Desmistificando a Arquitetura Sequence-to-Sequence e o Mecanismo de Atenção
No panorama do Processamento de Linguagem Natural (NLP) e da Inteligência Artificial, a capacidade de traduzir idiomas, resumir artigos e gerar respostas conversacionais passou por uma revolução. No coração dessa transformação está a arquitetura Sequence-to-Sequence (Seq2Seq) e o pioneiro Mecanismo de Atenção.
Antes do advento dos Transformers modernos, essas duas inovações resolveram um dos maiores desafios do aprendizado profundo: mapear sequências de entrada para sequências de saída quando seus comprimentos são diferentes.
1. A Fundação: O que é Sequence-to-Sequence (Seq2Seq)?
Introduzido em 2014 por pesquisadores do Google e outros, o modelo Sequence-to-Sequence (Seq2Seq) é uma estrutura de codificador-decodificador (encoder-decoder) projetada para processar dados sequenciais. É amplamente utilizado em tarefas onde o comprimento da sequência de entrada não corresponde ao comprimento da sequência de saída, como:
- Tradução Automática: Traduzir “How are you?” (3 palavras) para o português “Como você está?” (3 palavras) ou espanhol “¿Cómo estás?” (2 palavras).
- Resumo de Texto: Comprimir um artigo de 500 palavras em um resumo de 50 palavras.
- Sistemas de Perguntas e Respostas: Mapear uma sequência de perguntas para uma sequência de respostas.
O mecanismo codificador-decodificador
O modelo Seq2Seq padrão consiste em duas redes neurais recorrentes (RNN), tipicamente LSTMs (Long Short-Term Memory) ou GRUs (Gated Recurrent Units):
- O codificador (Encoder): Procesa a sequência de entrada token por token. A cada passo, atualiza seu estado oculto com base no token de entrada atual e no estado oculto anterior. Uma vez processada toda a entrada, o estado oculto final do codificador é capturado. Esse estado final é chamado de Vetor de Contexto (ou vetor de gargalo).
- O decodificador (Decoder): Toma o Vetor de Contexto como seu estado oculto inicial e gera a sequência de saída token por token de forma autorregressiva. A cada passo, prevê a próxima palavra com base em seu estado oculto atual e na palavra gerada anteriormente.
2. O problema do gargalo (Information Bottleneck)
Embora o clássico modelo codificador-decodificador tenha sido um enorme avanço, ele sofria de uma limitação fundamental conhecida como gargalo de informação.
Em um modelo Seq2Seq padrão, o codificador é forçado a comprimir todo o significado de uma frase de entrada — independentemente de ter 5 ou 100 palavras — em um único Vetor de Contexto de tamanho fixo.
Como resultado:
- Perda de memória de longo prazo: Para frases mais longas, as primeiras partes da sequência são esquecidas no momento em que o codificador chega ao fim.
- Degradação do desempenho: A qualidade da tradução ou do resumo diminui significativamente à medida que o comprimento da frase de entrada aumenta.
Comprimir um parágrafo complexo em um único vetor é equivalente a tentar resumir um capítulo inteiro de um livro em uma única frase antes de traduzi-lo. A informação é inevitavelmente perdida.
3. O Mecanismo de Atenção: Uma mudança de paradigma
Para resolver o gargalo de informação, Dzmitry Bahdanau e seus colegas introduziram o Mecanismo de Atenção em 2015.
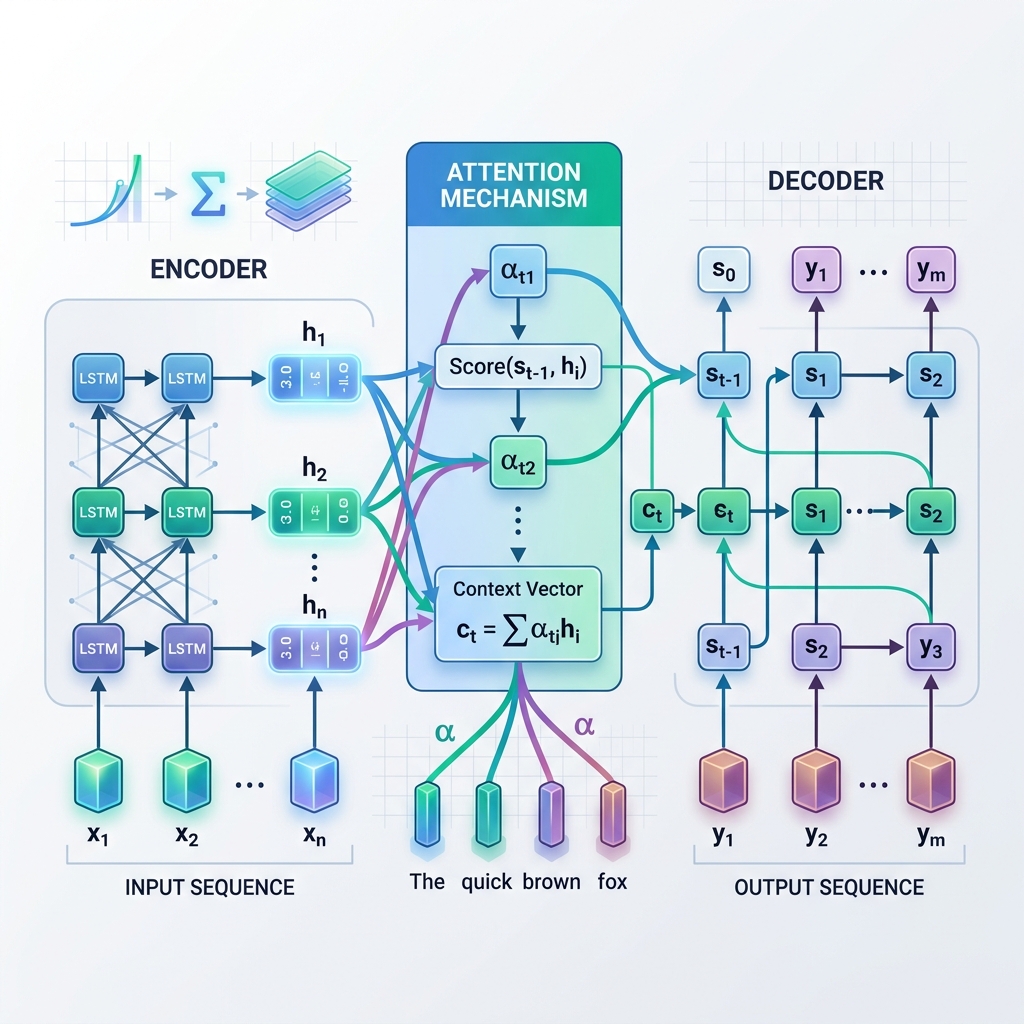
Em vez de confiar apenas em um único Vetor de Contexto estático do passo final do codificador, a Atenção permite ao decodificador “olhar para trás” para todos os estados ocultos intermediários do codificador em cada etapa do processo de decodificação. Isso significa que o modelo se concentra (presta atenção) dinamicamente em diferentes partes da sequência de entrada, dependendo da palavra que está gerando no momento.
Como funciona a atenção: passo a passo
Em cada etapa de decodificação $t$:
- Calcular pontuações de alinhamento ($e_{t, j}$): O modelo compara o estado oculto do decodificador atual $s_{t-1}$ com cada estado oculto do codificador $h_j$ para medir o quão relevante é o estado do codificador $j$ para a etapa atual do decodificador. $$e_{t, j} = \text{score}(s_{t-1}, h_j)$$
- Calcular pesos de atenção ($\alpha_{t, j}$): As pontuações de alinhamento são normalizadas usando uma função softmax para transformá-las em probabilidades (pesos) que somam 1. $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$
- Gerar o Vetor de Contexto Dinâmico ($c_t$): O vetor de contexto é calculado como a soma ponderada de todos os estados ocultos do codificador. $$c_t = \sum_j \alpha_{t, j} h_j$$
- Prever o Token: O decodificador combina o vetor de contexto dinâmico $c_t$ com seu estado atual $s_t$ para prever o próximo token de saída.
4. Passo a passo detalhado dos mecanismos Seq2Seq e de atenção
Para realmente apreciar a engenharia por trás desses mecanismos, vamos traçar as etapas matemáticas e operacionais da arquitetura clássica Sequence-to-Sequence, seguidas pelas abordagens de atenção de Bahdanau (aditiva) e Luong (multiplicativa).
Baseline: Passo a passo da arquitetura clássica Sequence-to-Sequence (sem atenção)
Antes de explorar a atenção, vamos traçar como a arquitetura padrão Sequence-to-Sequence (Encoder-Decoder) processa as informações sequencialmente:
- Fase de Codificação:
Para uma sequência de entrada $x_1, x_2, \dots, x_T$:
- A cada etapa temporal $t$, a célula recorrente do Encoder (LSTM/GRU) atualiza seu estado oculto $h_t$ com base no token de entrada atual $x_t$ e no estado oculto anterior $h_{t-1}$: $$h_t = \text{RNN}{\text{enc}}(x_t, h{t-1})$$
- Geração do Vetor de Contexto:
- O estado oculto final do encoder $h_T$ atua como o vetor de contexto $c$ (a representação estática de gargalo): $$c = h_T$$
- Inicialização da Fase de Decodificação:
- O estado oculto inicial $s_0$ da célula do Decoder é inicializado diretamente com o vetor de contexto $c$: $$s_0 = c$$
- Etapa Autorregressiva do Decodificador:
- A cada etapa temporal de decodificação $t$, o Decodificador atualiza seu estado oculto $s_t$ com base no token previsto anterior $y_{t-1}$ e no estado oculto anterior $s_{t-1}$: $$s_t = \text{RNN}{\text{dec}}(y{t-1}, s_{t-1})$$
- Previsão de Tokens:
- A distribuição de probabilidade para o próximo token $y_t$ é calculada usando uma camada linear e uma ativação softmax aplicada ao estado do decodificador $s_t$: $$p(y_t | y_{<t}) = \text{softmax}(W_y s_t + b_y)$$
Abordagem 1: Passo a passo da atenção de Bahdanau (aditiva)
A atenção de Bahdanau também é chamada de atenção aditiva porque calcula as pontuações de alinhamento usando uma camada de rede neural feed-forward. Ela opera sob um fluxo de dependência do “estado anterior”:
- Inicialização / Dependência: Na etapa de decodificação $t$, o decodificador usa seu estado oculto anterior $s_{t-1}$ e os estados ocultos do codificador $h_j$ (para todas as etapas de entrada $j$) para calcular a atenção.
- Calcular Pontuações de Alinhamento (Aditivo): $$e_{t, j} = v_a^T \tanh(W_a s_{t-1} + U_a h_j)$$ Aqui, $W_a$ e $U_a$ são matrizes de pesos aprendíveis que projetam o estado do decodificador e os estados do codificador em um espaço compartilhado. Sua soma é passada por uma função de ativação $\tanh$ e, em seguida, projetada para um escalar usando o vetor de pesos $v_a$.
- Calcular Pesos de Atenção (Softmax): $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$ Isso normaliza as pontuações de alinhamento em uma distribuição de probabilidade sobre a sequência de entrada.
- Gerar Vetor de Contexto Dinâmico: $$c_t = \sum_j \alpha_{t, j} h_j$$ Essa é uma soma ponderada dos estados ocultos do codificador, representando as partes da sequência de entrada nas quais o modelo deve se concentrar.
- Atualizar Estado Oculto do Decodificador: O vetor de contexto $c_t$ é concatenado com a incorporação do token de saída anterior $y_{t-1}$ e passado para a célula recorrente do decodificador para calcular o estado atual do decodificador $s_t$: $$s_t = \text{RNN}(s_{t-1}, [c_t; y_{t-1}])$$
- Prever Token: O estado atual $s_t$ é usado para prever a probabilidade do próximo token.
Abordagem 2: Passo a passo da atenção de Luong (multiplicativa)
A atenção de Luong, introduzida logo após a de Bahdanau, é referida como atenção multiplicativa. Ela simplifica a computação e depende de um fluxo de dependência do “estado atual”:
- Atualizar Primeiro o Estado Oculto do Decodificador: Na etapa de decodificação $t$, o decodificador primeiro atualiza seu estado oculto para $s_t$ usando a transição recorrente normal, usando apenas o estado anterior $s_{t-1}$ e o token de saída anterior $y_{t-1}$: $$s_t = \text{RNN}(s_{t-1}, y_{t-1})$$
- Calcular Pontuações de Alinhamento (Multiplicativo):
Luong propôs três funções de pontuação alternativas. A mais amplamente utilizada é a forma General, que usa uma multiplicação de matrizes (daí, multiplicativa):
- General: $e_{t, j} = s_t^T W_a h_j$
- Dot: $e_{t, j} = s_t^T h_j$ (assume dimensionalidade igual)
- Concat: $e_{t, j} = v_a^T \tanh(W_a [s_t; h_j])$ A atenção multiplicativa é computacionalmente mais rápida e eficiente em termos de espaço do que a atenção aditiva porque pode ser calculada usando operações de multiplicação de matrizes altamente otimizadas.
- Calcular Pesos de Atenção (Softmax): $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$
- Gerar Vetor de Contexto Dinâmico: $$c_t = \sum_j \alpha_{t, j} h_j$$
- Calcular Estado Oculto de Atenção: Em vez de usar o estado do decodificador diretamente para previsão, o vetor de contexto $c_t$ e o estado atual $s_t$ são combinados usando uma camada linear e uma ativação $\tanh$ para produzir um estado oculto de atenção $\tilde{s}_t$: $$\tilde{s}_t = \tanh(W_c [c_t; s_t])$$
- Prever Token: O estado oculto de atenção $\tilde{s}t$ é usado para gerar a previsão final: $$p(y_t | y{<t}, x) = \text{softmax}(W_s \tilde{s}_t)$$
Comparação Arquitetônica
| Característica | Atenção Bahdanau (Aditiva) | Atenção Luong (Multiplicativa) |
|---|---|---|
| Pontuação Matemática | Usa uma rede feed-forward: $v_a^T \tanh(W_a s_{t-1} + U_a h_j)$ | Usa produto escalar ou multiplicação de matrizes: $s_t^T W_a h_j$ |
| Estado do Decodificador Usado | Usa o estado anterior do decodificador $s_{t-1}$. | Usa o estado atual do decodificador $s_t$. |
| Computação | Mais complexo, lento, mas altamente flexível. | Mais rápido, simples e altamente eficiente. |
5. O legado: Da atenção aos Transformers
O Mecanismo de Atenção foi inicialmente projetado como um complemento para melhorar as RNNs. No entanto, os pesquisadores logo perceberam que as camadas de atenção faziam todo o trabalho pesado, enquanto as estruturas recorrentes (RNNs/LSTMs) agiam como um gargalo computacional porque tinham que processar tokens sequencialmente.
Em 2017, os pesquisadores publicaram o artigo fundamental “Attention Is All You Need”, apresentando a arquitetura Transformer. O Transformer descartou as RNNs inteiramente, confiando exclusivamente na Self-Attention (Autoatenção) para processar sequências inteiras em paralelo.
Esse avanço é a base dos modernos modelos de linguagem grandes (LLMs) como GPT-4, Gemini e Claude, provando que a atenção é, de fato, o conceito mais poderoso no NLP moderno.