揭秘序列到序列(Seq2Seq)架构与注意力(Attention)机制
在自然语言处理(NLP)和人工智能领域,机器翻译、文本摘要以及对话生成等技术在过去几年中经历了一场革命。这场变革的核心正是序列到序列(Seq2Seq)架构以及开创性的注意力(Attention)机制。
在现代 Transformer 架构诞生之前,这两大创新解决了深度学习领域最棘手的挑战之一:在输入序列和输出序列长度不同时,如何建立它们之间的映射。
1. 理论奠基:什么是序列到序列(Seq2Seq)?
序列到序列(Seq2Seq)模型由谷歌等机构的研究人员于 2014 年提出,它是一种专门用于处理序列数据的编码器-解码器(Encoder-Decoder)框架。它被广泛应用于输入序列长度与输出序列长度不一致的任务中,例如:
- 机器翻译: 将英文的 “How are you?"(3个单词)翻译为中文的“你好吗?”(3个汉字)或西班牙语的 “¿Cómo estás?"(2个单词)。
- 文本摘要: 将一篇 500 字的文章压缩为 50 字的摘要。
- 问答系统: 将问题序列映射到相应的回答序列。
编码器-解码器机制
标准的 Seq2Seq 模型由两个循环神经网络(RNN)组成,通常采用 LSTM(长短期记忆网络)或 GRU(门控循环单元):
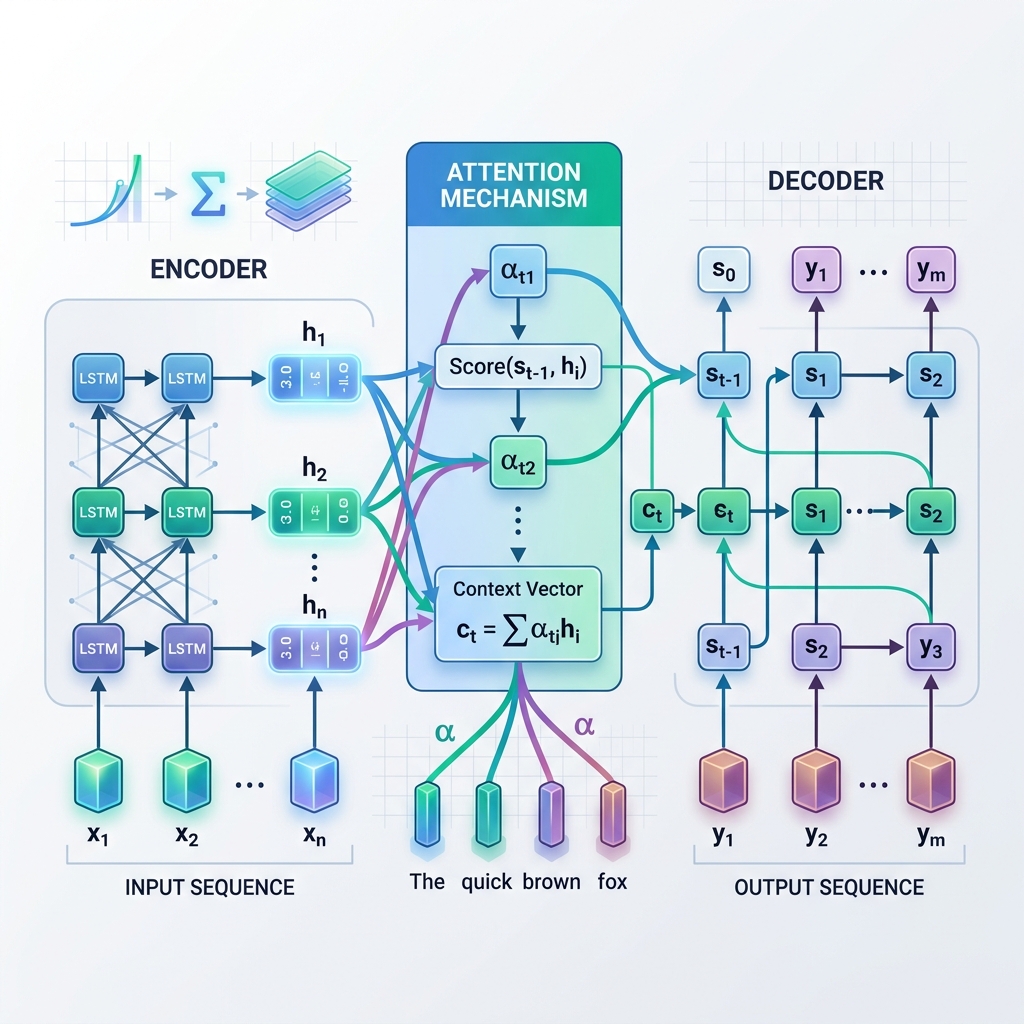
- 编码器(Encoder): 逐个 Token(词元)地处理输入序列。在每一步中,它会根据当前输入的 Token 和上一步的隐藏状态来更新隐藏状态。处理完整个输入后,编码器会提取最后一个隐藏状态。这个最终的隐藏状态被称为上下文向量(Context Vector)(或瓶颈向量)。
- 解码器(Decoder): 将上下文向量作为其初始隐藏状态,并以自回归的方式逐个 Token 地生成输出序列。在每一步中,它都会根据当前的隐藏状态和前一步生成的单词来预测下一个单词。
2. 瓶颈问题(Bottleneck Problem)
虽然经典的编码器-解码器模型是一项巨大的技术突破,但它存在一个致命的局限性,即信息瓶颈(Information Bottleneck)。
在标准的 Seq2Seq 模型中,编码器被迫将输入句子的完整语义——无论它是 5 个词还是 100 个词——全部压缩进一个固定大小的上下文向量中。
这导致了以下问题:
- 长期记忆丢失(Long-Term Memory Loss): 对于长句子,当编码器处理到序列末尾时,序列开头的语义信息已经被稀释或遗忘。
- 性能严重衰退: 随着输入句子长度的增加,翻译或摘要的质量会显著下降。
将复杂的长篇大论压缩进单一向量,就如同在翻译整章书之前,尝试用一句话来概括它一样。信息在这一压缩过程中不可避免地会丢失。
3. 注意力机制:一场范式转变
为了打破这一信息瓶颈,Dzmitry Bahdanau 等人于 2015 年引入了注意力机制(Attention Mechanism)。
注意力机制不再仅仅依赖编码器最后一个时间步输出的单一、静态上下文向量,而是允许解码器在解码过程的每一步中,**“回看”**编码器的所有中间隐藏状态。这意味着模型能够根据当前正在生成的单词,动态地聚焦(即施加注意力)于输入序列的不同部分。
注意力机制工作原理:步步拆解
在每一个解码步骤 $t$:
- 计算对齐得分(Alignment Scores, $e_{t, j}$): 模型将当前的解码器隐藏状态 $s_{t-1}$ 与编码器的每一个隐藏状态 $h_j$ 进行对比,以衡量编码器状态 $j$ 与当前解码步骤的相关度。 $$e_{t, j} = \text{score}(s_{t-1}, h_j)$$
- 计算注意力权重(Attention Weights, $\alpha_{t, j}$): 利用 Softmax 函数对对齐得分进行归一化,将其转化为概率分布(权重),所有权重之和为 1。 $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$
- 生成动态上下文向量($c_t$): 将所有编码器隐藏状态进行加权求和,得到当前步骤的上下文向量。 $$c_t = \sum_j \alpha_{t, j} h_j$$
- 预测 Token: 解码器结合动态上下文向量 $c_t$ 与其当前状态 $s_t$,来预测下一个输出 Token。
4. Seq2Seq 与注意力机制的详细工作流程
为了真正理解这些机制背后的工程原理,让我们先探讨经典序列到序列架构的数学和操作步骤,然后探讨 Bahdanau(加法)和 Luong(乘法)注意力机制的工作流程。
基线:经典序列到序列(Seq2Seq)架构工作流程(无注意力)
在探索注意力机制之前,让我们先了解标准的序列到序列(Encoder-Decoder)架构是如何按顺序处理信息的:
- 编码阶段:
对于输入序列 $x_1, x_2, \dots, x_T$:
- 在每个时间步 $t$,编码器循环单元(LSTM/GRU)根据当前输入标记 $x_t$ 和前一个隐藏状态 $h_{t-1}$ 更新其隐藏状态 $h_t$: $$h_t = \text{RNN}{\text{enc}}(x_t, h{t-1})$$
- 上下文向量生成:
- 编码器最后的隐藏状态 $h_T$ 作为上下文向量 $c$(静态瓶颈表征): $$c = h_T$$
- 解码阶段初始化:
- 解码器循环单元的初始隐藏状态 $s_0$ 直接由上下文向量 $c$ 初始化: $$s_0 = c$$
- 解码器自回归步骤:
- 在每个解码时间步 $t$,解码器根据前一个预测的标记 $y_{t-1}$ 和前一个隐藏状态 $s_{t-1}$ 更新其隐藏状态 $s_t$: $$s_t = \text{RNN}{\text{dec}}(y{t-1}, s_{t-1})$$
- 标记预测:
- 下一个标记 $y_t$ 的概率分布是通过对解码器状态 $s_t$ 应用线性层和 softmax 激活函数计算得出的: $$p(y_t | y_{<t}) = \text{softmax}(W_y s_t + b_y)$$
方法 1:Bahdanau(加性)注意力机制工作流程
Bahdanau 注意力也被称为加性注意力(Additive Attention),因为它是通过一个前馈神经网络层来计算对齐得分的。它基于“前一状态”(Previous-state)的依赖关系流运行:
- 初始化与依赖项:在解码步骤 $t$,解码器使用其前一个隐藏状态 $s_{t-1}$ 和编码器隐藏状态 $h_j$(对于所有输入步骤 $j$)来计算注意力。
- 计算对齐得分(加性): $$e_{t, j} = v_a^T \tanh(W_a s_{t-1} + U_a h_j)$$ 其中,$W_a$ 和 $U_a$ 是可学习的权重矩阵,用于将解码器状态和编码器状态投影到共享空间。它们的和通过 $\tanh$ 激活函数,然后使用权重向量 $v_a$ 投影为标量。
- 计算注意力权重(Softmax): $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$ 这将对齐得分归一化为输入序列上的概率分布。
- 生成动态上下文向量: $$c_t = \sum_j \alpha_{t, j} h_j$$ 这是编码器隐藏状态的加权和,代表模型应该重点关注的输入序列部分。
- 更新解码器隐藏状态: 上下文向量 $c_t$ 与前一个输出词元 $y_{t-1}$ 的嵌入拼接在一起,然后传入解码器的循环单元,计算出当前的解码器状态 $s_t$: $$s_t = \text{RNN}(s_{t-1}, [c_t; y_{t-1}])$$
- 预测词元: 使用当前状态 $s_t$ 来预测下一个词元的概率。
方法 2:Luong(乘性)注意力机制工作流程
Luong 注意力机制在 Bahdanau 之后不久提出,被称为乘性注意力(Multiplicative Attention)。它简化了计算,并依赖于“当前状态”(Current-state)的依赖关系流运行:
- 首先更新解码器隐藏状态: 在解码步骤 $t$,解码器首先使用正常的循环过渡更新其隐藏状态至 $s_t$,此时仅使用前一个状态 $s_{t-1}$ 和前一个输出词元 $y_{t-1}$: $$s_t = \text{RNN}(s_{t-1}, y_{t-1})$$
- 计算对齐得分(乘性):
Luong 提出了三种备选的得分函数。最常用的是 General(通用)形式,它使用矩阵乘法(因此是乘性的):
- General: $e_{t, j} = s_t^T W_a h_j$
- Dot: $e_{t, j} = s_t^T h_j$ (假设维度相同)
- Concat: $e_{t, j} = v_a^T \tanh(W_a [s_t; h_j])$ 乘性注意力在计算上比加性注意力更快、更节省空间,因为它可以通过高度优化的矩阵乘法操作来完成。
- 计算注意力权重(Softmax): $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$
- 生成动态上下文向量: $$c_t = \sum_j \alpha_{t, j} h_j$$
- 计算注意力隐藏状态: 不直接使用解码器状态进行预测,而是将上下文向量 $c_t$ 和当前状态 $s_t$ 通过一个线性层和 $\tanh$ 激活相结合,生成注意力隐藏状态 $\tilde{s}_t$: $$\tilde{s}_t = \tanh(W_c [c_t; s_t])$$
- 预测词元: 使用注意力隐藏状态 $\tilde{s}t$ 来生成最终的预测: $$p(y_t | y{<t}, x) = \text{softmax}(W_s \tilde{s}_t)$$
架构对比
| 特性 | Bahdanau(加性)注意力 | Luong(乘性)注意力 |
|---|---|---|
| 数学得分 | 使用前馈网络:$v_a^T \tanh(W_a s_{t-1} + U_a h_j)$ | 使用点积或矩阵乘法:$s_t^T W_a h_j$ |
| 使用的解码器状态 | 使用前一个解码器状态 $s_{t-1}$。 | 使用当前解码器状态 $s_t$。 |
| 计算 | 更复杂、更慢,但高度灵活。 | 更快、更简单且高效。 |
5. 技术遗产:从注意力机制到 Transformer
最初,注意力机制仅被设计为增强 RNN 的辅助组件。然而,研究人员很快意识到,真正起到关键作用的是注意力层本身,而循环神经网络结构(RNN/LSTM)因为必须串行处理 Token,反而成为了计算效率的瓶颈。
2017 年,谷歌团队发表了具有里程碑意义的论文 “Attention Is All You Need”,正式推出了 Transformer 架构。Transformer 彻底抛弃 space 了 RNN 结构,完全依赖**自注意力(Self-Attention)**机制来并行处理整条序列。
这一突破奠定了现代大语言模型(LLM,如 GPT-4、Gemini 和 Claude)的基石,证明了“注意力”确实是现代自然语言处理中最强大、最核心的技术概念。