سیکوئنس ٹو سیکوئنس (Seq2Seq) آرکیٹیکچر اور اٹینشن میکانزم کی حقیقت
قدرتی زبان کی پروسیسنگ (NLP) اور آرٹیفیشل انٹیلیجنس کے میدان میں، زبانوں کا ترجمہ کرنے، مضامین کا خلاصہ کرنے، اور مکالماتی جوابات پیدا کرنے کی صلاحیت نے ایک انقلاب برپا کر دیا ہے۔ اس تبدیلی کے مرکز میں سیکوئنس ٹو سیکوئنس (Seq2Seq) آرکیٹیکچر اور اہم اٹینشن میکانزم (Attention Mechanism) موجود ہیں۔
جدید ٹرانسفارمرز کی آمد سے پہلے، ان دو ایجادات نے ڈیپ لرننگ کے سب سے بڑے چیلنجوں میں سے ایک کو حل کیا: یعنی ان پٹ اور آؤٹ پٹ سیکوئنسز کے درمیان میپنگ کرنا جب ان کی لمبائی مختلف ہو۔
1. بنیاد: سیکوئنس ٹو سیکوئنس (Seq2Seq) کیا ہے؟
2014 میں گوگل اور دیگر محققین کی طرف سے متعارف کروایا گیا Sequence-to-Sequence (Seq2Seq) ماڈل ایک انکوڈر-ڈیکوڈر فریم ورک ہے جو سلسلہ وار ڈیٹا پروسیس کرنے کے لیے ڈیزائن کیا گیا ہے۔ یہ بڑے پیمانے پر ان کاموں میں استعمال ہوتا ہے جہاں ان پٹ سیکوئنس کی لمبائی آؤٹ پٹ سیکوئنس کی لمبائی سے مطابقت نہیں رکھتی، جیسے:
- مشینی ترجمہ: انگریزی کے “How are you?” (3 الفاظ) کا اردو میں “آپ کیسے ہیں؟” (3 الفاظ) یا ہسپانوی میں “¿Cómo estás?” (2 الفاظ) میں ترجمہ کرنا۔
- ٹیکسٹ کی تلخیص: ایک 500 الفاظ کے مضمون کو 50 الفاظ کے خلاصے میں سمیٹنا۔
- سوال و جواب کا نظام: سوالات کے سلسلے کو جوابات کے سلسلے سے میپ کرنا۔
انکوڈر-ڈیکوڈر میکانزم
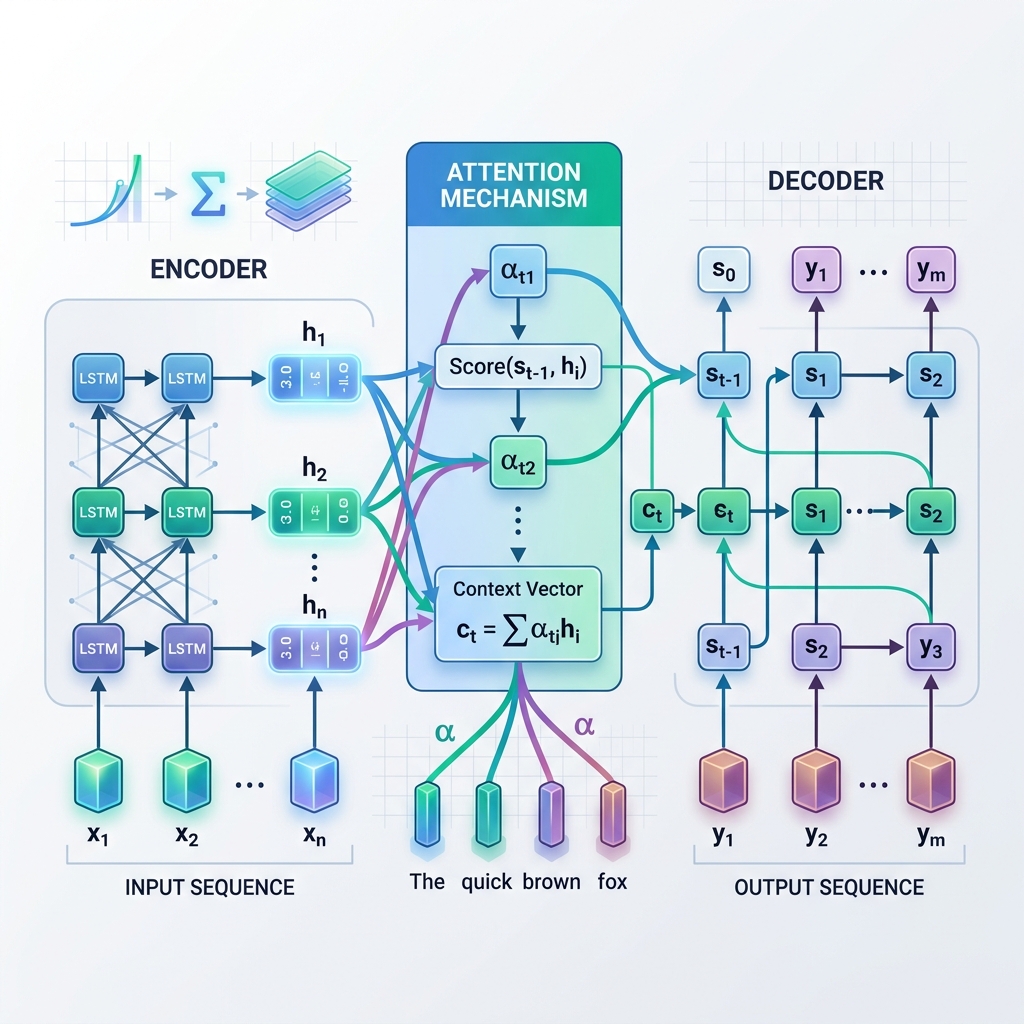
معیاری Seq2Seq ماڈل دو ریکرنٹ نیورل نیٹ ورکس (RNNs) پر مشتمل ہوتا ہے، جو کہ عام طور پر LSTMs یا GRUs ہوتے ہیں:
- انکوڈر (Encoder): ان پٹ سیکوئنس کو ایک ایک ٹوکن کر کے پروسیس کرتا ہے۔ ہر قدم پر، یہ موجودہ ان پٹ ٹوکن اور پچھلی پوشیدہ حالت کی بنیاد پر اپنی پوشیدہ حالت (hidden state) کو اپ ڈیٹ کرتا ہے۔ ان پٹ مکمل ہونے پر، انکوڈر کی آخری پوشیدہ حالت کو محفوظ کر لیا جاتا ہے۔ اس آخری حالت کو سیاق و سباق کا ویکٹر (Context Vector) یا عنق زجاجہ (bottleneck) ویکٹر کہا جاتا ہے۔
- ڈیکوڈر (Decoder): سیاق و سباق کے ویکٹر کو اپنی ابتدائی پوشیدہ حالت کے طور پر لیتا ہے اور سلسلہ وار آؤٹ پٹ پیدا کرتا ہے۔ ہر قدم پر، یہ اپنی موجودہ پوشیدہ حالت اور پہلے سے تیار کردہ لفظ کی بنیاد پر اگلے لفظ کی پیشن گوئی کرتا ہے۔
2. عنق زجاجہ کا مسئلہ (Information Bottleneck)
اگرچہ کلاسک انکوڈر-ڈیکوڈر ماڈل ایک بہت بڑی پیش رفت تھی، لیکن اسے ایک بنیادی حد کا سامنا تھا جسے معلومات کا عنق زجاجہ (Information Bottleneck) کہا جاتا ہے۔
ایک معیاری Seq2Seq ماڈل میں، انکوڈر مجبور ہوتا ہے کہ وہ ان پٹ جملے کے پورے معنی کو—خواہ وہ 5 الفاظ کا ہو یا 100 الفاظ کا—ایک ہی مقررہ سائز کے سیاق و سباق کے ویکٹر میں سکیڑ دے۔
جس کے نتیجے میں:
- طویل مدتی یادداشت کا نقصان: طویل جملوں کے لیے، جب تک انکوڈر آخر تک پہنچتا ہے، سیکوئنس کے ابتدائی حصے بھول جاتے ہیں۔
- کارکردگی میں کمی: ان پٹ جملے کی لمبائی بڑھنے سے ترجمے یا خلاصے کا معیار نمایاں طور پر گر جاتا ہے۔
ایک پیچیدہ پیراگراف کو ایک ہی ویکٹر میں کمپریس کرنا ایسے ہی ہے جیسے ترجمہ کرنے سے پہلے کتاب کے پورے باب کا خلاصہ ایک جملے میں کرنے کی کوشش کی جائے۔ معلومات کا ضیاع ناگزیر ہو جاتا ہے۔
3. اٹینشن میکانزم: ایک انقلابی تبدیلی
معلومات کے عنق زجاجہ کے مسئلے کو حل کرنے کے لیے، 2015 میں دیمتری باہداناؤ (Dzmitry Bahdanau) اور ان کے ساتھیوں نے اٹینشن میکانزم متعارف کرایا۔
انکوڈر کے آخری مرحلے سے حاصل ہونے والے واحد، جامد سیاق و سباق کے ویکٹر پر انحصار کرنے کے بجائے، اٹینشن ڈیکوڈر کو اجازت دیتا ہے کہ وہ ڈیکوڈ کرنے کے عمل کے ہر قدم پر انکوڈر کی تمام درمیانی پوشیدہ حالتوں پر “واپس نظر” ڈال سکے۔ اس کا مطلب یہ ہے کہ ماڈل ان پٹ سیکوئنس کے مختلف حصوں پر متحرک طور پر توجہ مرکوز کرتا ہے، جس کا انحصار اس لفظ پر ہوتا ہے جو وہ اس وقت تیار کر رہا ہے۔
اٹینشن میکانزم کیسے کام کرتا ہے: مرحلہ وار تجزیہ
ہر ڈیکوڈ قدم $t$ پر:
- الائنمنٹ اسکورز کا حساب ($e_{t, j}$): ماڈل موجودہ ڈیکوڈر پوشیدہ حالت $s_{t-1}$ کا موازنہ انکوڈر کی ہر پوشیدہ حالت $h_j$ سے کرتا ہے تاکہ یہ ماپا جا سکے کہ انکوڈر کی حالت $j$ موجودہ ڈیکوڈر قدم کے لیے کتنی اہم ہے۔ $$e_{t, j} = \text{score}(s_{t-1}, h_j)$$
- اٹینشن ویٹس کا حساب ($\alpha_{t, j}$): الائنمنٹ اسکورز کو سافٹ میکس (softmax) فنکشن کے ذریعے نارملائز کیا جاتا ہے تاکہ انہیں امکانی اوزان (weights) میں تبدیل کیا جا سکے جن کا مجموعہ 1 ہوتا ہے۔ $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$
- متحرک سیاق و سباق کے ویکٹر کی تیاری ($c_t$): سیاق و سباق کا ویکٹر تمام انکوڈر پوشیدہ حالتوں کے وزنی مجموعہ کے طور پر شمار کیا جاتا ہے۔ $$c_t = \sum_j \alpha_{t, j} h_j$$
- ٹوکن کی پیشن گوئی: ڈیکوڈر متحرک سیاق و سباق کے ویکٹر $c_t$ کو اپنی موجودہ حالت $s_t$ کے ساتھ ملا کر اگلے آؤٹ پٹ ٹوکن کی پیشن گوئی کرتا ہے۔
4. Seq2Seq اور اٹینشن میکانزم کا تفصیلی جائزہ
ان میکانزم کے پیچھے موجود انجینئرنگ کو حقیقی معنوں میں سمجھنے کے لیے، آئیے پہلے کلاسک Sequence-to-Sequence آرکیٹیکچر کے ریاضیاتی اور آپریشنل مراحل کو دیکھیں، اور اس کے بعد Bahdanau (اضافی) اور Luong (ضرب) دونوں اٹینشن کے طریقوں کا جائزہ لیا جائے گا۔
بنیادی خاکہ: کلاسیکی Sequence-to-Sequence آرکیٹیکچر کا تفصیلی جائزہ (بغیر اٹینشن کے)
اٹینشن میکانزم کو سمجھنے سے پہلے، آئیے دیکھتے ہیں کہ ایک عام Sequence-to-Sequence (اینکوڈر-ڈیکوڈر) ماڈل کس طرح ترتیب وار معلومات کو پروسیس کرتا ہے:
- اینکوڈنگ کا مرحلہ:
ان پٹ ترتیب $x_1, x_2, \dots, x_T$ کے لیے:
- ہر ٹائم سٹیپ $t$ पर، اینکوڈر کا ریکرنٹ سیل (LSTM/GRU) موجودہ ان پٹ ٹوکن $x_t$ اور پچھلی پوشیدہ حالت $h_{t-1}$ کی بنیاد پر اپنی پوشیدہ حالت $h_t$ کو اپ ڈیٹ کرتا ہے: $$h_t = \text{RNN}{\text{enc}}(x_t, h{t-1})$$
- کانٹیکسٹ ویکٹر بننا:
- اینکوڈر کی آخری پوشیدہ حالت $h_T$ دراصل کانٹیکسٹ ویکٹر $c$ (مستحکم بوٹلنیک نمائندگی) کے طور पर کام کرتی ہے: $$c = h_T$$
- ڈیکوڈینگ مرحلے کا آغاز:
- ڈیکوڈر ریکرنٹ سیل کی ابتدائی پوشیدہ حالت $s_0$ کو براہ راست کانٹیکسٹ ویکٹر $c$ کے ساتھ شروع کیا جاتا ہے: $$s_0 = c$$
- ڈیکوڈر کا آٹوریگریسو مرحلہ:
- ہر ڈیکوڈینگ ٹائم سٹیپ $t$ پر، ڈیکوڈر پچھلے پیش گوئی شدہ ٹوکن $y_{t-1}$ اور پچھلی پوشیدہ حالت $s_{t-1}$ کی بنیاد پر اپنی پوشیدہ حالت $s_t$ کو اپ ڈیٹ کرتا ہے: $$s_t = \text{RNN}{\text{dec}}(y{t-1}, s_{t-1})$$
- ٹوکن کی پیش گوئی:
- اگلے ٹوکن $y_t$ کی امکانی تقسیم کا حساب ڈیکوڈر حالت $s_t$ پر لینیئر لیئر اور سافٹ میکس ایکٹیویشن لاگو کر کے لگایا جاتا ہے: $$p(y_t | y_{<t}) = \text{softmax}(W_y s_t + b_y)$$
طریقہ 1: باہداناؤ (اضافی) اٹینشن کا جائزہ
باہداناؤ اٹینشن کو اضافی اٹینشن (additive attention) بھی کہا جاتا ہے کیونکہ یہ فیڈ فارورڈ نیورل نیٹ ورک لیئر کا استعمال کرتے ہوئے الائنمنٹ اسکورز کا حساب لگاتا ہے۔ یہ “سابقہ حالت” (previous-state) کے بہاؤ پر کام کرتا ہے:
- شروعات / انحصار: ڈیکوڈنگ کے مرحلے $t$ پر، ڈیکوڈر اٹینشن کا حساب لگانے کے لیے اپنی پچھلی پوشیدہ اسٹیٹ $s_{t-1}$ اور انکوڈر کی پوشیدہ اسٹیٹس $h_j$ (تمام ان پٹ مراحل $j$ کے لیے) استعمال کرتا ہے۔
- الائنمنٹ اسکورز کا حساب (اضافی): $$e_{t, j} = v_a^T \tanh(W_a s_{t-1} + U_a h_j)$$ یہاں، $W_a$ اور $U_a$ ایسے وزن کے میٹرکس ہیں جو سیکھنے کی صلاحیت رکھتے ہیں اور ڈیکوڈر اسٹیٹ اور انکوڈر اسٹیٹس کو ایک مشترکہ اسپیس پر پروجیکٹ کرتے ہیں۔ ان کا مجموعہ ایک $\tanh$ ایکٹیویشن فنکشن سے گزارا جاتا ہے، اور پھر ویٹ ویکٹر $v_a$ کا استعمال کرتے ہوئے ایک سکیلر پر پروجیکٹ کیا جاتا ہے۔
- اٹینشن ویٹس کا حساب (Softmax): $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$ یہ الائنمنٹ اسکورز کو ان پٹ ترتیب پر ایک امکانی تقسیم (probability distribution) میں تبدیل کرتا ہے۔
- متحرک سیاق و سباق کا ویکٹر (Context Vector) بنانا: $$c_t = \sum_j \alpha_{t, j} h_j$$ یہ انکوڈر کی پوشیدہ اسٹیٹس کا ایک وزنی مجموعہ ہے، جو ان پٹ تسلسل کے ان حصوں کی نمائندگی کرتا ہے جن پر ماڈل کو توجہ مرکوز کرنی چاہیے۔
- ڈیکوڈر کی پوشیدہ اسٹیٹ کو اپ ڈیٹ کرنا: سیاق و سباق کے ویکٹر $c_t$ کو پچھلے آؤٹ پٹ ٹوکن $y_{t-1}$ کے ایمبیڈنگ کے ساتھ ملا دیا جاتا ہے، اور اسے ڈیکوڈر کے تکراری سیل میں بھیجا جاتا ہے تاکہ موجودہ ڈیکوڈر اسٹیٹ $s_t$ کا حساب لگایا جا سکے: $$s_t = \text{RNN}(s_{t-1}, [c_t; y_{t-1}])$$
- ٹوکن کی پیش گوئی: موجودہ اسٹیٹ $s_t$ کا استعمال اگلے ٹوکن کے امکان کی پیش گوئی کے لیے کیا جاتا ہے۔
طریقہ 2: لونگ (ضرب) اٹینشن کا جائزہ
لونگ اٹینشن، جو باہداناؤ کے کچھ ہی عرصہ بعد متعارف کرائی گئی تھی، کو ضرب اٹینشن (multiplicative attention) کہا جاتا ہے۔ یہ حساب کتاب کو آسان بناتا ہے اور “موجودہ حالت” (current-state) کے بہاؤ پر انحصار کرتا ہے:
- پہلے ڈیکوڈر کی پوشیدہ اسٹیٹ کو اپ ڈیٹ کریں: ڈیکوڈنگ کے مرحلے $t$ پر، ڈیکوڈر سب سے پہلے عام تکراری منتقلی کا استعمال کرتے ہوئے اپنی پوشیدہ اسٹیٹ کو $s_t$ پر اپ ڈیٹ کرتا ہے، جس میں صرف پچھلی اسٹیٹ $s_{t-1}$ اور پچھلے آؤٹ پٹ ٹوکن $y_{t-1}$ کا استعمال کیا جاتا ہے: $$s_t = \text{RNN}(s_{t-1}, y_{t-1})$$
- الائنمنٹ اسکورز کا حساب (ضرب):
لونگ نے تین متبادل اسکور فنکشنز تجویز کیے۔ سب سے زیادہ استعمال ہونے والا General فارم ہے، جو میٹرکس ضرب کا استعمال کرتا ہے:
- General: $e_{t, j} = s_t^T W_a h_j$
- Dot: $e_{t, j} = s_t^T h_j$ (فرض کرتا ہے کہ دونوں کی ابعاد یکساں ہیں)
- Concat: $e_{t, j} = v_a^T \tanh(W_a [s_t; h_j])$ ضرب اٹینشن اضافی اٹینشن کے مقابلے میں حساب کتاب میں تیز اور میموری کے لحاظ سے زیادہ موثر ہے کیونکہ اس کا حساب انتہائی بہتر میٹرکس ضرب کے آپریشنز کا استعمال کرتے ہوئے کیا جا سکتا ہے۔
- اٹینشن ویٹس کا حساب (Softmax): $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$
- متحرک سیاق و سباق کا ویکٹر بنانا: $$c_t = \sum_j \alpha_{t, j} h_j$$
- توجہ پر مبنی پوشیدہ اسٹیٹ (Attentional Hidden State) کا حساب: پیش گوئی کے لیے براہ راست ڈیکوڈر اسٹیٹ استعمال کرنے کے بجائے، سیاق و سباق کے ویکٹر $c_t$ اور موجودہ اسٹیٹ $s_t$ کو ایک لینیئر لیئر اور ایک $\tanh$ ایکٹیویشن کے ذریعے ملا کر ایک توجہ پر مبنی پوشیدہ اسٹیٹ $\tilde{s}_t$ تیار کی جاتی ہے: $$\tilde{s}_t = \tanh(W_c [c_t; s_t])$$
- ٹوکن کی پیش گوئی: توجہ پر مبنی پوشیدہ اسٹیٹ $\tilde{s}t$ کا استعمال حتمی پیش گوئی پیدا کرنے کے لیے کیا جاتا ہے: $$p(y_t | y{<t}, x) = \text{softmax}(W_s \tilde{s}_t)$$
معمارانہ موازنہ
| خصوصیت | باہداناؤ (اضافی) اٹینشن | لونگ (ضرب) اٹینشن |
|---|---|---|
| ریاضیاتی اسکور | ایک فیڈ فارورڈ نیٹ ورک استعمال کرتا ہے: $v_a^T \tanh(W_a s_{t-1} + U_a h_j)$ | ڈاٹ پروڈکٹ یا میٹرکس ضرب استعمال کرتا ہے: $s_t^T W_a h_j$ |
| استعمال شدہ ڈیکوڈر اسٹیٹ | ڈیکوڈر کی پچھلی پوشیدہ اسٹیٹ $s_{t-1}$ استعمال کرتا ہے۔ | ڈیکوڈر کی موجودہ پوشیدہ اسٹیٹ $s_t$ استعمال کرتا ہے۔ |
| حساب کتاب | زیادہ پیچیدہ، سست لیکن انتہائی لچکدار۔ | تیز تر، سادہ اور انتہائی موثر۔ |
5. اثرات: اٹینشن سے ٹرانسفارمرز تک
اٹینشن میکانزم کو شروع میں RNNs کو بہتر بنانے کے لیے ایک اضافی جزو کے طور پر ڈیزائن کیا گیا تھا۔ تاہم، جلد ہی محققین کو معلوم ہوا کہ اٹینشن لیئرز ہی سارا اہم کام کر رہی تھیں، جبکہ ریکرنٹ اسٹرکچرز (RNN/LSTM) ایک حسابی رکاوٹ کا باعث بن رہے تھے کیونکہ انہیں ٹوکنز کو سلسلہ وار پروسیس کرنا پڑتا تھا۔
2017 میں، محققین نے اپنا مشہور مقالہ “Attention Is All You Need” شائع کیا، جس نے Transformer آرکیٹیکچر متعارف کرایا۔ ٹرانسفارمر نے RNNs کو مکمل طور پر ترک کر دیا، اور متوازی طور پر پورے سلسلے کو پروسیس کرنے کے لیے صرف سیلف-اٹینشن (Self-Attention) پر انحصار کیا۔
یہ پیش رفت جدید لارج لینگویج ماڈلز (LLMs) جیسے کہ GPT-4، Gemini اور Claude کی بنیاد ہے، جس سے یہ ثابت ہوتا ہے کہ اٹینشن ہی جدید NLP کا سب سے طاقتور تصور ہے۔