Sequence-to-Sequence (Seq2Seq) आर्किटेक्चर और अटेंशन मैकेनिज्म का विस्तृत विश्लेषण
प्राकृतिक भाषा प्रसंस्करण (NLP) और आर्टिफिशियल इंटेलिजेंस के क्षेत्र में, भाषाओं का अनुवाद करने, लेखों का सारांश बनाने और संवादात्मक प्रतिक्रियाएं उत्पन्न करने की क्षमता में एक अभूतपूर्व क्रांति आई है। इस बदलाव के केंद्र में Sequence-to-Sequence (Seq2Seq) आर्किटेक्चर और अग्रणी अटेंशन मैकेनिज्म (Attention Mechanism) मौजूद हैं।
आधुनिक ट्रांसफॉर्मर (Transformers) के आगमन से पहले, इन दो आविष्कारों ने डीप लर्निंग की सबसे बड़ी चुनौतियों में से एक को हल किया: इनपुट अनुक्रमों (input sequences) को आउटपुट अनुक्रमों (output sequences) से मैप करना जब उनकी लंबाई अलग-अलग हो।
1. आधार: Sequence-to-Sequence (Seq2Seq) क्या है?
2014 में Google के शोधकर्ताओं और अन्य वैज्ञानिकों द्वारा प्रस्तुत किया गया Sequence-to-Sequence (Seq2Seq) मॉडल अनुक्रमिक डेटा को संसाधित करने के लिए डिज़ाइन किया गया एक एन्कोडर-डिकोडर (encoder-decoder) फ्रेमवर्क है। इसका व्यापक रूप से उन कार्यों में उपयोग किया जाता है जहाँ इनपुट अनुक्रम की लंबाई आउटपुट अनुक्रम की लंबाई से मेल नहीं खाती है, जैसे:
- मशीनी अनुवाद: अंग्रेजी के “How are you?” (3 शब्द) का हिंदी में “आप कैसे हैं?” (3 शब्द) या स्पेनिश में “¿Cómo estás?” (2 शब्द) में अनुवाद करना।
- पाठ का सारांश (Text Summarization): एक 500 शब्दों के लेख को 50 शब्दों के सारांश में संक्षिप्त करना।
- प्रश्नोत्तर प्रणाली: प्रश्नों के अनुक्रम को उत्तरों के अनुक्रम से मैप करना।
एन्कोडर-डिकोडर मैकेनिज्म
मानक Seq2Seq मॉडल में दो रिकरेंट न्यूरल नेटवर्क (RNN) होते हैं, जो आमतौर पर LSTM (Long Short-Term Memory) या GRU (Gated Recurrent Units) होते हैं:
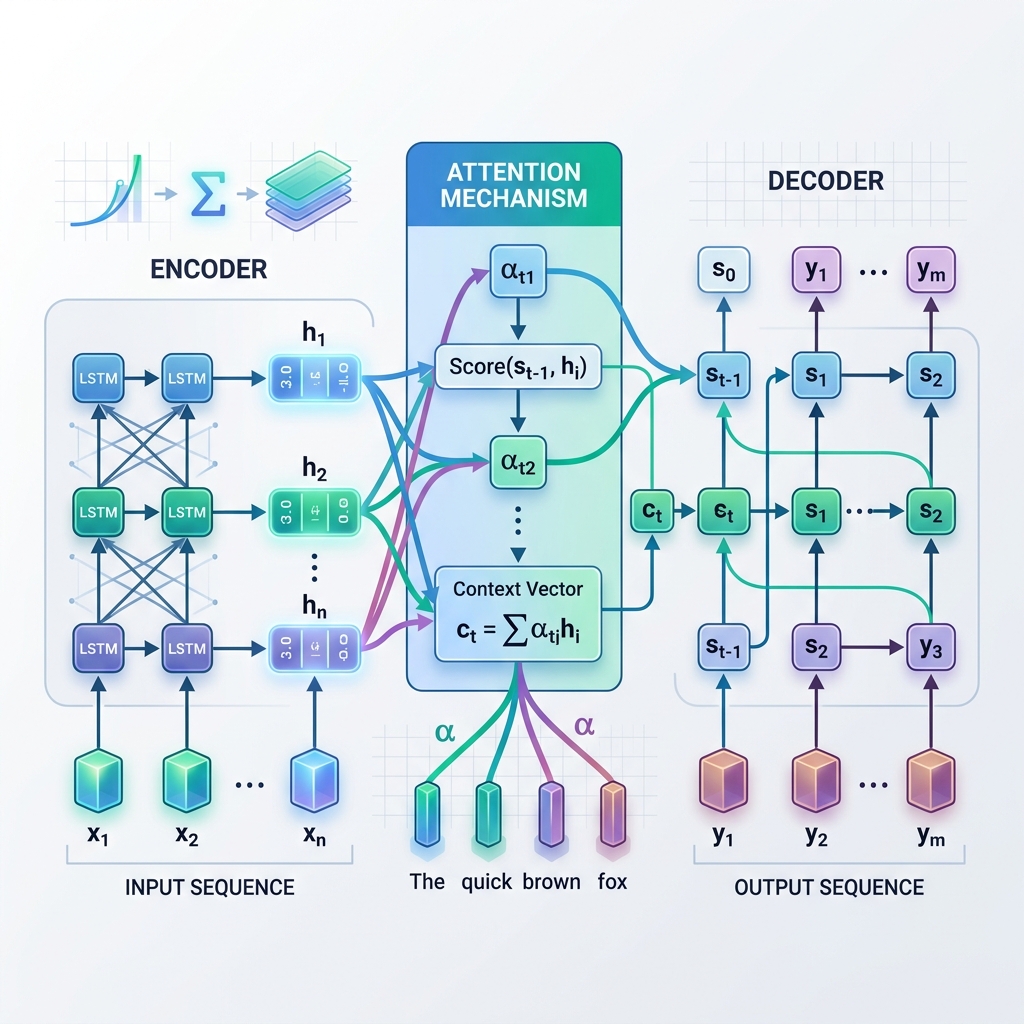
- एन्कोडर (Encoder): इनपुट अनुक्रम को एक-एक टोकन करके संसाधित करता है। हर कदम पर, यह वर्तमान इनपुट टोकन और पिछली छिपी हुई स्थिति (hidden state) के आधार पर अपनी छिपी हुई स्थिति को अपडेट करता है। एक बार पूरा इनपुट संसाधित हो जाने के बाद, एन्कोडर की अंतिम छिपी हुई स्थिति को कैप्चर कर लिया जाता है। इस अंतिम स्थिति को संदर्भ वेक्टर (Context Vector) (या अड़चन/bottleneck वेक्टर) कहा जाता है।
- डिकोडर (Decoder): संदर्भ वेक्टर को अपनी प्रारंभिक छिपी हुई स्थिति के रूप में लेता है और आउटपुट अनुक्रम को स्वचालित रूप से (autoregressively) एक-एक टोकन करके उत्पन्न करता है। हर कदम पर, यह अपनी वर्तमान छिपी हुई स्थिति और पहले से उत्पन्न शब्द के आधार पर अगले शब्द का अनुमान लगाता है।
2. अड़चन की समस्या (Information Bottleneck)
यद्यपि क्लासिक एन्कोडर-डिकोडर मॉडल एक बहुत बड़ी तकनीकी सफलता थी, लेकिन यह एक मौलिक सीमा से पीड़ित था जिसे सूचना की अड़चन (Information Bottleneck) कहा जाता है।
एक मानक Seq2Seq मॉडल में, एन्कोडर को इनपुट वाक्य के पूरे अर्थ को—चाहे वह 5 शब्दों का हो या 100 शब्दों का—एक निश्चित आकार के एकल संदर्भ वेक्टर में संपीड़ित करने के लिए मजबूर होना पड़ता है।
जिसके परिणामस्वरूप:
- दीर्घकालिक स्मृति का नुकसान: लंबे वाक्यों के लिए, अनुक्रम के शुरुआती हिस्सों को एन्कोडर के अंत तक पहुँचने तक भुला दिया जाता है।
- प्रदर्शन में गिरावट: इनपुट वाक्य की लंबाई बढ़ने के साथ अनुवाद या सारांश की गुणवत्ता में भारी गिरावट आती है।
एक जटिल पैराग्राफ को एक ही वेक्टर में संपीड़ित करना पुस्तक के पूरे अध्याय का अनुवाद करने से पहले उसे एक वाक्य में सारांशित करने के प्रयास के समान है। जानकारी का नुकसान अपरिहार्य हो जाता है।
3. अटेंशन मैकेनिज्म: एक युगांतरकारी बदलाव
सूचना की इस अड़चन को हल करने के लिए, 2015 में दिमित्री बाहदानौ (Dzmitry Bahdanau) और उनके सहयोगियों ने अटेंशन मैकेनिज्म (Attention Mechanism) की शुरुआत की।
एन्कोडर के अंतिम चरण से प्राप्त होने वाले एकल, स्थिर संदर्भ वेक्टर पर निर्भर रहने के बजाय, अटेंशन डिकोडर को डिकोडिंग प्रक्रिया के प्रत्येक चरण में एन्कोडर के सभी मध्यवर्ती छिपे हुए राज्यों को “पीछे मुड़कर देखने” की अनुमति देता है। इसका मतलब यह है कि मॉडल वर्तमान में उत्पन्न होने वाले शब्द के आधार पर इनपुट अनुक्रम के विभिन्न हिस्सों पर गतिशील रूप से ध्यान केंद्रित करता है।
अटेंशन मैकेनिज्म कैसे काम करता है: चरण-दर-चरण विश्लेषण
प्रत्येक डिकोडिंग चरण $t$ पर:
- संरेखण स्कोर (Alignment Scores, $e_{t, j}$) की गणना: मॉडल वर्तमान डिकोडर छिपी हुई स्थिति $s_{t-1}$ की तुलना एन्कोडर की प्रत्येक छिपी हुई स्थिति $h_j$ से करता है ताकि यह मापा जा सके कि एन्कोडर स्थिति $j$ वर्तमान डिकोडर चरण के लिए कितनी प्रासंगिक है। $$e_{t, j} = \text{score}(s_{t-1}, h_j)$$
- अटेंशन भार (Attention Weights, $\alpha_{t, j}$) की गणना: संरेखण स्कोर को सॉफ्टमैक्स (softmax) फ़ंक्शन का उपयोग करके सामान्यीकृत किया जाता है ताकि उन्हें संभावनाओं (भार) में बदला जा सके जिनका योग 1 होता है। $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$
- गतिशील संदर्भ वेक्टर ($c_t$) का निर्माण: संदर्भ वेक्टर की गणना सभी एन्कोडर छिपे हुए राज्यों के भारित योग के रूप में की जाती है। $$c_t = \sum_j \alpha_{t, j} h_j$$
- टोकन की भविष्यवाणी: डिकोडर अगले आउटपुट टोकन की भविष्यवाणी करने के लिए गतिशील संदर्भ वेक्टर $c_t$ को अपनी वर्तमान स्थिति $s_t$ के साथ जोड़ता है।
4. Seq2Seq और अटेंशन मैकेनिज्म का विस्तृत विश्लेषण
इन मैकेनिज्म के पीछे की इंजीनियरिंग को वास्तव में समझने के लिए, आइए पहले क्लासिक Sequence-to-Sequence आर्किटेक्चर के गणितीय और परिचालन चरणों को देखें, जिसके बाद बाहदानौ (योगात्मक) और लुओंग (गुणात्मक) दोनों अटेंशन दृष्टिकोणों का विश्लेषण किया जाएगा।
बेसलाइन: क्लासिक Sequence-to-Sequence आर्किटेक्चर विश्लेषण (बिना अटेंशन के)
अटेंशन को समझने से पहले, आइए देखें कि मानक Sequence-to-Sequence (एन्कोडर-डिकोडर) आर्किटेक्चर अनुक्रमिक रूप से जानकारी को कैसे संसाधित करता है:
- एन्कोडिंग चरण:
इनपुट अनुक्रम $x_1, x_2, \dots, x_T$ के लिए:
- प्रत्येक समय चरण $t$ पर, एन्कोडर आवर्ती सेल (LSTM/GRU) वर्तमान इनपुट टोकन $x_t$ और पिछले छिपे हुए राज्य $h_{t-1}$ के आधार पर अपने छिपे हुए राज्य $h_t$ को अपडेट करता है: $$h_t = \text{RNN}{\text{enc}}(x_t, h{t-1})$$
- संदर्भ वेक्टर जनरेशन:
- अंतिम एन्कोडर छिपा हुआ राज्य $h_T$ संदर्भ वेक्टर $c$ (स्थिर अड़चन प्रतिनिधित्व) के रूप में कार्य करता है: $$c = h_T$$
- डिकोडिंग चरण का प्रारंभ:
- डिकोडर आवर्ती सेल का प्रारंभिक छिपा हुआ राज्य $s_0$ सीधे संदर्भ वेक्टर $c$ के साथ प्रारंभ किया जाता है: $$s_0 = c$$
- डिकोडर ऑटोरेग्रेसिव चरण:
- प्रत्येक डिकोडिंग समय चरण $t$ पर, डिकोडर पिछले अनुमानित टोकन $y_{t-1}$ और पिछले छिपे हुए राज्य $s_{t-1}$ के आधार पर अपने छिपे हुए राज्य $s_t$ को अपडेट करता है: $$s_t = \text{RNN}{\text{dec}}(y{t-1}, s_{t-1})$$
- टोकन भविष्यवाणी:
- अगले टोकन $y_t$ के लिए संभावना वितरण की गणना डिकोडर स्थिति $s_t$ पर लागू लीनियर लेयर और सॉफ्टमैक्स एक्टिवेशन का उपयोग करके की जाती है: $$p(y_t | y_{<t}) = \text{softmax}(W_y s_t + b_y)$$
दृष्टिकोण 1: बाहदानौ (योगात्मक/Additive) अटेंशन विश्लेषण
बाहदानौ अटेंशन को योगात्मक अटेंशन (additive attention) भी कहा जाता है क्योंकि यह एक फ़ीड-फॉरवर्ड न्यूरल नेटवर्क लेयर का उपयोग करके संरेखण स्कोर (alignment scores) की गणना करता है। यह “पिछली-स्थिति” (previous-state) निर्भरता प्रवाह के तहत काम करता है:
- प्रारंभीकरण / निर्भरता: डिकोडिंग चरण $t$ पर, डिकोडर अटेंशन की गणना करने के लिए अपनी पिछली छिपी हुई स्थिति $s_{t-1}$ और एनकोडर की छिपी हुई स्थितियों $h_j$ (सभी इनपुट चरणों $j$ के लिए) का उपयोग करता है।
- संरेखण स्कोर की गणना (योगात्मक): $$e_{t, j} = v_a^T \tanh(W_a s_{t-1} + U_a h_j)$$ यहाँ, $W_a$ और $U_a$ सीखने योग्य वेट मैट्रिसेस (weight matrices) हैं जो डिकोडर स्थिति और एनकोडर स्थिति को एक साझा स्थान (shared space) में प्रोजेक्ट करते हैं। उनके योग को एक $\tanh$ एक्टिवेशन फ़ंक्शन के माध्यम से पारित किया जाता है, और फिर वेट वेक्टर $v_a$ का उपयोग करके एक स्केलर पर प्रोजेक्ट किया जाता है।
- अटेंशन वेट की गणना (Softmax): $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$ यह संरेखण स्कोर को इनपुट अनुक्रम पर एक संभाव्यता वितरण (probability distribution) में सामान्यीकृत करता है।
- गतिशील संदर्भ वेक्टर (Context Vector) बनाना: $$c_t = \sum_j \alpha_{t, j} h_j$$ यह एनकोडर की छिपी हुई स्थितियों का एक भारित योग है, जो इनपुट अनुक्रम के उन हिस्सों का प्रतिनिधित्व करता है जिन पर मॉडल को ध्यान केंद्रित करना चाहिए।
- डिकोडर की छिपी हुई स्थिति को अपडेट करना: संदर्भ वेक्टर $c_t$ को पिछले आउटपुट टोकन $y_{t-1}$ के एम्बेडिंग के साथ जोड़ा जाता है, और वर्तमान डिकोडर स्थिति $s_t$ की गणना करने के लिए डिकोडर की आवर्ती सेल (recurrent cell) में पारित किया जाता है: $$s_t = \text{RNN}(s_{t-1}, [c_t; y_{t-1}])$$
- टोकन की भविष्यवाणी: वर्तमान स्थिति $s_t$ का उपयोग अगले टोकन की संभावना की भविष्यवाणी करने के लिए किया जाता है।
दृष्टिकोण 2: लुओंग (गुणात्मक/Multiplicative) अटेंशन विश्लेषण
बाहदानौ के तुरंत बाद पेश किए गए लुओंग अटेंशन को गुणात्मक अटेंशन (multiplicative attention) कहा जाता है। यह गणना को सरल बनाता है और “वर्तमान-स्थिति” (current-state) निर्भरता प्रवाह पर निर्भर करता है:
- पहले डिकोडर की छिपी हुई स्थिति को अपडेट करना: डिकोडिंग चरण $t$ पर, डिकोडर सबसे पहले सामान्य आवर्ती संक्रमण (recurrent transition) का उपयोग करके अपनी छिपी हुई स्थिति को $s_t$ पर अपडेट करता है, जिसमें केवल पिछली स्थिति $s_{t-1}$ और पिछले आउटपुट टोकन $y_{t-1}$ का उपयोग किया जाता है: $$s_t = \text{RNN}(s_{t-1}, y_{t-1})$$
- संरेखण स्कोर की गणना (गुणात्मक):
लुओंग ने तीन वैकल्पिक स्कोर फ़ंक्शंस का प्रस्ताव दिया। सबसे व्यापक रूप से उपयोग किया जाने वाला General रूप है, जो मैट्रिक्स गुणन का उपयोग करता है (इसलिए इसे गुणात्मक कहा जाता है):
- General: $e_{t, j} = s_t^T W_a h_j$
- Dot: $e_{t, j} = s_t^T h_j$ (समान विमा/dimensionality मानता है)
- Concat: $e_{t, j} = v_a^T \tanh(W_a [s_t; h_j])$ गुणात्मक अटेंशन अतिरिक्त अटेंशन की तुलना में गणनात्मक रूप से तेज़ और स्थान-कुशल है क्योंकि इसकी गणना अत्यधिक अनुकूलित मैट्रिक्स गुणन ऑपरेशन्स का उपयोग करके की जा सकती है।
- अटेंशन वेट की गणना (Softmax): $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$
- गतिशील संदर्भ वेक्टर बनाना: $$c_t = \sum_j \alpha_{t, j} h_j$$
- अटेंशन छिपी हुई स्थिति (Attentional Hidden State) की गणना: भविष्यवाणी के लिए सीधे डिकोडर स्थिति का उपयोग करने के बजाय, संदर्भ वेक्टर $c_t$ और वर्तमान स्थिति $s_t$ को एक रैखिक परत (linear layer) और एक $\tanh$ एक्टिवेशन का उपयोग करके एक अटेंशन छिपी हुई स्थिति $\tilde{s}_t$ का उत्पादन करने के लिए संयोजित किया जाता है: $$\tilde{s}_t = \tanh(W_c [c_t; s_t])$$
- टोकन की भविष्यवाणी: अटेंशन छिपी हुई स्थिति $\tilde{s}t$ का उपयोग अंतिम भविष्यवाणी उत्पन्न करने के लिए किया जाता है: $$p(y_t | y{<t}, x) = \text{softmax}(W_s \tilde{s}_t)$$
स्थापत्य (Architectural) तुलना
| विशेषता | बाहदानौ (योगात्मक/Additive) अटेंशन | लुओंग (गुणात्मक/Multiplicative) अटेंशन |
|---|---|---|
| गणितीय स्कोर | एक फ़ीड-फॉरवर्ड नेटवर्क का उपयोग करता है: $v_a^T \tanh(W_a s_{t-1} + U_a h_j)$ | डॉट उत्पाद या मैट्रिक्स गुणन का उपयोग करता है: $s_t^T W_a h_j$ |
| डिकोडर स्थिति का उपयोग | पिछली डिकोडर स्थिति $s_{t-1}$ का उपयोग करता है। | वर्तमान डिकोडर स्थिति $s_t$ का उपयोग करता है। |
| गणना | अधिक जटिल, धीमी लेकिन अत्यधिक लचीली। | तेज़, सरल और अत्यधिक कुशल। |
5. विरासत: अटेंशन मैकेनिज्म से ट्रांसफॉर्मर तक
अटेंशन मैकेनिज्म को शुरू में RNNs को बेहतर बनाने के लिए एक अतिरिक्त घटक के रूप में डिज़ाइन किया गया था। हालांकि, शोधकर्ताओं ने जल्द ही महसूस किया कि अटेंशन परतें ही सारा महत्वपूर्ण कार्य कर रही थीं, जबकि आवर्ती संरचनाएं (RNN/LSTM) एक गणनात्मक अड़चन के रूप में कार्य कर रही थीं क्योंकि उन्हें टोकन को क्रमिक रूप से संसाधित करना पड़ता था।
2017 में, शोधकर्ताओं ने अपना ऐतिहासिक शोध पत्र “Attention Is All You Need” प्रकाशित किया, जिसमें Transformer आर्किटेक्चर पेश किया गया। ट्रांसफॉर्मर ने RNNs को पूरी तरह से हटा दिया, और समानांतर में पूरे अनुक्रमों को संसाधित करने के लिए केवल सेल्फ-अटेंशन (Self-Attention) पर भरोसा किया।
यह नवाचार आधुनिक बड़े भाषा मॉडलों (LLMs) जैसे कि GPT-4, Gemini और Claude का मुख्य आधार है, जो यह साबित करता है कि अटेंशन ही आधुनिक NLP में सबसे शक्तिशाली अवधारणा है।