رمزگشایی از معماری Sequence-to-Sequence و مکانیزم توجه (Attention)
در دنیای پردازش زبان طبیعی (NLP) و هوش مصنوعی، توانایی ترجمه زبانها، خلاصهسازی مقالات و تولید پاسخهای گفتگو محور دچار یک انقلاب بزرگ شده است. در قلب این تحول عظیم، معماری Sequence-to-Sequence (Seq2Seq) و مکانیزم توجه (Attention Mechanism) پیشگام قرار دارد.
قبل از ظهور ترنسفورمرهای مدرن، این دو نوآوری بزرگ یکی از چالشبرانگیزترین مسائل یادگیری عمیق را حل کردند: نگاشت توالیهای ورودی به توالیهای خروجی در شرایطی که طول آنها با یکدیگر متفاوت است.
۱. پایهگذاری: معماری Sequence-to-Sequence (Seq2Seq) چیست؟
مدل Sequence-to-Sequence (Seq2Seq) که در سال ۲۰۱۴ توسط پژوهشگران گوگل و دیگر موسسات معرفی شد، یک فریمورک رمزگذار-رمزگشا (Encoder-Decoder) است که برای پردازش دادههای متوالی طراحی شده است. این معماری به طور گسترده در کارهایی که طول توالی ورودی با طول توالی خروجی مطابقت ندارد استفاده میشود، مانند:
- ترجمه ماشینی: ترجمه عبارت “How are you؟” (۳ کلمه) به فارسی «چطور هستید؟» (۲ کلمه) یا اسپانیایی “¿Cómo estás؟” (۲ کلمه).
- خلاصهسازی متن: فشردهسازی یک مقاله ۵۰۰ کلمهای به یک خلاصه ۵۰ کلمهای.
- سیستمهای پاسخ به سؤال: نگاشت یک توالی از سؤالات به توالی پاسخهای متناسب.
مکانیزم رمزگذار-رمزگشا (Encoder-Decoder)
مدل استاندارد Seq2Seq از دو شبکه عصبی بازگشتی (RNN)، معمولاً شبکههای حافظه طولانی کوتاهمدت (LSTM) یا واحدهای بازگشتی دروازهدار (GRU) تشکیل شده است:
- رمزگذار (Encoder): توالی ورودی را توکن به توکن پردازش میکند. در هر گام زمان، حالت پنهان خود را بر اساس توکن ورودی فعلی و حالت پنهان قبلی بهروزرسانی میکند. پس از پردازش کامل ورودی، آخرین حالت پنهان رمزگذار ذخیره میشود. این حالت نهایی بردار سیاق (Context Vector) (یا بردار گلوگاه) نامیده میشود.
- رمزگشا (Decoder): بردار سیاق را به عنوان حالت پنهان اولیه خود میگیرد و توالی خروجی را به صورت خودکاهنده (autoregressive) توکن به توکن تولید میکند. در هر گام، کلمه بعدی را بر اساس حالت پنهان فعلی خود و کلمه تولید شده قبلی پیشبینی میکند.
۲. مشکل گلوگاه اطلاعات (Information Bottleneck)
اگرچه مدل کلاسیک رمزگذار-رمزگشا یک پیشرفت بزرگ بود، اما از یک محدودیت اساسی رنج میبرد که به عنوان گلوگاه اطلاعات شناخته میشود.
در یک مدل Seq2Seq استاندارد، رمزگذار مجبور است تمام معنای جمله ورودی را—خواه ۵ کلمه باشد یا ۱۰۰ کلمه—در یک بردار سیاق تکبعدی با اندازه ثابت فشرده کند.
در نتیجه:
- از دست رفتن حافظه بلندمدت: برای جملات طولانیتر، اطلاعات بخشهای ابتدایی توالی تا زمانی که رمزگذار به پایان جمله میرسد، کمرنگ یا فراموش میشوند.
- کاهش کیفیت عملکرد: کیفیت ترجمه یا خلاصهسازی با افزایش طول جمله ورودی به شدت افت میکند.
فشردهسازی یک پاراگراف پیچیده در یک بردار واحد مانند این است که بخواهید قبل از ترجمه یک فصل کامل از کتاب، آن را در یک جمله خلاصه کنید. اطلاعات به طور اجتنابناپذیری در این فرایند از دست میرود.
۳. مکانیزم توجه: یک تغییر پارادایم بزرگ
برای حل مشکل گلوگاه اطلاعات، دیمیتری باهداناو (Dzmitry Bahdanau) و همکارانش در سال ۲۰۱۵ مکانیزم توجه (Attention Mechanism) را معرفی کردند.
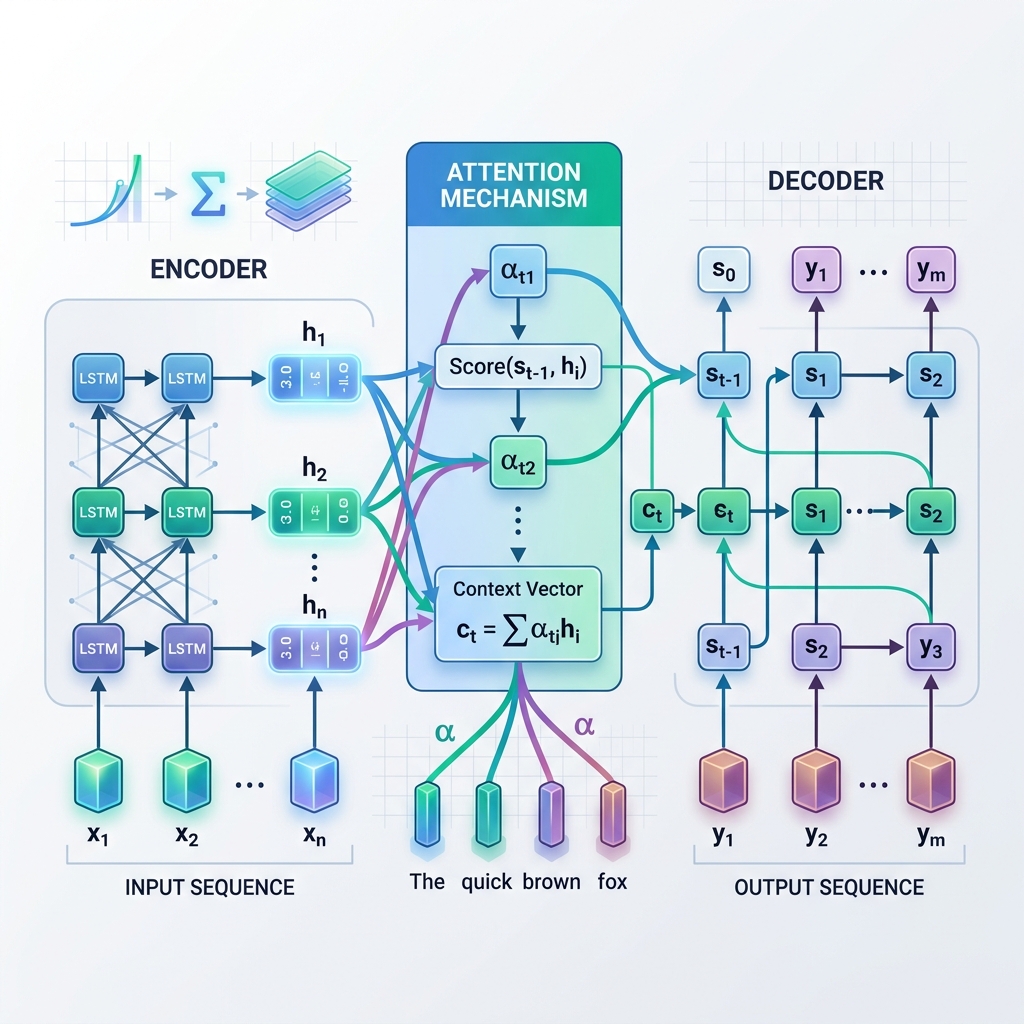
مکانیزم توجه به جای تکیه انحصاری بر یک بردار سیاق ایستا که از گام نهایی رمزگذار حاصل میشود، به رمزگشا اجازه میدهد تا در هر گام از فرآیند رمزگشایی، «به عقب نگاه کند» و به تمامی حالتهای پنهان میانی رمزگذار دسترسی داشته باشد. این بدان معناست که مدل بر اساس کلمهای که در حال حاضر تولید میکند، به طور پویا بر بخشهای مختلف توالی ورودی تمرکز (توجه) میکند.
مکانیزم توجه چگونه کار میکند: گام به گام
در هر گام رمزگشایی $t$:
- محاسبه امتیازهای تراز ($e_{t, j}$): مدل حالت پنهان فعلی رمزگشا $s_{t-1}$ را با تکتک حالتهای پنهان رمزگذار $h_j$ مقایسه میکند تا میزان ارتباط حالت رمزگذار $j$ را با گام فعلی رمزگشایی بسنجد. $$e_{t, j} = \text{score}(s_{t-1}, h_j)$$
- محاسبه وزنهای توجه ($\alpha_{t, j}$): امتیازهای تراز با استفاده از تابع softmax نرمالسازی میشوند تا به احتمالهایی (وزنها) تبدیل شوند که مجموع آنها برابر ۱ است. $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$
- تولید بردار سیاق پویا ($c_t$): بردار سیاق به عنوان مجموع وزنی تمام حالتهای پنهان رمزگذار محاسبه میشود. $$c_t = \sum_j \alpha_{t, j} h_j$$
- پیشبینی توکن: رمزگشا بردار سیاق پویا $c_t$ را با حالت فعلی خود $s_t$ ترکیب میکند تا توکن خروجی بعدی را پیشبینی کند.
۴. بررسی دقیق مکانیزمهای Seq2Seq و توجه
برای درک واقعی مهندسی پشت این مکانیزمها، ابتدا مراحل ریاضی و عملیاتی معماری کلاسیک Sequence-to-Sequence را دنبال میکنیم و سپس به رویکردهای توجه Bahdanau (افزایشی) و Luong (ضربکننده) میپردازیم.
مبنا: بررسی معماری کلاسیک Sequence-to-Sequence (بدون مکانیزم توجه)
قبل از بررسی مکانیزم توجه، بیایید دنبال کنیم که چگونه معماری استاندارد Sequence-to-Sequence (رمزگذار-رمزگشا) اطلاعات را به صورت متوالی پردازش میکند:
۱. مرحله رمزگذاری (Encoding Phase): برای دنباله ورودی $x_1, x_2, \dots, x_T$:
- در هر گام زمانی $t$، سلول بازگشتی رمزگذار (LSTM/GRU) حالت مخفی خود $h_t$ را بر اساس توکن ورودی فعلی $x_t$ และ حالت مخفی قبلی $h_{t-1}$ بهروزرسانی میکند: $$h_t = \text{RNN}{\text{enc}}(x_t, h{t-1})$$ ۲. تولید بردار سیاق (Context Vector):
- آخرین حالت مخفی رمزگذار $h_T$ به عنوان بردار سیاق $c$ (نمایش گلوگاه ثابت) عمل میکند: $$c = h_T$$ ۳. مقداردهی اولیه مرحله رمزگشایی:
- حالت مخفی اولیه $s_0$ سلول رمزگشا مستقیماً با بردار سیاق $c$ مقداردهی اولیه میشود: $$s_0 = c$$ ۴. گام خودگردان رمزگشا (Autoregressive Step):
- در هر گام زمانی رمزگشایی $t$، رمزگشا حالت مخفی خود $s_t$ را بر اساس توکن پیشبینیشده قبلی $y_{t-1}$ و حالت مخفی قبلی $s_{t-1}$ بهروزرسانی میکند: $$s_t = \text{RNN}{\text{dec}}(y{t-1}, s_{t-1})$$ ۵. پیشبینی توکن:
- توزیع احتمال برای توکن بعدی $y_t$ با استفاده از یک لایه خطی و تابع فعالسازی softmax اعمالشده روی حالت رمزگشا $s_t$ محاسبه میشود: $$p(y_t | y_{<t}) = \text{softmax}(W_y s_t + b_y)$$
رویکرد ۱: بررسی توجه باهداناو (جمعشونده)
توجه باهداناو را توجه جمعشونده (additive attention) نیز مینامند زیرا امتیازهای همترازی (alignment scores) را با استفاده از یک لایه شبکه عصبی پیشخور (feed-forward) محاسبه میکند. این رویکرد بر اساس جریان وابستگی به «وضعیت قبلی» عمل میکند:
- مقداردهی اولیه / وابستگی: در مرحله رمزگشایی $t$، رمزگشا از وضعیت پنهان قبلی خود $s_{t-1}$ و وضعیتهای پنهان رمزگذار $h_j$ (برای تمام مراحل ورودی $j$) جهت محاسبه توجه استفاده میکند.
- محاسبه امتیازهای همترازی (جمعشونده): $$e_{t, j} = v_a^T \tanh(W_a s_{t-1} + U_a h_j)$$ در اینجا، $W_a$ و $U_a$ ماتریسهای وزن یادگیریپذیر هستند که وضعیت رمزگشا و وضعیتهای رمزگذار را به یک فضای مشترک انتقال میدهند. مجموع آنها از یک تابع فعالساز $\tanh$ عبور کرده و سپس با استفاده از بردار وزن $v_a$ به یک مقدار نردهای (scalar) تبدیل میشود.
- محاسبه وزنهای توجه (Softmax): $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$ این مرحله امتیازهای همترازی را به یک توزیع احتمال در طول دنباله ورودی نرمال میکند.
- تولید بردار بافت پویا: $$c_t = \sum_j \alpha_{t, j} h_j$$ این یک مجموع وزندار از وضعیتهای پنهان رمزگذار است که نشاندهنده بخشهایی از دنباله ورودی است که مدل باید روی آنها تمرکز کند.
- بهروزرسانی وضعیت پنهان رمزگشا: بردار بافت $c_t$ با امبدینگ توکن خروجی قبلی $y_{t-1}$ متصل (concatenate) شده و به سلول بازگشتی رمزگشا فرستاده میشود تا وضعیت فعلی رمزگشا $s_t$ را محاسبه کند: $$s_t = \text{RNN}(s_{t-1}, [c_t; y_{t-1}])$$
- پیشبینی توکن: وضعیت فعلی $s_t$ برای پیشبینی احتمال توکن بعدی استفاده میشود.
رویکرد ۲: بررسی توجه لونگ (ضربشونده)
توجه لونگ (Luong Attention) که مدت کوتاهی پس از باهداناو معرفی شد، به عنوان توجه ضربشونده (multiplicative attention) شناخته میشود. این رویکرد محاسبات را ساده کرده و به جریان وابستگی به «وضعیت فعلی» متکی است:
- ابتدا بهروزرسانی وضعیت پنهان رمزگشا: در مرحله رمزگشایی $t$، رمزگشا ابتدا وضعیت پنهان خود را با استفاده از انتقال بازگشتی عادی و تنها با استفاده از وضعیت قبلی $s_{t-1}$ و توکن خروجی قبلی $y_{t-1}$ به $s_t$ بهروز میکند: $$s_t = \text{RNN}(s_{t-1}, y_{t-1})$$
- محاسبه امتیازهای همترازی (ضربشونده):
لونگ سه تابع امتیاز جایگزین را پیشنهاد کرد. پرکاربردترین شکل، حالت General است که از ضرب ماتریسی استفاده میکند (از این رو ضربشونده نامیده میشود):
- General: $e_{t, j} = s_t^T W_a h_j$
- Dot: $e_{t, j} = s_t^T h_j$ (با فرض یکسان بودن ابعاد)
- Concat: $e_{t, j} = v_a^T \tanh(W_a [s_t; h_j])$ توجه ضربشونده از نظر محاسباتی سریعتر و از نظر حافظه کارآمدتر از توجه جمعشونده است زیرا میتواند با استفاده از عملیات ضرب ماتریسی بسیار بهینهسازیشده محاسبه شود.
- محاسبه وزنهای توجه (Softmax): $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$
- تولید بردار بافت پویا: $$c_t = \sum_j \alpha_{t, j} h_j$$
- محاسبه وضعیت پنهان توجه: به جای استفاده مستقیم از وضعیت رمزگشا برای پیشبینی، بردار بافت $c_t$ و وضعیت فعلی $s_t$ با استفاده از یک لایه خطی و فعالساز $\tanh$ ترکیب میشوند تا یک وضعیت پنهان توجه $\tilde{s}_t$ ایجاد کنند: $$\tilde{s}_t = \tanh(W_c [c_t; s_t])$$
- پیشبینی توکن: وضعیت پنهان توجه $\tilde{s}t$ برای پیشبینی نهایی استفاده میشود: $$p(y_t | y{<t}, x) = \text{softmax}(W_s \tilde{s}_t)$$
مقایسه معماری
| ویژگی | توجه باهداناو (جمعشونده) | توجه لونگ (ضربشونده) |
|---|---|---|
| امتیاز ریاضی | از یک شبکه پیشخور استفاده میکند: $v_a^T \tanh(W_a s_{t-1} + U_a h_j)$ | از ضرب نقطهای یا ضرب ماتریسی استفاده میکند: $s_t^T W_a h_j$ |
| وضعیت دکودر مورد استفاده | از وضعیت قبلی دکودر $s_{t-1}$ استفاده میکند. | از وضعیت فعلی دکودر $s_t$ استفاده میکند. |
| محاسبات | پیچیدهتر، کندتر اما بسیار انعطافپذیر. | سریعتر، سادهتر و بسیار کارآمد. |
۵. میراث علمی: از مکانیزم توجه تا ترنسفورمرها
مکانیزم توجه در ابتدا به عنوان ابزاری جانبی برای بهبود شبکههای بازگشتی (RNN) طراحی شد. با این حال، پژوهشگران خیلی زود متوجه شدند که لایههای توجه تمامی کارهای سنگین و اصلی را انجام میدهند، در حالی که ساختارهای بازگشتی (RNN/LSTM) به دلیل اینکه مجبور بودند توکنها را به صورت متوالی پردازش کنند، خود به یک گلوگاه محاسباتی تبدیل شده بودند.
در سال ۲۰۱۷، پژوهشگران مقاله معروف “Attention Is All You Need” را منتشر کردند که معماری انقلابی Transformer را معرفی نمود. ترنسفورمر به طور کامل شبکههای بازگشتی را کنار گذاشت و تنها بر مکانیزم توجه به خود (Self-Attention) برای پردازش موازی کل توالیها تکیه کرد.
این پیشرفت بزرگ، زیربنای مدلهای بزرگ زبانی مدرن (LLMs) مانند GPT-4، Gemini و Claude است و ثابت میکند که توجه، قدرتمندترین و کلیدیترین مفهوم در پردازش زبان طبیعی مدرن است.