Demistificare l'Architettura Sequence-to-Sequence e il Meccanismo di Attenzione
Nel panorama del Natural Language Processing (NLP) e dell’intelligenza artificiale, la capacità di tradurre lingue, riassumere articoli e generare risposte conversazionali ha subito una rivoluzione. Al centro di questa trasformazione si trovano l’architettura Sequence-to-Sequence (Seq2Seq) e il pionieristico Meccanismo di Attenzione.
Prima dell’avvento dei moderni Transformer, queste due innovazioni hanno risolto una delle più grandi sfide del deep learning: mappare sequenze di input su sequenze di output quando le loro lunghezze differiscono.
1. La Fondazione: Cos’è il Sequence-to-Sequence (Seq2Seq)?
Introdotto nel 2014 dai ricercatori di Google e altri, il modello Sequence-to-Sequence (Seq2Seq) è un framework encoder-decoder progettato per elaborare dati sequenziali. È ampiamente utilizzato in compiti in cui la lunghezza della sequenza di input non corrisponde alla lunghezza della sequenza di output, come:
- Traduzione automatica: Tradurre “How are you?” (3 parole) in italiano “Come stai?” (2 parole) o francese “Comment allez-vous?” (3 parole).
- Riassunto del testo: Comprimere un articolo di 500 parole in un riassunto di 50 parole.
- Risposta alle domande: Mappare una sequenza di domande su una sequenza di risposte.
Il meccanismo Encoder-Decoder
Il modello Seq2Seq standard consiste in due reti neurali ricorrenti (RNN), tipicamente LSTM (Long Short-Term Memory) o GRU (Gated Recurrent Units):
- L’Encoder: Elabora la sequenza di input token dopo token. Ad ogni passaggio, aggiorna il suo stato nascosto in base al token di input corrente e allo stato nascosto precedente. Una volta elaborato l’intero input, viene catturato lo stato nascosto finale dell’Encoder. Questo stato finale è chiamato Vettore di Contesto (o vettore collo di bottiglia).
- Il Decoder: Prende il Vettore di Contesto come suo stato nascosto iniziale e genera la sequenza di output token dopo token in modo autoregressivo. Ad ogni passaggio, prevede la parola successiva in base al suo stato nascosto corrente e alla parola precedentemente generata.
2. Il problema del collo di bottiglia (Information Bottleneck)
Sebbene il classico modello Encoder-Decoder sia stato una svolta enorme, soffriva di una limitazione fondamentale nota come collo di bottiglia dell’informazione.
In un modello Seq2Seq standard, l’Encoder è costretto a comprimere l’intero significato di una frase di input (indipendentemente dal fatto che sia di 5 o 100 parole) in un unico Vettore di Contesto di dimensione fissa.
Di conseguenza:
- Perdita di memoria a lungo termine: Per le frasi più lunghe, le prime parti della sequenza vengono dimenticate nel momento in cui l’Encoder raggiunge la fine.
- Degrado delle prestazioni: La qualità della traduzione o del riassunto diminuisce notevolmente all’aumentare della lunghezza della frase di input.
Comprimere un paragrafo complesso in un singolo vettore equivale a cercare di riassumere un intero capitolo di un libro in una sola frase prima di tradurlo. Le informazioni vanno inevitabilmente perse.
3. Il Meccanismo di Attenzione: Un cambio di paradigma
Per risolvere il collo di bottiglia dell’informazione, Dzmitry Bahdanau e colleghi hanno introdotto il Meccanismo di Attenzione nel 2015.
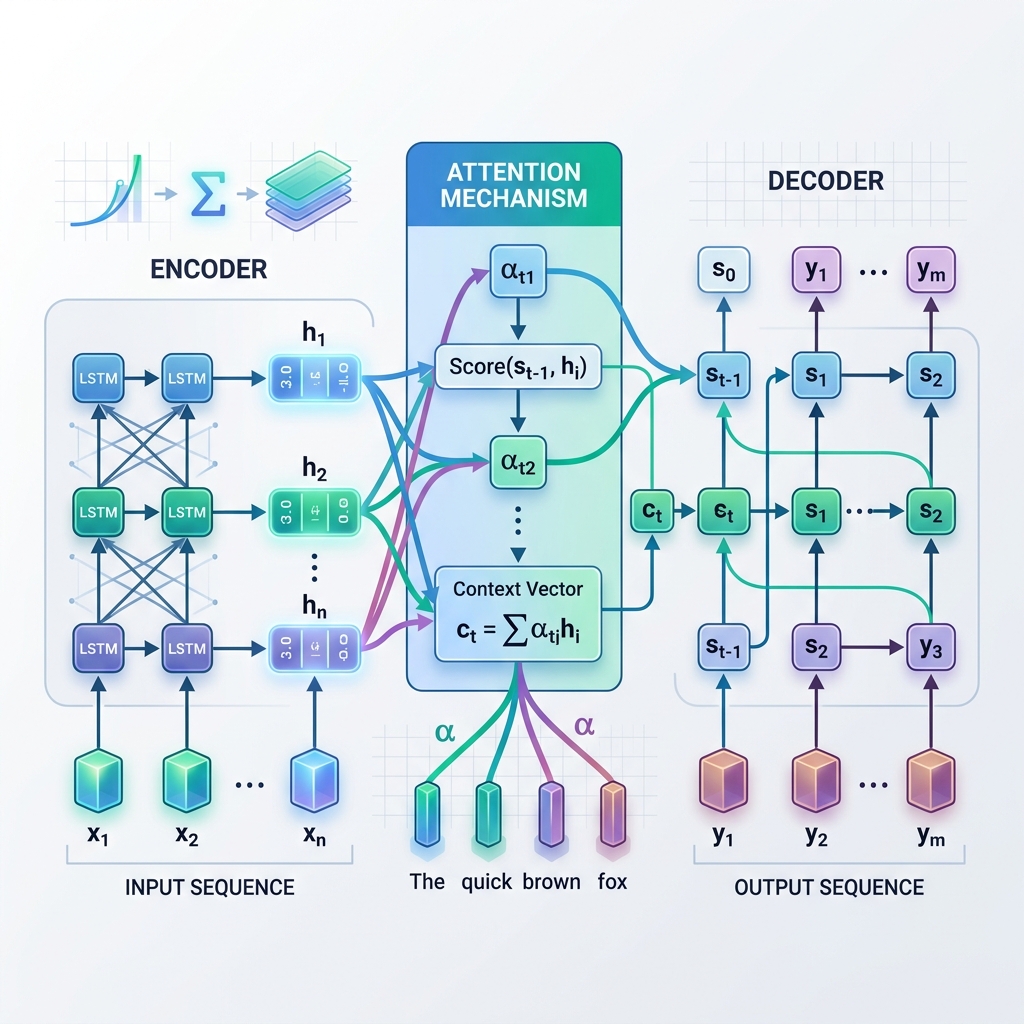
Invece di affidarsi esclusivamente a un singolo Vettore di Contesto statico derivato dalla fase finale dell’Encoder, l’Attenzione consente al Decoder di “guardare indietro” a tutti gli stati nascosti intermedi dell’Encoder in ogni fase del processo di decodifica. Ciò significa che il modello si concentra dinamicamente (presta attenzione) su diverse parti della sequenza di input a seconda della parola che sta attualmente generando.
Come funziona l’Attenzione: Passo dopo passo
Ad ogni fase di decodifica $t$:
- Calcolo dei punteggi di allineamento ($e_{t, j}$): Il modello confronta lo stato nascosto del decoder corrente $s_{t-1}$ con ciascuno stato nascosto dell’encoder $h_j$ per misurare quanto lo stato dell’encoder $j$ sia rilevante per il passaggio corrente del decoder. $$e_{t, j} = \text{score}(s_{t-1}, h_j)$$
- Calcolo dei pesi di attenzione ($\alpha_{t, j}$): I punteggi di allineamento vengono normalizzati utilizzando una funzione softmax per trasformarli in probabilità (pesi) che sommano a 1. $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$
- Generazione del Vettore di Contesto Dinamico ($c_t$): Il vettore di contesto viene calcolato come somma ponderata di tutti gli stati nascosti dell’encoder. $$c_t = \sum_j \alpha_{t, j} h_j$$
- Previsione del Token: Il decoder combina il vettore di contesto dinamico $c_t$ con il suo stato corrente $s_t$ per prevedere il successivo token di output.
4. Walkthrough dettagliato dei meccanismi Seq2Seq e Attention
Per apprezzare appieno l’ingegneria dietro questi meccanismi, tracciamo i passaggi matematici e operativi della classica architettura Sequence-to-Sequence, seguiti dagli approcci di attenzione di Bahdanau (additivo) e Luong (moltiplicativo).
Baseline: Walkthrough della classica architettura Sequence-to-Sequence (senza Attention)
Prima di esplorare l’attention, tracciamo come la classica architettura Sequence-to-Sequence (Encoder-Decoder) elabora le informazioni in modo sequenziale:
- Fase di Codifica:
Per una sequenza di input $x_1, x_2, \dots, x_T$:
- A ogni passo temporale $t$, la cella ricorrente dell’Encoder (LSTM/GRU) aggiorna il suo stato nascosto $h_t$ in base al token di input corrente $x_t$ e allo stato nascosto precedente $h_{t-1}$: $$h_t = \text{RNN}{\text{enc}}(x_t, h{t-1})$$
- Generazione del Vettore di Contesto:
- Lo stato nascosto finale dell’encoder $h_T$ funge da vettore di contesto $c$ (la rappresentazione statica a collo di bottiglia): $$c = h_T$$
- Inizializzazione della Fase di Decodifica:
- Lo stato nascosto iniziale $s_0$ della cella del Decoder viene inizializzato direttamente con il vettore di contesto $c$: $$s_0 = c$$
- Passo Autoregressivo del Decoder:
- A ogni passo temporale di decodifica $t$, il Decoder aggiorna il suo stato nascosto $s_t$ in base al token precedentemente predetto $y_{t-1}$ e allo stato nascosto precedente $s_{t-1}$: $$s_t = \text{RNN}{\text{dec}}(y{t-1}, s_{t-1})$$
- Predizione del Token:
- La distribuzione di probabilità per il token successivo $y_t$ viene calcolata utilizzando un livello lineare e un’attivazione softmax applicata allo stato del decoder $s_t$: $$p(y_t | y_{<t}) = \text{softmax}(W_y s_t + b_y)$$
Approccio 1: Walkthrough dell’attenzione di Bahdanau (additiva)
L’attenzione di Bahdanau è chiamata anche attenzione additiva perché calcola i punteggi di allineamento utilizzando uno strato di rete neurale feed-forward. Funziona secondo un flusso di dipendenza dallo “stato precedente”:
- Inizializzazione / Dipendenza: Al passaggio di decodifica $t$, il decoder utilizza il suo stato nascosto precedente $s_{t-1}$ e gli stati nascosti dell’encoder $h_j$ (per tutti i passaggi di input $j$) per calcolare l’attenzione.
- Calcolo dei punteggi di allineamento (Additivo): $$e_{t, j} = v_a^T \tanh(W_a s_{t-1} + U_a h_j)$$ Qui, $W_a$ and $U_a$ sono matrici di pesi apprendibili che proiettano lo stato del decoder e gli stati dell’encoder in uno spazio condiviso. La loro somma viene passata attraverso una funzione di attivazione $\tanh$, e quindi proiettata su uno scalare utilizzando il vettore di pesi $v_a$.
- Calcolo dei pesi di attenzione (Softmax): $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$ Questo normalizza i punteggi di allineamento in una distribuzione di probabilità sulla sequenza di input.
- Generazione del vettore di contesto dinamico: $$c_t = \sum_j \alpha_{t, j} h_j$$ Questa è una somma ponderata degli stati nascosti dell’encoder, che rappresenta le parti della sequenza di input su cui il modello dovrebbe concentrarsi.
- Aggiornamento dello stato nascosto del decoder: Il vettore di contesto $c_t$ viene concatenato con l’embedding del token di output precedente $y_{t-1}$, e passato alla cella ricorrente del decoder per calcolare lo stato del decoder corrente $s_t$: $$s_t = \text{RNN}(s_{t-1}, [c_t; y_{t-1}])$$
- Predizione del token: Lo stato corrente $s_t$ viene utilizzato per prevedere la probabilità del token successivo.
Approccio 2: Walkthrough dell’attenzione di Luong (moltiplicativa)
L’attenzione di Luong, introdotta poco dopo quella di Bahdanau, è indicata come attenzione moltiplicativa. Semplifica il calcolo e si affida a un flusso di dipendenza dallo “stato corrente”:
- Prima si aggiorna lo stato nascosto del decoder: Al passaggio di decodifica $t$, il decoder aggiorna prima il suo stato nascosto in $s_t$ utilizzando la normale transizione ricorrente, utilizzando solo lo stato precedente $s_{t-1}$ e il token di output precedente $y_{t-1}$: $$s_t = \text{RNN}(s_{t-1}, y_{t-1})$$
- Calcolo dei punteggi di allineamento (Moltiplicativo):
Luong ha proposto tre funzioni di punteggio alternative. La più utilizzata è la forma General, che utilizza una moltiplicazione di matrici (quindi, moltiplicativa):
- General: $e_{t, j} = s_t^T W_a h_j$
- Dot: $e_{t, j} = s_t^T h_j$ (presume uguale dimensionalità)
- Concat: $e_{t, j} = v_a^T \tanh(W_a [s_t; h_j])$ L’attenzione moltiplicativa è computazionalmente più veloce e più efficiente in termini di spazio rispetto all’attenzione additiva perché può essere calcolata utilizzando operazioni di moltiplicazione di matrici altamente ottimizzate.
- Calcolo dei pesi di attenzione (Softmax): $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$
- Generazione del vettore di contesto dinamico: $$c_t = \sum_j \alpha_{t, j} h_j$$
- Calcolo dello stato nascosto attentivo: Invece di utilizzare direttamente lo stato del decoder per la predizione, il vettore di contesto $c_t$ e lo stato corrente $s_t$ vengono combinati utilizzando uno strato lineare e un’attivazione $\tanh$ per produrre uno stato nascosto attentivo $\tilde{s}_t$: $$\tilde{s}_t = \tanh(W_c [c_t; s_t])$$
- Predizione del token: Lo stato nascosto attentivo $\tilde{s}t$ viene utilizzato per generare la predizione finale: $$p(y_t | y{<t}, x) = \text{softmax}(W_s \tilde{s}_t)$$
Confronto Architetturale
| Funzionalità | Attenzione Bahdanau (Additiva) | Attenzione Luong (Moltiplicativa) |
|---|---|---|
| Punteggio matematico | Utilizza una rete feed-forward: $v_a^T \tanh(W_a s_{t-1} + U_a h_j)$ | Utilizza il prodotto scalare o la moltiplicazione di matrici: $s_t^T W_a h_j$ |
| Stato del decoder utilizzato | Utilizza lo stato precedente del decoder $s_{t-1}$. | Utilizza lo stato corrente del decoder $s_t$. |
| Calcolo | Più complesso, lento ma altamente flessibile. | Più veloce, semplice e altamente efficiente. |
5. L’eredità: Dall’Attenzione ai Transformer
Il Meccanismo di Attenzione è stato inizialmente progettato come componente aggiuntivo per migliorare le RNN. Tuttavia, i ricercatori si sono presto resi conto che i livelli di attenzione facevano tutto il lavoro pesante, mentre le strutture ricorrenti (RNN/LSTM) fungevano da collo di bottiglia computazionale perché dovevano elaborare i token in modo sequenziale.
Nel 2017, i ricercatori hanno pubblicato il fondamentale documento “Attention Is All You Need”, introducendo l’architettura Transformer. Il Transformer ha eliminato completamente le RNN, affidandosi esclusivamente alla Self-Attention per elaborare intere sequenze in parallelo.
Questa svolta è alla base dei moderni Large Language Models (LLM) come GPT-4, Gemini e Claude, dimostrando che l’attenzione è davvero il concetto più potente nella moderna NLP.