Sequence-to-Sequence (Seq2Seq) Mimarisi ve Attention Mekanizmasının Detaylı Analizi
Doğal Dil İşleme (NLP) ve Yapay Zeka dünyasında, dilleri çevirme, metinleri özetleme ve sohbet yanıtları oluşturma yeteneği büyük bir devrim geçirdi. Bu dönüşümün merkezinde Sequence-to-Sequence (Seq2Seq) mimarisi ve öncü Attention (Dikkat) Mekanizması yer almaktadır.
Modern Transformer modellerinin ortaya çıkışından önce, bu iki yenilik yapay öğrenmenin en büyük zorluklarından birini çözmüştü: Giriş ve çıkış dizilerinin uzunlukları farklı olduğunda bu dizileri birbirine eşlemek.
1. Temel: Sequence-to-Sequence (Seq2Seq) Nedir?
2014 yılında Google araştırmacıları ve diğer bilim insanları tarafından tanıtılan Sequence-to-Sequence (Seq2Seq) modeli, ardışık verileri işlemek için tasarlanmış bir kodlayıcı-kod çözücü (encoder-decoder) çerçevesidir. Giriş dizisi uzunluğunun çıkış dizisi uzunluğuyla eşleşmediği şu görevlerde yaygın olarak kullanılır:
- Makine Çevirisi: “How are you?” (3 kelime) cümlesini Türkçe “Nasılsın?” (1 kelime) veya İspanyolca “¿Cómo estás?” (2 kelime) olarak çevirmek.
- Metin Özetleme: 500 kelimelik bir makaleyi 50 kelimelik bir özete sıkıştırmak.
- Soru Cevaplama: Bir soru dizisini bir yanıt dizisiyle eşlemek.
Kodlayıcı-Kod Çözücü Mekanizması
Standart Seq2Seq modeli, genellikle LSTM (Long Short-Term Memory) veya GRU (Gated Recurrent Units) olan iki tekrarlayan sinir ağından (RNN) oluşur:
- Kodlayıcı (Encoder): Giriş dizisini kelime kelime (token by token) işler. Her adımda, mevcut giriş kelimesine ve önceki gizli durumuna bağlı olarak kendi gizli durumunu (hidden state) günceller. Tüm giriş işlendikten sonra, Kodlayıcının son gizli durumu yakalanır. Bu son duruma Bağlam Vektörü (Context Vector) (veya darboğaz vektörü) denir.
- Kod Çözücü (Decoder): Bağlam Vektörünü ilk gizli durumu olarak alır ve çıkış dizisini ardışık ve özyinelemeli olarak üretir. Her adımda, mevcut gizli durumuna ve önceden üretilen kelimeye dayanarak bir sonraki kelimeyi tahmin eder.
2. Darboğaz Problemi (Information Bottleneck)
Klasik Kodlayıcı-Kod Çözücü modeli büyük bir atılım olsa da, bilgi darboğazı olarak bilinen temel bir sınırlamadan muzdaripti.
Standart bir Seq2Seq modelinde kodlayıcı, giriş cümlesinin tüm anlamını — ister 5 ister 100 kelime olsun — sabit boyutlu tek bir Bağlam Vektörüne sıkıştırmak zorunda kalır.
Bunun sonucunda:
- Uzun Vadeli Bellek Kaybı: Daha uzun cümlelerde, kodlayıcı sona ulaştığında dizinin başındaki kısımlar unutulur.
- Performans Düşüşü: Giriş cümlesinin uzunluğu arttıkça çeviri veya özetleme kalitesi önemli ölçüde düşer.
Karmaşık bir paragrafı tek bir vektöre sıkıştırmak, bir kitabın koca bir bölümünü çevirmeden önce tek bir cümleyle özetlemeye çalışmaya benzer. Bilgi kaçınılmaz olarak kaybolur.
3. Attention Mekanizması: Bir Paradigma Değişimi
Bilgi darboğazını çözmek için, Dzmitry Bahdanau ve meslektaşları 2015 yılında Attention (Dikkat) Mekanizmasını tanıttı.
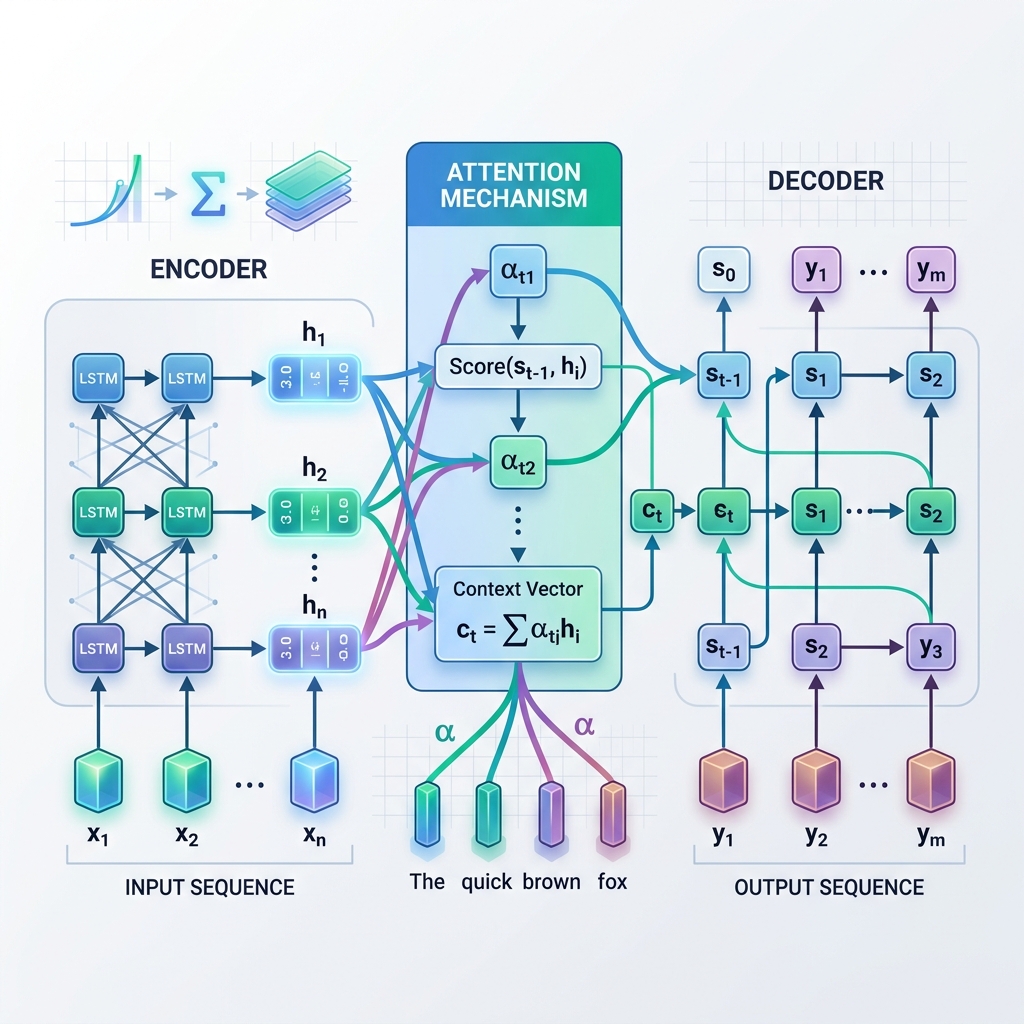
Attention, yalnızca kodlayıcının son adımından elde edilen tek bir statik Bağlam Vektörüne güvenmek yerine, kod çözücünün kod çözme sürecinin her adımında kodlayıcının tüm ara gizli durumlarına “geriye dönüp bakmasına” olanak tanır. Bu, modelin o anda ürettiği kelimeye bağlı olarak giriş dizisinin farklı bölümlerine dinamik olarak odaklandığı (dikkat ettiği) anlamına gelir.
Attention Nasıl Çalışır: Adım Adım
Her kod çözme adımı $t$ anında:
- Hizalama Skorlarını Hesaplama ($e_{t, j}$): Model, kodlayıcı durumu $j$‘nin mevcut kod çözücü adımıyla ne kadar ilgili olduğunu ölçmek için mevcut kod çözücü gizli durumu $s_{t-1}$ ile her bir kodlayıcı gizli durumu $h_j$‘yi karşılaştırır. $$e_{t, j} = \text{score}(s_{t-1}, h_j)$$
- Attention Ağırlıklarını Hesaplama ($\alpha_{t, j}$): Hizalama skorları, toplamı 1 olan olasılıklara (ağırlıklara) dönüştürülmek üzere bir softmax işlevi kullanılarak normalize edilir. $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$
- Dinamik Bağlam Vektörünü Oluşturma ($c_t$): Bağlam vektörü, tüm kodlayıcı gizli durumlarının ağırlıklı toplamı olarak hesaplanır. $$c_t = \sum_j \alpha_{t, j} h_j$$
- Kelimeyi Tahmin Etme: Kod çözücü, bir sonraki çıkış kelimesini tahmin etmek için dinamik bağlam vektörü $c_t$‘yi mevcut durumu $s_t$ ile birleştirir.
4. Seq2Seq ve Attention Mekanizmalarının Detaylı İncelemesi
Bu mekanizmaların arkasındaki mühendisliği gerçekten takdir etmek için önce klasik Sequence-to-Sequence mimarisinin, ardından hem Bahdanau (Toplamsal) hem de Luong (Çarpımsal) attention yaklaşımlarının matematiksel ve operasyonel adımlarını inceleyelim.
Temel Düzey: Klasik Sequence-to-Sequence Mimarisi İncelemesi (Attention Olmadan)
Attention mekanizmasını incelemeden önce, standart Sequence-to-Sequence (Encoder-Decoder) mimarisinin bilgiyi ardışık olarak nasıl işlediğini takip edelim:
- Kodlama (Encoding) Aşaması:
Bir giriş dizisi $x_1, x_2, \dots, x_T$ için:
- Her $t$ zaman adımında, Encoder yinelemeli hücresi (LSTM/GRU), mevcut giriş belirteci $x_t$ ve önceki gizli durum $h_{t-1}$ temelinde gizli durumunu $h_t$ günceller: $$h_t = \text{RNN}{\text{enc}}(x_t, h{t-1})$$
- Bağlam Vektörü Üretimi:
- Son encoder gizli durumu $h_T$, bağlam vektörü $c$ (statik darboğaz temsili) görevi görür: $$c = h_T$$
- Kod Çözme Aşaması Başlangıcı:
- Decoder yinelemeli hücresinin ilk gizli durumu $s_0$, doğrudan bağlam vektörü $c$ ile başlatılır: $$s_0 = c$$
- Decoder Otoregresif Adımı:
- Her kod çözme $t$ zaman adımında, Decoder, önceki tahmin edilen belirteç $y_{t-1}$ ve önceki gizli durum $s_{t-1}$ temelinde gizli durumunu $s_t$ günceller: $$s_t = \text{RNN}{\text{dec}}(y{t-1}, s_{t-1})$$
- Belirteç Tahmini:
- Bir sonraki belirteç $y_t$ için olasılık dağılımı, decoder durumu $s_t$‘ye uygulanan bir doğrusal katman ve bir softmax aktivasyonu kullanılarak hesaplanır: $$p(y_t | y_{<t}) = \text{softmax}(W_y s_t + b_y)$$
Yaklaşım 1: Bahdanau (Toplamsal) Attention İncelemesi
Bahdanau attention, uyum skorlarını (alignment scores) bir ileri beslemeli yapay sinir ağı katmanı kullanarak hesapladığı için toplamsal attention (additive attention) olarak da adlandırılır. Bir “önceki-durum” bağımlılık akışı altında çalışır:
- Başlatma / Bağımlılık: $t$ kod çözme (decoding) adımında, kod çözücü (decoder) attention hesaplamak için önceki gizli durumunu $s_{t-1}$ ve kodlayıcının (encoder) gizli durumlarını $h_j$ (tüm girdi adımları $j$ için) kullanır.
- Uyum Skorlarını Hesaplama (Toplamsal): $$e_{t, j} = v_a^T \tanh(W_a s_{t-1} + U_a h_j)$$ Burada, $W_a$ ve $U_a$, kod çözücü durumunu ve kodlayıcı durumlarını ortak bir alana projekte eden öğrenilebilir ağırlık matrisleridir. Toplamları bir $\tanh$ aktivasyon fonksiyonundan geçirilir ve ardından $v_a$ ağırlık vektörü kullanılarak bir skalere projekte edilir.
- Attention Ağırlıklarını Hesaplama (Softmax): $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$ Bu, uyum skorlarını girdi dizisi üzerinde bir olasılık dağılımına normalleştirir.
- Dinamik Bağlam Vektörünü Oluşturma: $$c_t = \sum_j \alpha_{t, j} h_j$$ Bu, kodlayıcının gizli durumlarının ağırlıklı toplamıdır ve modelin odaklanması gereken girdi dizisinin bölümlerini temsil eder.
- Kod Çözücü Gizli Durumunu Güncelleme: Bağlam vektörü $c_t$, önceki çıktı belirtecinin (token) gömmesi (embedding) $y_{t-1}$ ile birleştirilir ve mevcut kod çözücü durumunu $s_t$ hesaplamak için kod çözücünün yinelemeli hücresine iletilir: $$s_t = \text{RNN}(s_{t-1}, [c_t; y_{t-1}])$$
- Belirteç Tahmini: Mevcut durum $s_t$, bir sonraki belirtecin olasılığını tahmin etmek için kullanılır.
Yaklaşım 2: Luong (Çarpımsal) Attention İncelemesi
Bahdanau’nunkinden kısa bir süre sonra tanıtılan Luong attention, çarpımsal attention (multiplicative attention) olarak adlandırılır. Hesaplamayı basitleştirir ve bir “mevcut-durum” bağımlılık akışına dayanır:
- Önce Kod Çözücü Gizli Durumunu Güncelleme: $t$ kod çözme adımında, kod çözücü önce yalnızca önceki durum $s_{t-1}$ ve önceki çıktı belirteci $y_{t-1}$‘i kullanarak normal yinelemeli geçişle gizli durumunu $s_t$ olarak günceller: $$s_t = \text{RNN}(s_{t-1}, y_{t-1})$$
- Uyum Skorlarını Hesaplama (Çarpımsal):
Luong üç alternatif skor fonksiyonu önerdi. En yaygın kullanılanı, matris çarpımı kullanan (bu nedenle çarpımsal olan) General formudur:
- General: $e_{t, j} = s_t^T W_a h_j$
- Dot: $e_{t, j} = s_t^T h_j$ (eşit boyutluluk varsayar)
- Concat: $e_{t, j} = v_a^T \tanh(W_a [s_t; h_j])$ Çarpımsal attention, oldukça optimize edilmiş matris çarpım işlemleri kullanılarak hesaplanabildiği için toplamsal attention’dan hesaplama açısından daha hızlıdır ve alan açısından daha verimlidir.
- Attention Ağırlıklarını Hesaplama (Softmax): $$\alpha_{t, j} = \frac{\exp(e_{t, j})}{\sum_k \exp(e_{t, k})}$$
- Dinamik Bağlam Vektörünü Oluşturma: $$c_t = \sum_j \alpha_{t, j} h_j$$
- Attention Gizli Durumunu Hesaplama: Tahmin için doğrudan kod çözücü durumunu kullanmak yerine, bağlam vektörü $c_t$ ve mevcut durum $s_t$ doğrusal bir katman ve bir $\tanh$ aktivasyonu kullanılarak birleştirilerek bir attention gizli durumu $\tilde{s}_t$ üretilir: $$\tilde{s}_t = \tanh(W_c [c_t; s_t])$$
- Belirteç Tahmini: Attention gizli durumu $\tilde{s}t$ nihai tahmini oluşturmak için kullanılır: $$p(y_t | y{<t}, x) = \text{softmax}(W_s \tilde{s}_t)$$
Mimari Karşılaştırma
| Özellik | Bahdanau (Toplamsal) Attention | Luong (Çarpımsal) Attention |
|---|---|---|
| Matematiksel Skor | Bir ileri beslemeli ağ kullanır: $v_a^T \tanh(W_a s_{t-1} + U_a h_j)$ | Nokta çarpımı veya matris çarpımı kullanır: $s_t^T W_a h_j$ |
| Kullanılan Decoder Durumu | Önceki decoder durumu $s_{t-1}$‘i kullanır. | Mevcut decoder durumu $s_t$‘yi kullanır. |
| Hesaplama | Daha karmaşık, daha yavaş ama son derece esnek. | Daha hızlı, daha basit ve son derece verimli. |
5. Miras: Attention’dan Transformer Modellerine
Attention mekanizması başlangıçta RNN’leri geliştirmek için bir eklenti olarak tasarlanmıştı. Ancak araştırmacılar kısa sürede attention katmanlarının tüm ağır işleri yaptığını, tekrarlayan yapıların (RNN/LSTM) ise verileri sıralı olarak işlemek zorunda oldukları için hesaplama darboğazı oluşturduğunu fark ettiler.
2017 yılında araştırmacılar, “Attention Is All You Need” adlı dönüm noktası niteliğindeki makaleyi yayınlayarak Transformer mimarisini tanıttı. Transformer, RNN’leri tamamen devre dışı bırakarak tüm dizileri paralel olarak işlemek için yalnızca Self-Attention (Öz-Dikkat) mekanizmasına güvendi.
Bu buluş, GPT-4, Gemini ve Claude gibi modern Büyük Dil Modellerinin (LLM) temelini oluşturmakta ve attention mekanizmasının modern dil işlemedeki en güçlü kavram olduğunu kanıtlamaktadır.