Demystifizierung der Sequence-to-Sequence-Architektur und des Attention-Mechanismus
In der Landschaft der natürlichen Sprachverarbeitung (NLP) und der künstlichen Intelligenz hat die Fähigkeit, Sprachen zu übersetzen, Artikel zusammenzufassen und Konversationsantworten zu generieren, eine Revolution erfahren. Im Herzen dieser Transformation liegt die Sequence-to-Sequence (Seq2Seq) Architektur und der wegweisende Attention-Mechanismus.
Vor dem Aufkommen moderner Transformer lösten diese beiden Innovationen eine der größten Herausforderungen des Deep Learning: die Abbildung von Eingabesequenzen auf Ausgabesequenzen bei unterschiedlichen Längen.
1. Das Fundament: Was ist Sequence-to-Sequence (Seq2Seq)?
Das 2014 von Forschern bei Google und anderen vorgestellte Sequence-to-Sequence (Seq2Seq)-Modell ist ein Encoder-Decoder-Framework zur Verarbeitung sequenzieller Daten. Es wird häufig bei Aufgaben eingesetzt, bei denen die Länge der Eingabesequenz nicht mit der Länge der Ausgabesequenz übereinstimmt, wie z. B.:
- Maschinelle Übersetzung: Übersetzung von “How are you?” (3 Wörter) ins Deutsche “Wie geht es dir?” (4 Wörter) oder Spanische “¿Cómo estás?” (2 Wörter).
- Textzusammenfassung: Komprimierung eines 500-Wörter-Artikels in eine Zusammenfassung mit 50 Wörtern.
- Frage-Antwort-Systeme: Abbildung einer Fragesequenz auf eine Antwortsequenz.
Der Encoder-Decoder-Mechanismus
Das Standard-Seq2Seq-Modell besteht aus zwei rekurrenten neuronalen Netzen (RNNs), typischerweise LSTMs (Long Short-Term Memory) oder GRUs (Gated Recurrent Units):
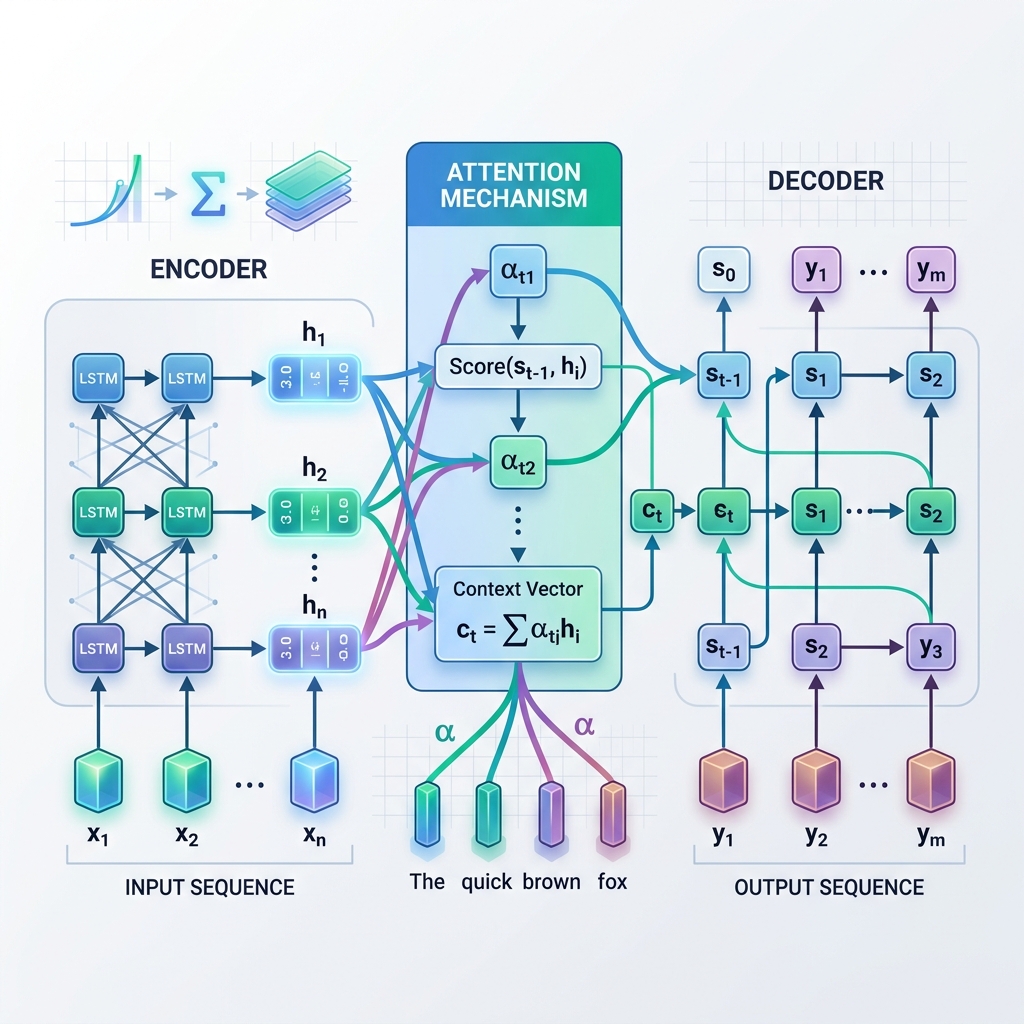
- Der Encoder: Verarbeitet die Eingabesequenz Token für Token. Bei jedem Schritt aktualisiert er seinen verborgenen Zustand basierend auf dem aktuellen Eingabetoken und dem vorherigen verborgenen Zustand. Sobald die gesamte Eingabe verarbeitet ist, wird der letzte verborgene Zustand des Encoders erfasst. Dieser Endzustand wird als Kontextvektor (oder Flaschenhalsvektor) bezeichnet.
- Der Decoder: Nimmt den Kontextvektor als seinen anfänglichen verborgenen Zustand und generiert die Ausgabesequenz autoregressiv Token für Token. Bei jedem Schritt sagt er das nächste Wort basierend auf seinem aktuellen verborgenen Zustand und dem zuvor generierten Wort voraus.
2. Das Flaschenhals-Problem
Obwohl das klassische Encoder-Decoder-Modell ein enormer Durchbruch war, litt es unter einer grundlegenden Einschränkung, dem sogenannten Informationsflaschenhals.
In einem Standard-Seq2Seq-Modell ist der Encoder gezwungen, die gesamte Bedeutung eines Eingabesatzes – unabhängig davon, ob er aus 5 oder 100 Wörtern besteht – in einen einzigen Kontextvektor mit fester Größe zu komprimieren.
Dies führt zu folgenden Problemen:
- Verlust des Langzeitgedächtnisses: Bei längeren Sätzen werden die frühen Teile der Sequenz vergessen, bis der Encoder das Ende erreicht.
- Leistungsabfall: Die Qualität der Übersetzung oder Zusammenfassung nimmt mit zunehmender Länge des Eingabesatzes erheblich ab.
Das Komprimieren eines komplexen Absatzes in einen einzigen Vektor ist so, als würde man versuchen, ein ganzes Buchkapitel in einem einzigen Satz zusammenzufassen, bevor man es übersetzt. Informationen gehen unweigerlich verloren.
3. Der Attention-Mechanismus: Ein Paradigmenwechsel
Um den Informationsflaschenhals zu lösen, führten Dzmitry Bahdanau und Kollegen 2015 den Attention-Mechanismus ein.
Anstatt sich nur auf einen einzigen, statischen Kontextvektor aus dem letzten Schritt des Encoders zu verlassen, ermöglicht Attention dem Decoder, bei jedem Schritt des Decodierungsprozesses auf alle Zwischenzustände des Encoders zurückzublicken. Das bedeutet, dass sich das Modell dynamisch auf verschiedene Teile der Eingabesequenz konzentriert, je nachdem, welches Wort es gerade generiert.
Wie Attention funktioniert: Schritt für Schritt
Bei jedem Decodierungsschritt $t$:
- Berechnung der Alignment-Scores ($e_{t, j}$): Das Modell vergleicht den aktuellen verborgenen Zustand des Decoders $s_{t-1}$ mit jedem verborgenen Zustand des Encoders $h_j$, um zu messen, wie relevant der Encoder-Zustand $j$ für den aktuellen Decoder-Schritt ist. $$e_{t, j} = \text{score}(s_{t-1}, h_j)$$
- Berechnung der Attention-Weights ($\alpha_{t, j}$): Die Alignment-Scores werden mithilfe einer Softmax-Funktion normiert, um sie in Wahrscheinlichkeiten (Gewichte) umzuwandeln, die sich zu 1 addieren. $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$
- Erzeugung des dynamischen Kontextvektors ($c_t$): Der Kontextvektor wird als gewichtete Summe aller verborgenen Zustände des Encoders berechnet. $$c_t = \sum_j \alpha_{t, j} h_j$$
- Vorhersage des Tokens: Der Decoder kombiniert den dynamischen Kontextvektor $c_t$ mit seinem aktuellen Zustand $s_t$, um das nächste Ausgabe-Token vorherzusagen.
4. Detaillierter Ablauf von Seq2Seq- und Attention-Mechanismen
Um die Technik hinter diesen Mechanismen wirklich zu verstehen, lassen Sie uns die mathematischen und operativen Schritte der klassischen Sequence-to-Sequence-Architektur nachvollziehen, gefolgt von den Ansätzen der Bahdanau- (additiven) und Luong- (multiplikativen) Attention.
Baseline: Ablauf der klassischen Sequence-to-Sequence-Architektur (ohne Attention)
Bevor wir uns mit der Attention beschäftigen, lassen Sie uns nachvollziehen, wie die Standard-Sequence-to-Sequence-Architektur (Encoder-Decoder) Informationen sequenziell verarbeitet:
- Codierungsphase:
Für eine Eingabesequenz $x_1, x_2, \dots, x_T$:
- Bei jedem Zeitschritt $t$ aktualisiert die rekurrent Zelle des Encoders (LSTM/GRU) ihren verborgenen Zustand $h_t$ basierend auf dem aktuellen Eingabetoken $x_t$ und dem vorherigen verborgenen Zustand $h_{t-1}$: $$h_t = \text{RNN}{\text{enc}}(x_t, h{t-1})$$
- Generierung des Kontextvektors:
- Der letzte verborgene Zustand des Encoders $h_T$ fungiert als Kontextvektor $c$ (die statische Flaschenhals-Darstellung): $$c = h_T$$
- Initialisierung des Decoders:
- Der anfängliche verborgene Zustand $s_0$ der Decoder-Zelle wird direkt mit dem Kontextvektor $c$ initialisiert: $$s_0 = c$$
- Autoregressiver Schritt des Decoders:
- Bei jedem Decodierungsschritt $t$ aktualisiert der Decoder seinen verborgenen Zustand $s_t$ basierend auf dem vorherigen vorhergesagten Token $y_{t-1}$ und dem vorherigen verborgenen Zustand $s_{t-1}$: $$s_t = \text{RNN}{\text{dec}}(y{t-1}, s_{t-1})$$
- Token-Vorhersage:
- Die Wahrscheinlichkeitsverteilung für das nächste Token $y_t$ wird mithilfe einer linearen Schicht und einer Softmax-Aktivierung berechnet, die auf den Decoderzustand $s_t$ angewendet wird: $$p(y_t | y_{<t}) = \text{softmax}(W_y s_t + b_y)$$
Ansatz 1: Ablauf der Bahdanau- (additiven) Attention
Die Bahdanau-Attention wird auch als additive Attention bezeichnet, da sie die Ausrichtungsbewertungen (Alignment Scores) mithilfe einer Feed-Forward-Netzwerkschicht berechnet. Sie arbeitet nach einem Ablauf, der vom vorherigen Zustand abhängt:
- Initialisierung / Abhängigkeit: Beim Dekodierungsschritt $t$ verwendet der Decoder seinen vorherigen verborgenen Zustand $s_{t-1}$ und die verborgenen Zustände des Encoders $h_j$ (für alle Eingabeschritte $j$), um die Attention zu berechnen.
- Berechnung der Ausrichtungsbewertungen (Additiv): $$e_{t, j} = v_a^T \tanh(W_a s_{t-1} + U_a h_j)$$ Hier sind $W_a$ und $U_a$ lernbare Gewichtungsmatrizen, die den Decoderzustand und die Encoderzustände in einen gemeinsamen Raum projizieren. Ihre Summe wird durch eine $\tanh$-Aktivierungsfunktion geleitet und dann mithilfe des Gewichtungsvektors $v_a$ auf einen Skalar projiziert.
- Berechnung der Attention-Gewichte (Softmax): $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$ Dies normalisiert die Ausrichtungsbewertungen in eine Wahrscheinlichkeitsverteilung über die Eingabesequenz.
- Generierung des dynamischen Kontextvektors: $$c_t = \sum_j \alpha_{t, j} h_j$$ Dies ist eine gewichtete Summe der verborgenen Zustände des Encoders, die die Teile der Eingabesequenz darstellt, auf die sich das Modell konzentrieren sollte.
- Aktualisierung des verborgenen Zustands des Decoders: Der Kontextvektor $c_t$ wird mit dem Embedding des vorherigen Ausgabetokens $y_{t-1}$ verkettet und an die rekurrente Zelle des Decoders übergeben, um den aktuellen Decoderzustand $s_t$ zu berechnen: $$s_t = \text{RNN}(s_{t-1}, [c_t; y_{t-1}])$$
- Token-Vorhersage: Der aktuelle Zustand $s_t$ wird verwendet, um die Wahrscheinlichkeit des nächsten Tokens vorherzusagen.
Ansatz 2: Ablauf der Luong- (multiplikativen) Attention
Die kurz nach Bahdanau eingeführte Luong-Attention wird als multiplikative Attention bezeichnet. Sie vereinfacht die Berechnung und beruht auf einem vom aktuellen Zustand abhängigen Ablauf:
- Zuerst den verborgenen Zustand des Decoders aktualisieren: Beim Dekodierungsschritt $t$ aktualisiert der Decoder zuerst seinen verborgenen Zustand auf $s_t$ unter Verwendung des normalen rekurrenten Übergangs, wobei nur der vorherige Zustand $s_{t-1}$ und das vorherige Ausgabetoken $y_{t-1}$ verwendet werden: $$s_t = \text{RNN}(s_{t-1}, y_{t-1})$$
- Berechnung der Ausrichtungsbewertungen (Multiplikativ):
Luong schlug drei alternative Bewertungsfunktionen vor. Die am weitesten verbreitete ist die General-Form, die eine Matrixmultiplikation verwendet (daher multiplikativ):
- General: $e_{t, j} = s_t^T W_a h_j$
- Dot: $e_{t, j} = s_t^T h_j$ (nimmt gleiche Dimensionalität an)
- Concat: $e_{t, j} = v_a^T \tanh(W_a [s_t; h_j])$ Die multiplikative Attention ist rechnerisch schneller und speichereffizienter als die additive Attention, da sie mit hochoptimierten Matrixmultiplikationsoperationen berechnet werden kann.
- Berechnung der Attention-Gewichte (Softmax): $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$
- Generierung des dynamischen Kontextvektors: $$c_t = \sum_j \alpha_{t, j} h_j$$
- Berechnung des aufmerksamkeitsbasierten verborgenen Zustands: Anstatt den Decoderzustand direkt für die Vorhersage zu verwenden, werden der Kontextvektor $c_t$ und der aktuelle Zustand $s_t$ mithilfe einer linearen Schicht und einer $\tanh$-Aktivierung kombiniert, um einen aufmerksamkeitsbasierten verborgenen Zustand $\tilde{s}_t$ zu erzeugen: $$\tilde{s}_t = \tanh(W_c [c_t; s_t])$$
- Token-Vorhersage: Der aufmerksamkeitsbasierte verborgene Zustand $\tilde{s}t$ wird verwendet, um die endgültige Vorhersage zu generieren: $$p(y_t | y{<t}, x) = \text{softmax}(W_s \tilde{s}_t)$$
Vergleich der Architekturen
| Feature | Bahdanau (Additive) Attention | Luong (Multiplicative) Attention |
|---|---|---|
| Mathematischer Score | Uses a feed-forward network: $v_a^T \tanh(W_a s_{t-1} + U_a h_j)$ | Uses dot product or matrix multiplication: $s_t^T W_a h_j$ |
| Decoder State Used | Uses the previous decoder state $s_{t-1}$. | Uses the current decoder state $s_t$. |
| Computation | More complex, slower but highly flexible. | Faster, simpler, and highly efficient. |
5. Das Erbe: Von Attention zu Transformatoren
Der Attention-Mechanismus wurde ursprünglich als Erweiterung für RNNs entwickelt. Die Forscher erkannten jedoch bald, dass die Attention-Schichten die gesamte schwere Arbeit leisteten, während die rekurrenten Strukturen (RNNs/LSTMs) als Rechenflaschenhals wirkten, da sie Token sequenziell verarbeiten mussten.
Im Jahr 2017 veröffentlichten Forscher das bahnbrechende Paper “Attention Is All You Need” und stellten die Transformer-Architektur vor. Der Transformer verwarf RNNs vollständig und stützte sich ausschließlich auf Self-Attention, um ganze Sequenzen parallel zu verarbeiten.
Dieser Durchbruch ist das Fundament moderner Large Language Models (LLMs) wie GPT-4, Gemini und Claude und beweist, dass Attention in der Tat das mächtigste Konzept im modernen NLP ist.
Entdecken Sie weitere technische Einblicke im Ghaznix-Blog →