GPT トランスフォーマーの仕組み:因果自己注意機構(Causal Self-Attention)の解説
GPT トランスフォーマーの仕組み:因果自己注意機構(Causal Self-Attention)の解説
近年、Generative Pre-trained Transformers(GPT)は人工知能に革命をもたらしました。コーディングアシスタントから対話型エージェントに至るまで、GPTベースのモデルは今日の最も先進的な生成アプリケーションを支えています。しかし、このテクノロジーは実際にどのように機能しているのでしょうか?
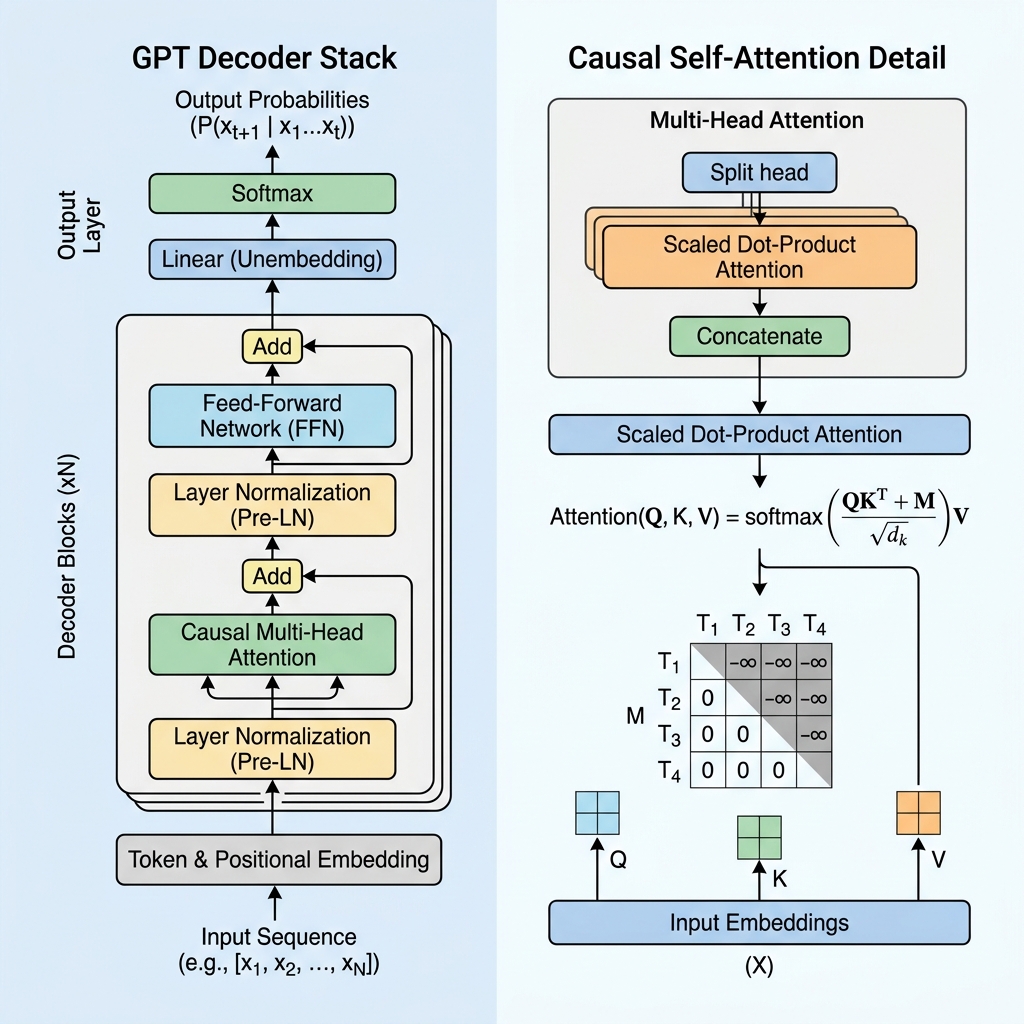
双方向に理解するのに対し、GPTは自己回帰的(autoregressive)な次のトークン予測のために設計された**デコーダー専用(Decoder-only)**のアーキテクチャです。このブログでは、GPTトランスフォーマーの仕組みを解き明かし、因果自己注意機構(causal self-attention)を深く掘り下げ、コードで実装します。
1. 自己回帰的な生成ループ
本質的に、GPTは自己回帰モデルです。これは、テキストのシーケンスを生成するために、すでに生成されたトークンを次の予測のコンテキストとして使用しながら、次のトークンを1つずつ予測することを意味します。
ワークフローは以下の手順に従います。
- 入力 (Input): モデルはプロンプトを受け取ります。例:
"Deep learning is"。 - 予測 (Prediction): モデルはこのプロンプトを処理し、語彙全体に対する確率分布を出力します。次のトークンをサンプリングします。例:
"awesome"。 - ループ (Loop): 新しいトークンが入力に追加され、
"Deep learning is awesome"になります。このシーケンスが次のステップの入力になります。 - 終了 (Termination): モデルが特殊なシーケンス終了(
[EOS])トークンを出力するか、定義された長さ制限に達するまで、プロセスが繰り返されます。
2. 因果マスキング:デコーダーの核心
BERTのようなエンコーダー専用モデルでは、すべてのトークンが過去と未来の両方を見渡して、他のすべてのトークンに注意を向けることができます。しかし、次のトークンを予測する生成モデルにとって、トレーニング中に未来を見ることは「カンニング」になります。
モデルが未来のトークンを見るのを防ぐために、GPTは因果自己注意(Causal Self-Attention)(またはマスクされた自己注意)を使用します。
因果マスク行列
自己注意の計算中、クエリ(Queries, $Q$)とキー(Keys, $K$)の点積を取ることで、トークン間の類似度スコアを計算します。
$$\text{Scores} = QK^T$$
因果性を強制するために、対角線より上のすべての値が $-\infty$(負の無限大)に設定され、対角線上およびそれ以下の値が 0 であるマスク行列 $M$ を適用します。softmax関数を適用する前に、このマスクをスコアに加算します。
$$\text{Masked Scores} = \frac{QK^T}{\sqrt{d_k}} + M$$
$$M = \begin{pmatrix} 0 & -\infty & -\infty & \dots & -\infty \\ 0 & 0 & -\infty & \dots & -\infty \\ 0 & 0 & 0 & \dots & -\infty \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & 0 & \dots & 0 \end{pmatrix}$$
softmax関数を適用すると、$e^{-\infty}$ は $0$ になります。その結果、未来のトークンに対する注意の重み(Attention Weights)は正確に0になり、未来 of トークンは現在のトークンから見えなくなります。
3. GPTレイヤーの主要なアーキテクチャブロック
GPTモデルは、スタックされたトランスフォーマーデコーダーレイヤーで構成されています。各レイヤーには、いくつかの重要なコンポーネントが含まれています。
A. 入力埋め込みと位置エンコーディング (Embeddings & Positional Encoding)
- トークン化: 生テキストは、バイトペアエンコーディング(BPE)を使用してサブワードトークンに分割されます。
- トークン埋め込み (Token Embeddings): 各トークンが高次元ベクトルにマッピングされます。
- 学習された位置埋め込み: 自己注意には固有の順序感覚がないため、GPTはトークン埋め込みに学習された位置埋め込みベクトルを追加し、モデルがシーケンス内の各トークンの位置を把握できるようにします。
B. 前層正規化 (Pre-Layer Normalization / Pre-LN)
残差接続の加算の後にレイヤー正規化を適用していた元のトランスフォーマーアーキテクチャ(Post-LN)とは異なり、現代のGPTアーキテクチャは、注意層およびフィードフォワード層の前にレイヤー正規化を適用します。
$$x_{l+1} = x_l + \text{Attention}(\text{LayerNorm}(x_l))$$
Pre-LNはトレーニング中の勾配を安定させ、数千億のパラメータを持つ非常に深いネットワークの安定したトレーニングを可能にします。
C. フィードフォワードネットワーク (Feed-Forward Network / FFN)
注意ブロックに続いて、各トークンの表現は、2つの線形変換と活性化関数(通常はGeLU)で構成される多層パーセプトロン(MLP)を通過します。
$$\text{FFN}(x) = \max(0, x W_1 + b_1) W_2 + b_2$$
4. サンプリングの仕組み(ロジットからトークンへ)
最終的なデコーダーブロックは、各位置の Logits と呼ばれる生スコアのベクトルを出力します。softmax関数を使用して、これらのロジットを確率に変換します。生成されるテキストのランダム性を制御するために、サンプリング中にパラメータを適用します。
- 温度 ($T$): softmaxの前にロジットをスケーリングします。温度が低い(例: $T = 0.2$)と、モデルは決定論的かつ集中したものになり、温度が高い(例: $T = 0.8$)と、創造性と多様性が高まります。
- Top-K: 次のトークンの選択肢を、確率の最も高い上位 $K$ 個のトークンに制限します。
- Top-P(ニュークリアスサンプリング): 確率分布を累積し、累積確率が $P$(例: $P = 0.9$)を超える最小のトークンセットから選択します。
5. 因果自己注意機構の PyTorch 実装
以下は、因果マスキングを使用した因果自己注意機構を示す自己完結型の PyTorch 実装です。
import torch
import torch.nn as nn
import torch.nn.functional as F
class CausalSelfAttention(nn.Module):
def __init__(self, d_model, n_heads):
super().__init__()
assert d_model % n_heads == 0
self.d_model = d_model
self.n_heads = n_heads
self.d_k = d_model // n_heads
# Query、Key、Valueの射影層
self.q_proj = nn.Linear(d_model, d_model)
self.k_proj = nn.Linear(d_model, d_model)
self.v_proj = nn.Linear(d_model, d_model)
self.out_proj = nn.Linear(d_model, d_model)
def forward(self, x):
batch_size, seq_len, d_model = x.size()
# 1. 入力を Q, K, V に射影
Q = self.q_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
K = self.k_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
V = self.v_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
# 2. 生の注意スコアを計算
scores = torch.matmul(Q, K.transpose(-2, -1)) / (self.d_k ** 0.5)
# 3. 因果マスクの作成と適用
# 負の無限大で満たされた上三角マスク
mask = torch.triu(torch.ones(seq_len, seq_len, device=x.device), diagonal=1).bool()
scores = scores.masked_fill(mask, float('-inf'))
# 4. Softmax により -inf は確率 0 に変換される
attn_weights = F.softmax(scores, dim=-1)
# 5. 値の加重平均を計算して出力
context = torch.matmul(attn_weights, V)
context = context.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)
return self.out_proj(context)
# クイック検証実行
if __name__ == "__main__":
# バッチサイズ = 1, シーケンス長 = 4, モデル次元 = 8, ヘッド数 = 2
x = torch.randn(1, 4, 8)
attention_layer = CausalSelfAttention(d_model=8, n_heads=2)
output = attention_layer(x)
print("入力形状:", x.shape)
print("出力形状:", output.shape)
6. アーキテクチャの比較
| 特徴 | BERT(エンコーダーのみ) | GPT(デコーダーのみ) | 元のトランスフォーマー |
|---|---|---|---|
| 主なタスク | 理解 / 抽出 | 生成 / 統合 | 翻訳 / シーケンス変換 |
| 注意タイプ | 双方向自己注意 | 因果マスク自己注意 | 双方向および因果クロス注意 |
| マスキング | マスクされたトークン ([MASK]) |
因果三角マスキング | デコーダー内の因果マスキング |
| 処理 | シーケンス全体を一度に処理 | 自己回帰的なトークン生成 | エンコーダーが一度処理しデコーダーが生成 |
結論
エンコーダーを排除し、因果マスク自己注意に完全に焦点を当てることで、GPTは生成モデルのスケーリングの道を開きました。次のトークンを予測するというシンプルなルールと、大規模な並列トレーニングの組み合わせにより、GPTモデルは論理、コード、および言語の豊かな表現を捉えることができ、現代の認知AIの基礎を築いています。