Desmitificando la Arquitectura Sequence-to-Sequence y el Mecanismo de Atención
En el panorama del Procesamiento del Lenguaje Natural (NLP) y la Inteligencia Artificial, la capacidad de traducir idiomas, resumir artículos y generar respuestas conversacionales ha experimentado una revolución. En el corazón de esta transformación se encuentra la arquitectura Sequence-to-Sequence (Seq2Seq) y el pionero Mecanismo de Atención.
Antes del advenimiento de los Transformers modernos, estas dos innovaciones resolvieron uno de los mayores desafíos del aprendizaje profundo: mapear secuencias de entrada a secuencias de salida cuando sus longitudes difieren.
1. La Fundación: ¿Qué es Sequence-to-Sequence (Seq2Seq)?
Introducido en 2014 por investigadores de Google y otros, el modelo Sequence-to-Sequence (Seq2Seq) es un marco de codificador-decodificador (encoder-decoder) diseñado para procesar datos secuenciales. Se utiliza ampliamente en tareas donde la longitud de la secuencia de entrada no coincide con la longitud de la secuencia de salida, como:
- Traducción automática: Traducir “How are you?” (3 palabras) al español “¿Cómo estás?” (2 palabras) o al francés “Comment allez-vous?” (3 palabras).
- Resumen de texto: Comprimir un artículo de 500 palabras en un resumen de 50 palabras.
- Sistemas de preguntas y respuestas: Mapear una secuencia de preguntas a una secuencia de respuestas.
El mecanismo codificador-decodificador
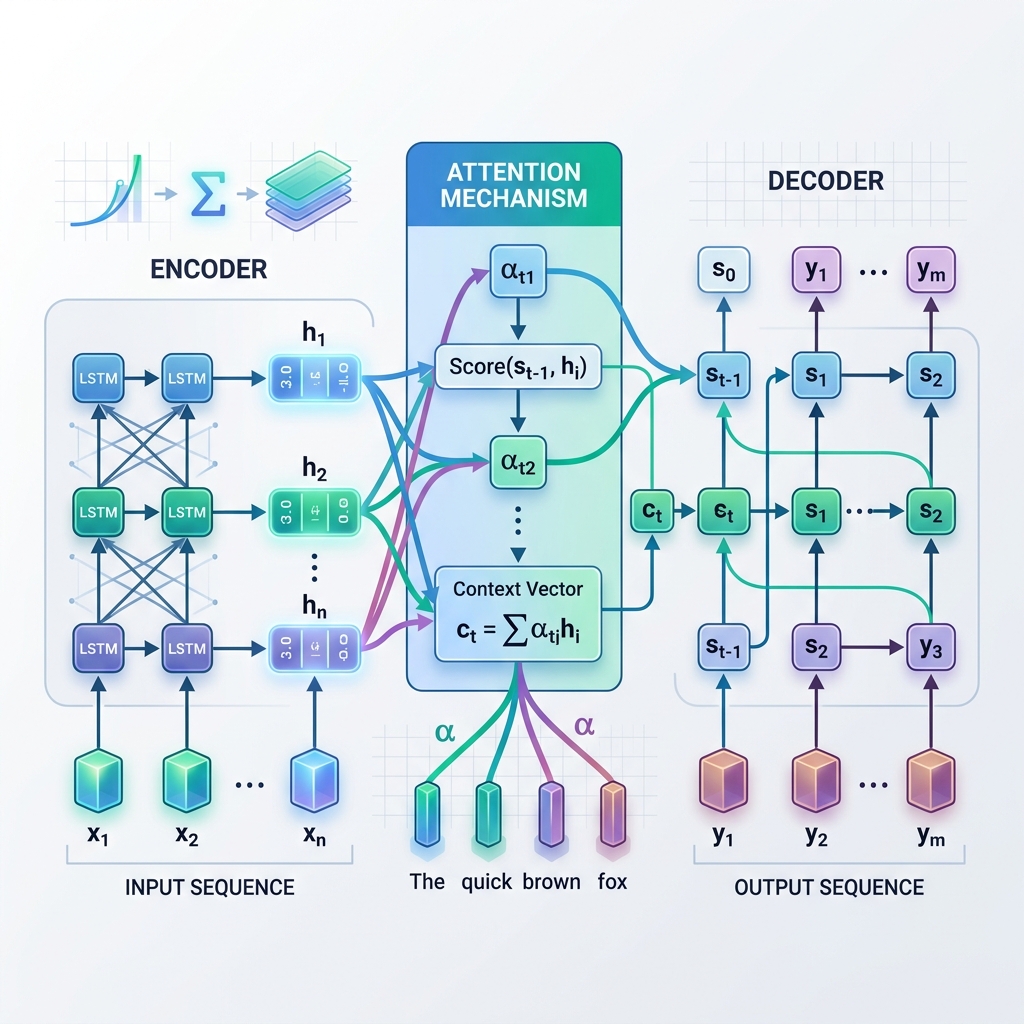
El modelo Seq2Seq estándar consta de dos redes neuronales recurrentes (RNN), típicamente LSTM (Long Short-Term Memory) o GRU (Gated Recurrent Units):
- El codificador (Encoder): Procesa la secuencia de entrada token por token. En cada paso, actualiza su estado oculto en función del token de entrada actual y del estado oculto anterior. Una vez que se procesa toda la entrada, se captura el estado oculto final del codificador. Este estado final se denomina Vector de Contexto (o vector de cuello de botella).
- El decodificador (Decoder): Toma el Vector de Contexto como su estado oculto inicial y genera la secuencia de salida token por token de forma autorregresiva. En cada paso, predice la siguiente palabra en función de su estado oculto actual y de la palabra generada anteriormente.
2. El problema del cuello de botella (Information Bottleneck)
Si bien el modelo clásico de codificador-decodificador fue un gran avance, sufrió una limitación fundamental conocida como el cuello de botella de la información.
En un modelo Seq2Seq estándar, el codificador se ve obligado a comprimir todo el significado de una oración de entrada (ya sea de 5 o 100 palabras) en un solo Vector de Contexto de tamaño fijo.
Como resultado:
- Pérdida de memoria a largo plazo: Para oraciones más largas, las primeras partes de la secuencia se olvidan para cuando el codificador llega al final.
- Degradación del rendimiento: La calidad de la traducción o del resumen disminuye significativamente a medida que aumenta la longitud de la oración de entrada.
Comprimir un párrafo complejo en un solo vector es equivalente a intentar resumir un capítulo completo de un libro en una sola oración antes de traducirlo. La información se pierde inevitablemente.
3. El Mecanismo de Atención: Un cambio de paradigma
Para resolver el cuello de botella de la información, Dzmitry Bahdanau y sus colegas introdujeron el Mecanismo de Atención en 2015.
En lugar de confiar únicamente en un Vector de Contexto único y estático del paso final del codificador, la Atención permite al decodificador “mirar hacia atrás” a todos los estados ocultos intermedios del codificador en cada paso del proceso de decodificación. Esto significa que el modelo se enfoca (presta atención) dinámicamente en diferentes partes de la secuencia de entrada según la palabra que está generando actualmente.
Cómo funciona la atención: paso a paso
En cada paso de decodificación $t$:
- Calcular puntuaciones de alineación ($e_{t, j}$): El modelo compara el estado oculto del decodificador actual $s_{t-1}$ con cada estado oculto del codificador $h_j$ para medir qué tan relevante es el estado del codificador $j$ para el paso actual del decodificador. $$e_{t, j} = \text{score}(s_{t-1}, h_j)$$
- Calcular pesos de atención ($\alpha_{t, j}$): Las puntuaciones de alineación se normalizan mediante una función softmax para convertirlas en probabilidades (pesos) que suman 1. $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$
- Generar el Vector de Contexto Dinámico ($c_t$): El vector de contexto se calcula como la suma ponderada de todos los estados ocultos del codificador. $$c_t = \sum_j \alpha_{t, j} h_j$$
- Predecir el Token: El decodificador combina el vector de contexto dinámico $c_t$ con su estado actual $s_t$ para predecir el siguiente token de salida.
4. Recorrido detallado de los mecanismos Seq2Seq y de atención
Para apreciar verdaderamente la ingeniería detrás de estos mecanismos, tracemos los pasos matemáticos y operativos de la clásica arquitectura de secuencia a secuencia, seguidos de los enfoques de atención de Bahdanau (aditivo) y Luong (multiplicativo).
Línea base: Recorrido de la arquitectura clásica Sequence-to-Sequence (sin atención)
Antes de explorar la atención, tracemos cómo la arquitectura estándar Sequence-to-Sequence (Encoder-Decoder) procesa la información de forma secuencial:
- Fase de Codificación:
Para una secuencia de entrada $x_1, x_2, \dots, x_T$:
- En cada paso de tiempo $t$, la celda recurrente del Encoder (LSTM/GRU) updates su estado oculto $h_t$ en función del token de entrada actual $x_t$ y del estado oculto anterior $h_{t-1}$: $$h_t = \text{RNN}{\text{enc}}(x_t, h{t-1})$$
- Generación del Vector de Contexto:
- El estado oculto final del encoder $h_T$ actúa como el vector de contexto $c$ (la representación estática del cuello de botella): $$c = h_T$$
- Inicialización de la Fase de Decodificación:
- El estado oculto inicial $s_0$ de la celda del Decoder se inicializa directamente con el vector de contexto $c$: $$s_0 = c$$
- Paso Autorregresivo del Decodificador:
- En cada paso de tiempo de decodificación $t$, el Decodificador actualiza su estado oculto $s_t$ basándose en el token predicho anterior $y_{t-1}$ y en el estado oculto anterior $s_{t-1}$: $$s_t = \text{RNN}{\text{dec}}(y{t-1}, s_{t-1})$$
- Predicción de Tokens:
- La distribución de probabilidad para el siguiente token $y_t$ se calcula mediante una capa lineal y una activación softmax aplicada al estado del decodificador $s_t$: $$p(y_t | y_{<t}) = \text{softmax}(W_y s_t + b_y)$$
Enfoque 1: Recorrido de la atención de Bahdanau (aditiva)
La atención de Bahdanau también se llama atención aditiva porque calcula las puntuaciones de alineación utilizando una capa de red neuronal de alimentación hacia adelante. Funciona bajo un flujo de dependencia del “estado anterior”:
- Inicialización / Dependencia: En el paso de decodificación $t$, el decodificador utiliza su estado oculto anterior $s_{t-1}$ y los estados ocultos del codificador $h_j$ (para todos los pasos de entrada $j$) para calcular la atención.
- Calcular puntuaciones de alineación (Aditivo): $$e_{t, j} = v_a^T \tanh(W_a s_{t-1} + U_a h_j)$$ Aquí, $W_a$ y $U_a$ son matrices de pesos aprendibles que proyectan el estado del decodificador y los estados del codificador en un espacio compartido. Su suma se pasa a través de una función de activación $\tanh$ y luego se proyecta a un escalar usando el vector de pesos $v_a$.
- Calcular pesos de atención (Softmax): $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$ Esto normaliza las puntuaciones de alineación en una distribución de probabilidad sobre la secuencia de entrada.
- Generar vector de contexto dinámico: $$c_t = \sum_j \alpha_{t, j} h_j$$ Esta es una suma ponderada de los estados ocultos del codificador, que representa las partes de la secuencia de entrada en las que el modelo debe enfocarse.
- Actualizar el estado oculto del decodificador: El vector de contexto $c_t$ se concatena con la incrustación del token de salida anterior $y_{t-1}$ y se pasa a la celda recurrente del decodificador para calcular el estado actual del decodificador $s_t$: $$s_t = \text{RNN}(s_{t-1}, [c_t; y_{t-1}])$$
- Predecir token: El estado actual $s_t$ se utiliza para predecir la probabilidad del siguiente token.
Enfoque 2: Recorrido de la atención de Luong (multiplicativa)
La atención de Luong, introducida poco después de la de Bahdanau, se conoce como atención multiplicativa. Simplifica el cálculo y se basa en un flujo de dependencia del “estado actual”:
- Actualizar primero el estado oculto del decodificador: En el paso de decodificación $t$, el decodificador primero actualiza su estado oculto a $s_t$ mediante la transición recurrente normal, utilizando únicamente el estado anterior $s_{t-1}$ y el token de salida anterior $y_{t-1}$: $$s_t = \text{RNN}(s_{t-1}, y_{t-1})$$
- Calcular puntuaciones de alineación (Multiplicativo):
Luong propuso tres funciones de puntuación alternativas. La más utilizada es la forma General, que utiliza una multiplicación de matrices (por lo tanto, multiplicativa):
- General: $e_{t, j} = s_t^T W_a h_j$
- Dot: $e_{t, j} = s_t^T h_j$ (asume igual dimensionalidad)
- Concat: $e_{t, j} = v_a^T \tanh(W_a [s_t; h_j])$ La atención multiplicativa es computacionalmente más rápida y eficiente en espacio que la atención aditiva porque se puede calcular utilizando operaciones de multiplicación de matrices altamente optimizadas.
- Calcular pesos de atención (Softmax): $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$
- Generar vector de contexto dinámico: $$c_t = \sum_j \alpha_{t, j} h_j$$
- Calcular estado oculto de atención: En lugar de utilizar el estado del decodificador directamente para la predicción, el vector de contexto $c_t$ y el estado actual $s_t$ se combinan mediante una capa lineal y una activación $\tanh$ para producir un estado oculto de atención $\tilde{s}_t$: $$\tilde{s}_t = \tanh(W_c [c_t; s_t])$$
- Predecir token: El estado oculto de atención $\tilde{s}t$ se utiliza para generar la predicción final: $$p(y_t | y{<t}, x) = \text{softmax}(W_s \tilde{s}_t)$$
Comparación Arquitectónica
| Característica | Atención de Bahdanau (Aditiva) | Atención de Luong (Multiplicativa) |
|---|---|---|
| Puntuación matemática | Utiliza una red de alimentación hacia adelante: $v_a^T \tanh(W_a s_{t-1} + U_a h_j)$ | Utiliza el producto punto o la multiplicación de matrices: $s_t^T W_a h_j$ |
| Estado del decodificador utilizado | Utiliza el estado del decodificador anterior $s_{t-1}$. | Utiliza el estado del decodificador actual $s_t$. |
| Computación | Más complejo, más lento pero muy flexible. | Más rápido, más simple y muy eficiente. |
5. El legado: De la atención a los Transformers
El Mecanismo de Atención se diseñó inicialmente como un complemento para mejorar las RNN. Sin embargo, los investigadores pronto se dieron cuenta de que las capas de atención hacían todo el trabajo pesado, mientras que las estructuras recurrentes (RNN/LSTM) actuaban como un cuello de botella computacional porque tenían que procesar tokens secuencialmente.
In 2017, los investigadores publicaron el artículo fundamental “Attention Is All You Need”, presentando la arquitectura Transformer. El Transformer descartó las RNN por completo, basándose únicamente en la Self-Attention (Autoatención) para procesar secuencias completas en paralelo.
Este avance es la base de los modelos de lenguaje grandes (LLM) modernos como GPT-4, Gemini y Claude, lo que demuestra que la atención es, de hecho, el concepto más poderoso en el NLP moderno.