פענוח ארכיטקטורת Sequence-to-Sequence ומנגנון הקשב (Attention)
בנוף של עיבוד שפה טבעית (NLP) ובינה מלאכותית, היכולת לתרגם שפות, לסכם מאמרים ולייצר תשובות שיחתיות עברה מהפכה עצומה. בלב הטרנספורמציה הזו עומדת ארכיטקטורת Sequence-to-Sequence (Seq2Seq) ומנגנון הקשב החלוצי (Attention Mechanism).
לפני הופעתם של מודלי ה-Transformer המודרניים, שני החידושים הללו פתרו את אחד האתגרים הגדולים ביותר של למידה עמוקה: מיפוי רצפי קלט לרצפי פלט כאשר אורכיהם שונים.
1. הבסיס: מה זה Sequence-to-Sequence (Seq2Seq)?
מודל ה-Sequence-to-Sequence (Seq2Seq), שהוצג בשנת 2014 על ידי חוקרים בגוגל ואחרים, הוא מסגרת מקודד-מפענח (Encoder-Decoder) שנועדה לעבד נתונים סדרתיים. הוא נמצא בשימוש נרחב במשימות שבהן אורך רצף הקלט אינו תואם לאורך רצף הפלט, כגון:
- תרגום מכונה: תרגום “How are you?” (3 מילים) לעברית “מה שלומך?” (2 מילים) או לספרדית “¿Cómo estás?” (2 מילים).
- סיכום טקסט: דחיסת מאמר של 500 מילים לסיכום של 50 מילים.
- מענה על שאלות: מיפוי רצף שאלות לרצף תשובות.
מנגנון המקודד-מפענח (Encoder-Decoder)
מודל ה-Seq2Seq הסטנדרטי מורכב משתי רשתות עצביות חוזרות (RNNs), בדרך כלל LSTMs (Long Short-Term Memory) או GRUs (Gated Recurrent Units):
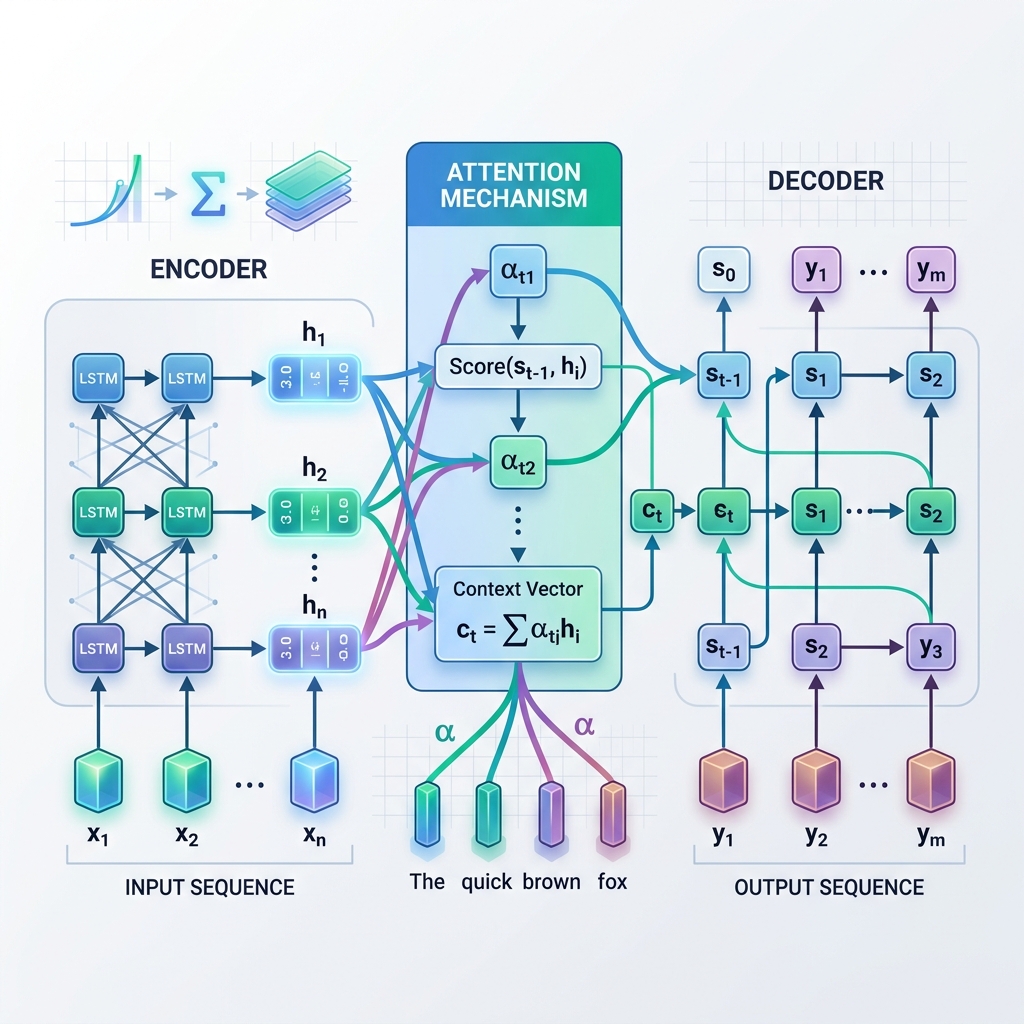
- המקודד (Encoder): מעבד את רצף הקלט אסימון אחר אסימון (token by token). בכל שלב, הוא מעדכן את המצב הנסתר שלו על בסיס אסימון הקלט הנוכחי והמצב הנסתר הקודם. לאחר עיבוד הקלט כולו, נלכד המצב הנסתר האחרון של המקודד. מצב סופי זה נקרא Context Vector (וקטור ההקשר או וקטור צוואר הבקבוק).
- המפענח (Decoder): לוקח את וקטור ההקשר כמצב הנסתר הראשוני שלו ומייצר את רצף הפלט אסימון אחר אסימון באופן אוטורגרסיבי. בכל שלב, הוא חוזה את המילה הבאה על סמך המצב הנסתר הנוכחי שלו והמילה שנוצרה קודם לכן.
2. בעיית צוואר הבקבוק (Information Bottleneck)
בעוד שמודל המקודד-מפענח הקלאסי היה פריצת דרך עצומה, הוא סבל ממגבלה בסיסית הידועה בשם צוואר בקבוק של מידע.
במודל Seq2Seq סטנדרטי, המקודד נאלץ לדחוס את כל המשמעות של משפט הקלט – ללא קשר לשאלה אם הוא מורכב מ-5 מילים או מ-100 מילים – לתוך וקטור הקשר יחיד בגודל קבוע.
כתוצאה מכך:
- אובדן זיכרון לטווח ארוך: עבור משפטים ארוכים יותר, החלקים המוקדמים של הרצף נשכחים עד שהמקודד מגיע לסוף.
- ירידה בביצועים: איכות התרגום או הסיכום יורדת באופן משמעותי ככל שאורך משפט הקלט עולה.
דחיסת פסקה מורכבת לוקטור בודד שקולה לניסיון לסכם פרק שלם של ספר במשפט אחד לפני תרגומו. מידע הולך לאיבוד באופן בלתי נמנע.
3. מנגנון הקשב (Attention): שינוי פרדיגמה
כדי לפתור את צוואר בקבוק המידע, דזמיטרי בהדנאו (Dzmitry Bahdanau) ועמיתיו הציגו את מנגנון הקשב בשנת 2015.
במקום להסתמך אך ורק על וקטור הקשר יחיד וסטטי מהשלב האחרון של המקודד, מנגנון הקשב מאפשר למפענח “להביט לאחור” בכל המצבים הנסתרים של המקודד בכל שלב בתהליך הפענוח. משמעות הדבר היא שהמודל מתמקד באופן דינמי (קשוב) בחלקים שונים של רצף הקלט בהתאם למילה שהוא מייצר באותו רגע.
כיצד פועל מנגנון הקשב: שלב אחר שלב
בכל שלב פענוח $t$:
- חישוב ציוני התאמה ($e_{t, j}$): המודל משווה את המצב הנסתר הנוכחי של המפענח $s_{t-1}$ עם כל מצב נסתר של המקודד $h_j$ כדי למדוד כמה מצב המקודד $j$ רלוונטי לשלב המפענח הנוכחי. $$e_{t, j} = \text{score}(s_{t-1}, h_j)$$
- חישוב משקולות הקשב ($\alpha_{t, j}$): ציוני ההתאמה מנורמלים באמצעות פונקציית softmax כדי להפוך אותם להסתברויות (משקולות) שסכומן הוא 1. $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$
- יצירת וקטור ההקשר הדינמי ($c_t$): וקטור ההקשר מחושב כסכום המשוקלל של כל המצבים הנסתרים של המקודד. $$c_t = \sum_j \alpha_{t, j} h_j$$
- חיזוי האסימון (Token): המפענח משלב את וקטור ההקשר הדינמי $c_t$ עם מצבו הנוכחי $s_t$ כדי לחזות את אסימון הפלט הבא.
4. סקירה מפורטת של מנגנוני Seq2Seq וקשב
כדי להעריך באמת את הנדסה שמאחורי מנגנונים אלו, נעקוב תחילה אחר השלבים המתמטיים והתפעוליים של ארכיטקטורת Sequence-to-Sequence הקלאסית, ולאחר מכן אחר גישות הקשב של Bahdanau (הוספתי) ו-Luong (כפלי).
בסיס השוואה: סקירה של ארכיטקטורת Sequence-to-Sequence קלאסית (ללא קשב)
לפני שנחקור את מנגנון הקשב, בואו נעקוב אחר האופן שבו ארכיטקטורת Sequence-to-Sequence (מקודד-מפענח) סטנדרטית מעבדת מידע בצורה סדרתית:
- שלב הקידود (Encoding):
עבור רצף קלט $x_1, x_2, \dots, x_T$:
- בכל צעד זמן $t$, התא הרקורנטי של המקודד (LSTM/GRU) מעדכן את המצב הנסתר שלו $h_t$ על בסיס טוקן הקלט הנוכחי $x_t$ והמצב הנסתר הקודם $h_{t-1}$: $$h_t = \text{RNN}{\text{enc}}(x_t, h{t-1})$$
- יצירת וקטור ההקשר (Context Vector):
- המצב הנסתר האחרון של המקודד $h_T$ משמש כוקטור ההקשר $c$ (ייצוג צוואר הבקבוק הסטטי): $$c = h_T$$
- אתחול שלב הפענוח:
- המצב הנסתר הראשוני $s_0$ של תא המפענح מאותחל ישירות עם וקטור ההקשר $c$: $$s_0 = c$$
- צעד הפענוח האוטו-רגרסיבי:
- בכל צעד זמן של פענוח $t$, המפענח מעדכן את המצב הנסתר שלו $s_t$ על בסיס הטוקن החזוי הקודם $y_{t-1}$ והמצב הנסתר הקודם $s_{t-1}$: $$s_t = \text{RNN}{\text{dec}}(y{t-1}, s_{t-1})$$
- חיזוי הטוקן:
- התפלגות ההסתברות עבור הטוקن הבא $y_t$ מחושבת באמצעות שכבה ליניארית ופונקציית softmax המופעלת על מצב המפענח $s_t$: $$p(y_t | y_{<t}) = \text{softmax}(W_y s_t + b_y)$$
גישה 1: סקירה של מנגנון הקשב של Bahdanau (חיבורי)
קשב בהדנאו נקרא גם קשב חיבורי (additive attention) מכיוون שהוא מחשב את ציוני ההתאמה (alignment scores) באמצעות שכבת רשת עצבית מסוג Feed-forward. הוא פועל תחת זרימת תלות של “מצב קודם”:
- אתחול / תלות: בשלב הפענוח $t$, המפענח משתמש במצב הנסתר הקודם שלו $s_{t-1}$ ובמצבים הנסתרים של המקودד $h_j$ (עבור כל שלבי הקלט $j$) כדי לחשב את הקשב.
- חישוב ציוני התאמה (חיבורי): $$e_{t, j} = v_a^T \tanh(W_a s_{t-1} + U_a h_j)$$ כאן, $W_a$ ו-$U_a$ הן מטריצות משקולות הניתנות ללמידה המקרינות את מצב המפענח ומצבי המקודד למרחב משותף. הסכום שלהן עובר דרך פונקציית הפעלה $\tanh$, ולאחר מכן מושלך לסקלר באמצעות וקטור המשקולות $v_a$.
- חישוב משקלי קשב (Softmax): $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$ זה מנרמל את ציוני ההתאמה להתפלגות הסתברות על פני רצף הקלט.
- יצירת וקטור הקשר דינמי: $$c_t = \sum_j \alpha_{t, j} h_j$$ זהו סכום משוקלל של המצבים הנסתרים של המקودד, המייצג את חלקי רצף הקלט שבהם המודל צריך להתמקד.
- עדכון המצב הנסתר של המפענח: וקטור ההקשר $c_t$ מחובר (concatenate) مع הווקטור המוטבע (embedding) של אסימון הפלט הקודם $y_{t-1}$, ומועבר לתא הרקורסיבי של המפענח כדי לחשב את מצב המפענח הנוכحی $s_t$: $$s_t = \text{RNN}(s_{t-1}, [c_t; y_{t-1}])$$
- חיזוי אסימון: המצב הנוכחי $s_t$ משמש לחיזוי ההסתברות של האסימון הבא.
גישה 2: סקירה של מנגנון הקשב של Luong (כפלי)
קשב לואונג, שהוצג זמן קצר לאחר זה של בהדנאו, מכונה קשב כפלי (multiplicative attention). הוא מפשט את החישוב ומסתמך על זרימת תלות של “מצב נוכחי”:
- עדכון המצב הנסתר של המפענח תחילה: בשלב הפענוח $t$, המפענח מעדכן תחילה את המצב הנסתר שלו ל-$s_t$ באמצעות המעבר הרקורסיבי הרגיל, תוך שימוש במצב הקודם $s_{t-1}$ ובאסימון הפלט הקודם $y_{t-1}$ בלבד: $$s_t = \text{RNN}(s_{t-1}, y_{t-1})$$
- חישוב ציוני התאמה (כפלי):
לואונג הציע שלוש פונקציות ציון חלופיות. הנפוצה ביותר היא צורת ה-General, המשתמשת בכפל מטריצות (ומכאן, כפלי):
- General: $e_{t, j} = s_t^T W_a h_j$
- Dot: $e_{t, j} = s_t^T h_j$ (מניח מימדיות זהה)
- Concat: $e_{t, j} = v_a^T \tanh(W_a [s_t; h_j])$ קשב כפלי מהיר יותר מבחינה חישובית וחסכוני יותר במקום מאשר קשב חיבורי, מכיוون שניתן לחשב אותו באמצעות פעולות כפל מטריצות ממוטבות ביותר.
- חישוב משקלי קשב (Softmax): $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$
- יצירת וקטור הקשר דינמי: $$c_t = \sum_j \alpha_{t, j} h_j$$
- חישוב המצב הנסתר הקשבי: במקום להשתמש במצב המפענח ישירות לחיזוי, וקטור ההקשר $c_t$ והמצב הנוכחי $s_t$ משולבים באמצעות שכבה ליניארית והפעלת $\tanh$ כדי לייצר מצב נסתר קשבי $\tilde{s}_t$: $$\tilde{s}_t = \tanh(W_c [c_t; s_t])$$
- חיזוי אסימון: המצב הנסתר הקשבי $\tilde{s}t$ משמש ליצירת החיזוי הסופי: $$p(y_t | y{<t}, x) = \text{softmax}(W_s \tilde{s}_t)$$
השוואה ארכיטקטונית
| מאפיין | קשב בהדנאו (Bahdanau - חיבורי) | קשב לואונג (Luong - כפלי) |
|---|---|---|
| חישוב מתמטי | משתמש ברשת הזנת קديמה (Feed-forward): $v_a^T \tanh(W_a s_{t-1} + U_a h_j)$ | משתמש במכפלה סקלרית או כפל מטריצות: $s_t^T W_a h_j$ |
| מצב מפענח בשימוש | משתמש במצב המפענח הקודם $s_{t-1}$. | משתמש במצב המפענח הנוכחי $s_t$. |
| חישוב | מורכב יותר, איטי יותר אך גמיש במיוחד. | מהיר יותר, פשוט יותר ויעיל ביותר. |
5. המורשת: מקשב ל-Transformers
מנגנון הקשב תוכנן בתחילה כתוספת לשיפור רשתות RNN. עם זאת, חוקרים הבינו מהר מאוד שכבות הקשב עושות את כל העבודה הקשה, בעוד המבנים המחזוריים (RNN/LSTM) שימשו כצוואר בקבוק חישובי מכיוון שהיו חייבים לעבד אסימונים באופן סדרתי.
בשנת 2017, חוקרים פרסמו את המאמר המכונן “Attention Is All You Need”, והציגו את ארכיטקטורת ה-Transformer. מודל ה-Transformer זנח לחלוטין את ה-RNNs, והסתמך אך ורק על Self-Attention (קשב עצמי) כדי לעבד רצפים שלמים במקביל.
פריצת דרך זו היא הבסיס למודלי שפה גדולים מודרניים (LLMs) כמו GPT-4, Gemini ו-Claude, המוכיחה שקשב הוא אכן הקונספט החזק ביותר ב-NLP המודרני.