Демистификация архитектуры Sequence-to-Sequence и механизма внимания (Attention)
В области обработки естественного языка (NLP) и искусственного интеллекта технологии машинного перевода, автоматического реферирования текстов и ведения диалога претерпели настоящую революцию. В основе этой трансформации лежит архитектура Sequence-to-Sequence (Seq2Seq) и новаторский механизм внимания (Attention Mechanism).
До появления современных трансформеров эти два нововведения решили одну из сложнейших задач глубокого обучения: сопоставление входных последовательностей с выходными при несовпадении их длины.
1. Основа: Что такое Sequence-to-Sequence (Seq2Seq)?
Модель Sequence-to-Sequence (Seq2Seq), представленная в 2014 году исследователями из Google и других компаний, представляет собой архитектуру типа «кодировщик-декодировщик» (encoder-decoder), разработанную для обработки последовательных данных. Она широко применяется в задачах, где длина входной последовательности отличается от длины выходной:
- Машинный перевод: перевод фразы “How are you?” (3 слова) на русский язык «Как дела?» (2 слова) или испанский “¿Cómo estás?” (2 слова).
- Суммаризация текста: сжатие статьи объемом 500 слов в краткую аннотацию из 50 слов.
- Вопросно-ответные системы: сопоставление последовательности слов вопроса с последовательностью слов ответа.
Механизм работы Кодировщика-Декодировщика
Стандартная модель Seq2Seq состоит из двух рекуррентных нейронных сетей (RNN), обычно LSTM (длинная краткосрочная память) или GRU (управляемый рекуррентный блок):
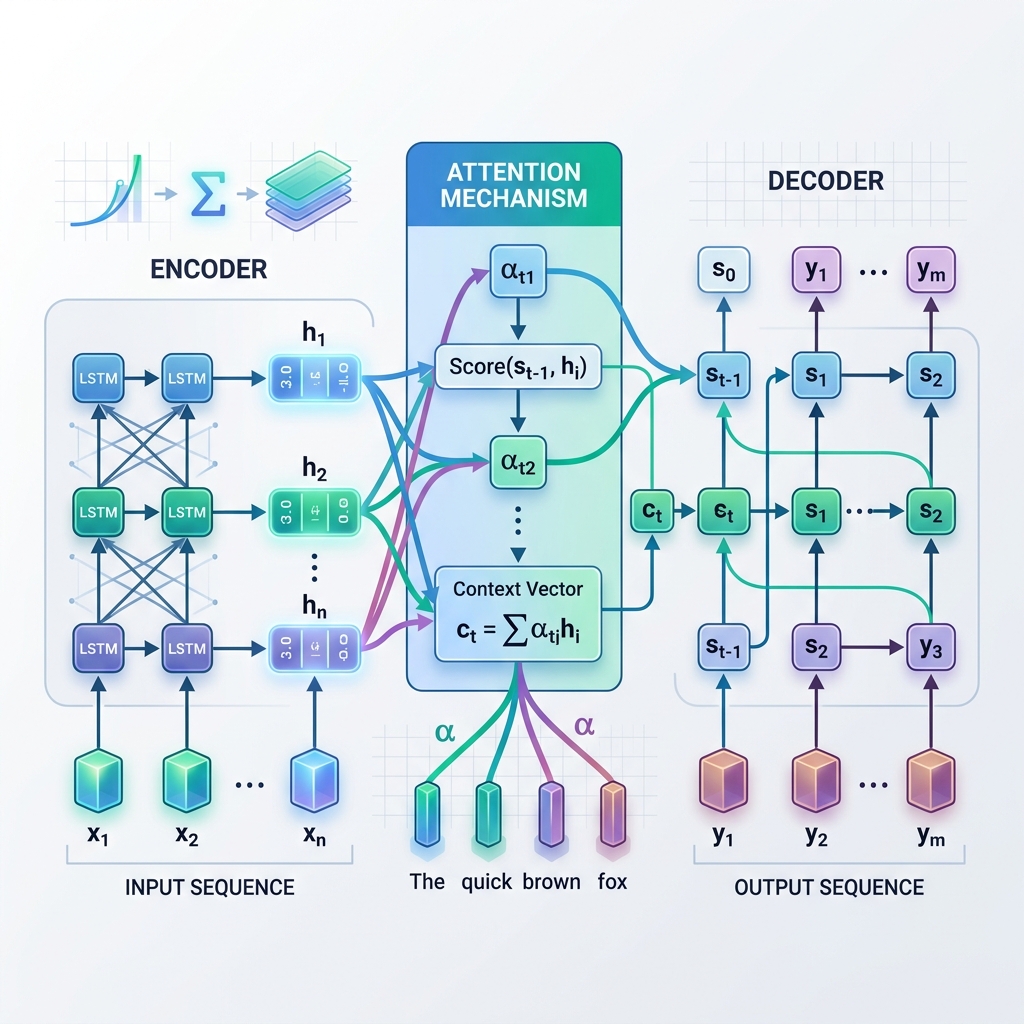
- Кодировщик (Encoder): последовательно обрабатывает входные данные токен за токеном. На каждом шаге он обновляет свое скрытое состояние на основе текущего входного токена и предыдущего скрытого состояния. После обработки всего входа фиксируется последнее скрытое состояние кодировщика. Это финальное состояние называется вектором контекста (Context Vector) или вектором «узкого горлышка».
- Декодировщик (Decoder): использует вектор контекста в качестве своего начального скрытого состояния и генерирует выходную последовательность авторегрессионно, токен за токеном. На каждом шаге он предсказывает следующее слово на основе своего текущего скрытого состояния и ранее сгенерированного слова.
2. Проблема «узкого горлышка» (Information Bottleneck)
Хотя классическая модель кодировщика-декодировщика стала огромным прорывом, она столкнулась с фундаментальным ограничением, известным как информационное узкое горлышко.
В стандартной модели Seq2Seq кодировщик вынужден сжимать весь смысл входного предложения — будь то 5 или 100 слов — в один вектор контекста фиксированного размера.
В результате:
- Потеря долгосрочной памяти: при обработке длинных предложений первые части последовательности забываются кодировщиком к моменту достижения конца предложения.
- Снижение качества работы: точность перевода или реферирования заметно ухудшается по мере увеличения длины входного текста.
Попытка сжать сложный абзац в один вектор эквивалентна попытке пересказать целую главу книги одним предложением перед ее переводом. Информация неизбежно теряется.
3. Механизм внимания: Смена парадигмы
Чтобы решить проблему узкого горлышка, Дзитри Багданау (Dzmitry Bahdanau) и его коллеги в 2015 году предложили механизм внимания (Attention Mechanism).
Вместо того чтобы полагаться исключительно на один статический вектор контекста с финального шага кодировщика, механизм внимания позволяет декодировщику «обращаться назад» к промежуточным скрытым состояниям кодировщика на каждом шаге декодирования. Это означает, что модель динамически фокусируется (направляет внимание) на разных частях входной последовательности в зависимости от того, какое слово она генерирует в данный момент.
Как работает механизм внимания: пошаговый процесс
На каждом шаге декодирования $t$:
- Вычисление оценок соответствия ($e_{t, j}$): модель сравнивает текущее скрытое состояние декодировщика $s_{t-1}$ с каждым скрытым состоянием кодировщика $h_j$, чтобы измерить релевантность состояния кодировщика $j$ для текущего шага декодирования. $$e_{t, j} = \text{score}(s_{t-1}, h_j)$$
- Вычисление весов внимания ($\alpha_{t, j}$): оценки соответствия нормализуются с помощью функции softmax для преобразования их в вероятности (веса), сумма которых равна 1. $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$
- Генерация динамического вектора контекста ($c_t$): вектор контекста рассчитывается как взвешенная сумма всех скрытых состояний кодировщика. $$c_t = \sum_j \alpha_{t, j} h_j$$
- Предсказание токена: декодировщик объединяет динамический вектор контекста $c_t$ со своим текущим состоянием $s_t$ для предсказания следующего выходного токена.
4. Подробный разбор механизмов Seq2Seq и внимания
Чтобы по-настоящему оценить инженерную мысль, стоящую за этими механизмами, давайте проследим математические и операционные шаги классической архитектуры Sequence-to-Sequence, а затем перейдем к подходам внимания Баданау (аддитивному) и Луонга (мультипликативному).
Базовый уровень: Разбор классической архитектуры Sequence-to-Sequence (без внимания)
Прежде чем переходить к механизму внимания, давайте проследим, как стандартная архитектура Sequence-to-Sequence (Encoder-Decoder) последовательно обрабатывает информацию:
- Этап кодирования:
Для входной последовательности $x_1, x_2, \dots, x_T$:
- На каждом временном шаге $t$ рекуррентная ячейка кодировщика (LSTM/GRU) обновляет свое скрытое состояние $h_t$ на основе текущего входного токена $x_t$ и предыдущего скрытого состояния $h_{t-1}$: $$h_t = \text{RNN}{\text{enc}}(x_t, h{t-1})$$
- Генерация вектора контекста:
- Финальное скрытое состояние кодировщика $h_T$ выступает в качестве вектора контекста $c$ (статического узкого места представления): $$c = h_T$$
- Инициализация этапа декодирования:
- Начальное скрытое состояние $s_0$ ячейки декодировщика инициализируется непосредственно вектором контекста $c$: $$s_0 = c$$
- Авторегрессионный шаг декодировщика:
- На каждом шаге декодирования $t$ декодировщик обновляет свое скрытое состояние $s_t$ на основе предыдущего предсказанного токена $y_{t-1}$ и предыдущего скрытого состояния $s_{t-1}$: $$s_t = \text{RNN}{\text{dec}}(y{t-1}, s_{t-1})$$
- Предсказание токена:
- Распределение вероятностей для следующего токена $y_t$ вычисляется с использованием линейного слоя и активации softmax, применяемой к состоянию декодировщика $s_t$: $$p(y_t | y_{<t}) = \text{softmax}(W_y s_t + b_y)$$
Подход 1: Разбор внимания Багданау (аддитивного)
Внимание Багданау также называют аддитивным вниманием (additive attention), поскольку оно вычисляет оценки соответствия с помощью полносвязного слоя нейронной сети. Оно работает по схеме зависимости от «предыдущего состояния»:
- Инициализация / Зависимость: На шаге декодирования $t$ декодировщик использует свое предыдущее скрытое состояние $s_{t-1}$ и скрытые состояния кодировщика $h_j$ (для всех входных шагов $j$) для расчета внимания.
- Вычисление оценок соответствия (Аддитивное): $$e_{t, j} = v_a^T \tanh(W_a s_{t-1} + U_a h_j)$$ Здесь $W_a$ и $U_a$ — обучаемые матрицы весов, которые проецируют состояние декодировщика и состояния кодировщика в общее пространство. Их сумма пропускается через функцию активации $\tanh$, а затем проецируется в скаляр с помощью вектора весов $v_a$.
- Вычисление весов внимания (Softmax): $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$ Это нормализует оценки соответствия в распределение вероятностей по входной последовательности.
- Генерация динамического вектора контекста: $$c_t = \sum_j \alpha_{t, j} h_j$$ Это взвешенная сумма скрытых состояний кодировщика, представляющая те части входной последовательности, на которых модель должна сконцентрироваться.
- Обновление скрытого состояния декодировщика: Вектор контекста $c_t$ объединяется с эмбеддингом предыдущего выходного токена $y_{t-1}$ и передается в рекуррентную ячейку декодировщика для расчета текущего состояния декодировщика $s_t$: $$s_t = \text{RNN}(s_{t-1}, [c_t; y_{t-1}])$$
- Предсказание токена: Текущее состояние $s_t$ используется для предсказания вероятности следующего токена.
Подход 2: Разбор внимания Луонга (мультипликативного)
Внимание Луонга, предложенное вскоре после Багданау, называют мультипликативным вниманием (multiplicative attention). Оно упрощает вычисления и опирается на схему зависимости от «текущего состояния»:
- Сначала обновление скрытого состояния декодировщика: На шаге декодирования $t$ декодировщик сначала обновляет свое скрытое состояние до $s_t$, используя обычный рекуррентный переход, при этом учитываются только предыдущее состояние $s_{t-1}$ и предыдущий выходной токен $y_{t-1}$: $$s_t = \text{RNN}(s_{t-1}, y_{t-1})$$
- Вычисление оценок соответствия (Мультипликативное):
Луонг предложил три альтернативные функции оценки. Наиболее распространенной является форма General, использующая матричное умножение (отсюда и название мультипликативного):
- General: $e_{t, j} = s_t^T W_a h_j$
- Dot: $e_{t, j} = s_t^T h_j$ (предполагает одинаковую размерность)
- Concat: $e_{t, j} = v_a^T \tanh(W_a [s_t; h_j])$ Мультипликативное внимание работает быстрее и экономит память по сравнению с аддитивным вниманием, поскольку его можно рассчитывать с помощью высокооптимизированных операций матричного умножения.
- Вычисление весов внимания (Softmax): $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$
- Генерация динамического вектора контекста: $$c_t = \sum_j \alpha_{t, j} h_j$$
- Вычисление скрытого состояния внимания: Вместо прямого использования состояния декодировщика для предсказания вектор контекста $c_t$ и текущее состояние $s_t$ объединяются с помощью линейного слоя и активации $\tanh$ для получения скрытого состояния внимания $\tilde{s}_t$: $$\tilde{s}_t = \tanh(W_c [c_t; s_t])$$
- Предсказание токена: Скрытое состояние внимания $\tilde{s}t$ используется для генерации окончательного предсказания: $$p(y_t | y{<t}, x) = \text{softmax}(W_s \tilde{s}_t)$$
Сравнение архитектур
| Параметр | Внимание Багданау (аддитивное) | Внимание Луонга (мультипликативное) |
|---|---|---|
| Математический расчет оценки | Использует полносвязную сеть: $v_a^T \tanh(W_a s_{t-1} + U_a h_j)$ | Использует скалярное произведение или матричное умножение: $s_t^T W_a h_j$ |
| Состояние декодировщика | Использует предыдущее состояние декодировщика $s_{t-1}$. | Использует текущее состояние декодировщика $s_t$. |
| Вычисления | Более сложное, медленное, но очень гибкое. | Более быстрое, простое и высокоэффективное. |
5. Наследие: от внимания к трансформерам
Первоначально механизм внимания создавался как надстройка для улучшения RNN. Однако вскоре исследователи поняли, что именно слои внимания выполняют всю основную работу, тогда как рекуррентные структуры (RNN/LSTM) служат вычислительным узким горлышком, поскольку обрабатывают токены последовательно.
В 2017 году была опубликована фундаментальная статья “Attention Is All You Need”, представившая архитектуру Transformer. Трансформер полностью отказался от RNN, полагаясь исключительно на само-внимание (Self-Attention) для параллельной обработки целых последовательностей.
Этот прорыв лежит в основе всех современных больших языковых моделей (LLM), таких как GPT-4, Gemini и Claude, доказывая, что концепция внимания является ключевой в современной обработке естественного языка.