$. |
| Calcul | Plus complexe, plus lent mais très flexible. | Plus rapide, plus simple et très efficace. |
5. L’héritage : De l’attention aux Transformers
Le mécanisme d’attention a d’abord été conçu comme un module complémentaire pour améliorer les RNN. Cependant, les chercheurs ont rapidement réalisé que les couches d’attention effectuaient tout le travail difficile, tandis que les structures récurrentes (RNN/LSTM) agissaient comme un goulot d’étranglement informatique car elles devaient traiter les jetons de manière séquentielle.
En 2017, les chercheurs ont publié l’article fondateur « Attention Is All You Need », présentant l’architecture Transformer. Le Transformer a complètement abandonné les RNN, s’appuyant uniquement sur la Self-Attention (Auto-attention) pour traiter des séquences entières en parallèle.
Cette percée est le fondement des grands modèles de langage (LLM) modernes comme GPT-4, Gemini et Claude, prouvant que l’attention est bel et bien le concept le plus puissant du NLP moderne.