كيف يعمل نموذج GPT Transformer: شرح آلية الانتباه الذاتي السببي
في السنوات الأخيرة، أحدثت النماذج التوليدية مسبقة التدريب (GPT) ثورة حقيقية في مجالات الذكاء الاصطناعي. من مساعدي البرمجة إلى برمجيات المحادثة التفاعلية، تشغل النماذج القائمة على GPT أكثر التطبيقات التوليدية تقدمًا اليوم. ولكن كيف تعمل هذه التكنولوجيا فعليًا؟
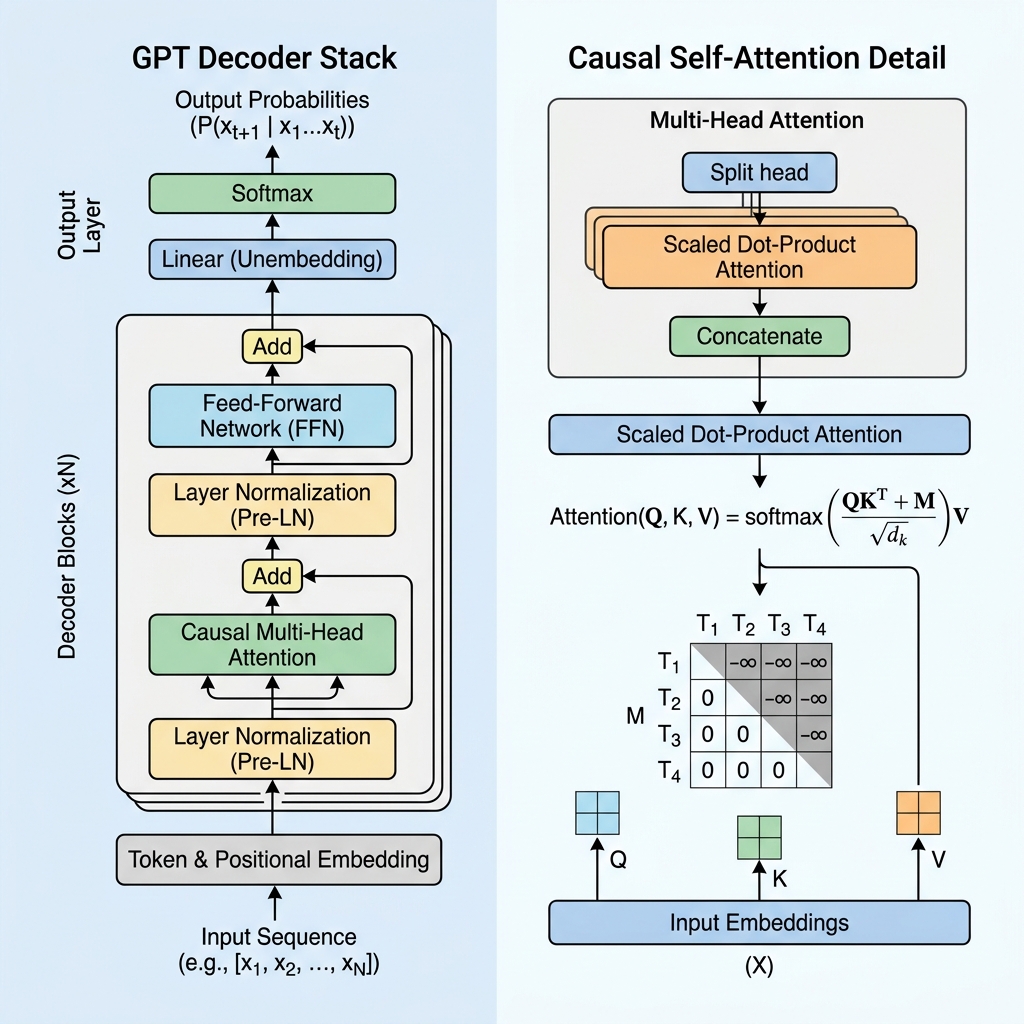
بينما تستخدم نماذج مثل BERT جزء الترميز (Encoder) من نموذج Transformer لفهم النصوص بشكل ثنائي الاتجاه، فإن GPT يعتمد على بنية فك الترميز فقط (Decoder-only) المصممة للتنبؤ بالتوكن التالي بشكل تكراري تلقائي (autoregressive). في هذه التدوينة، سنزيل الغموض عن كيفية عمل GPT Transformer، ونغوص عميقًا في آلية الانتباه الذاتي السببي (causal self-attention)، ونقوم بتنفيذها برمجياً.
1. حلقة التوليد التكراري التلقائي (Autoregressive Loop)
في جوهره، يعتبر GPT نموذجًا تكراريًا تلقائيًا. هذا يعني أنه لتوليد سلسلة من النصوص، فإنه يتنبأ بالتوكن التالي واحدًا تلو الآخر، مستخدمًا التوكنات التي قام بتوليدها بالفعل كسياق للتنبؤ التالي.
يتبع سير العمل الخطوات التالية:
- المدخلات (Input): يستقبل النموذج نصًا تمهيديًا (prompt):
"Deep learning is". - التنبؤ (Prediction): يعالج النموذج هذا النص ويخرج توزيعًا احتماليًا على كامل مفرداته. ثم يختار التوكن التالي:
"awesome". - الحلقة (Loop): يتم إلحاق التوكن الجديد بالمدخلات، لتصبح:
"Deep learning is awesome". تصبح هذه السلسلة هي المدخل للخطوة التالية. - الإنهاء (Termination): تتكرر العملية حتى يخرج النموذج توكنًا خاصًا يشير إلى نهاية السلسلة (
[EOS]) أو يصل إلى حد الطول المحدد مسبقًا.
2. القناع السببي (Causal Masking): قلب المرمز (Decoder)
في النماذج التي تعتمد على الترميز فقط مثل BERT، يمكن لكل توكن الانتباه إلى كل توكن آخر، والنظر إلى الماضي والمستقبل على حد سواء. ومع ذلك، بالنسبة لنموذج توليدي يتنبأ بالتوكن التالي، فإن النظر إلى المستقبل أثناء التدريب يعتبر “غشًا”.
لمنع النموذج من النظر إلى التوكنات المستقبلية، يستخدم GPT الانتباه الذاتي السببي (Causal Self-Attention) أو الانتباه الذاتي المقنع.
مصفوفة القناع السببي
أثناء حساب الانتباه الذاتي، نحسب درجات التشابه بين التوكنات عن طريق ضرب Queries ($Q$) في Keys ($K$) ضرباً نقطياً:
$$\text{Scores} = QK^T$$
لفرض السببية، نطبق مصفوفة قناع $M$ حيث يتم تعيين جميع القيم فوق القطر الرئيسي إلى $-\infty$ (سالب ما لا نهاية)، والقيم على القطر وتحته تكون 0. نضيف هذا القناع إلى الدرجات قبل تطبيق دالة softmax:
$$\text{Masked Scores} = \frac{QK^T}{\sqrt{d_k}} + M$$
$$M = \begin{pmatrix} 0 & -\infty & -\infty & \dots & -\infty \\ 0 & 0 & -\infty & \dots & -\infty \\ 0 & 0 & 0 & \dots & -\infty \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & 0 & \dots & 0 \end{pmatrix}$$
عند تطبيق دالة softmax، تتحول $e^{-\infty}$ إلى $0$. وبالتالي، تصبح أوزان الانتباه لأي توكنات مستقبلية 0 تمامًا، مما يجعل التوكنات المستقبلية غير مرئية بالنسبة للتوكن الحالي.
3. المكونات الهيكلية الأساسية لطبقة GPT
يتكون نموذج GPT من طبقات متتالية من فك ترميز Transformer. تحتوي كل طبقة على عدة مكونات حاسمة:
أ. تمثيلات المدخلات والترميز الموضعي (Embeddings & Positional Encoding)
- التقطيع (Tokenization): يتم تقسيم النص الخام إلى توكنات كلمات فرعية باستخدام ترميز زوج البايت (BPE).
- تمثيل التوكنات (Token Embeddings): يتم تمثيل كل توكن في متجه عالي الأبعاد.
- الترميز الموضعي المتعلم: نظرًا لأن الانتباه الذاتي ليس لديه شعور متأصل بالترتيب، يضيف GPT متجهات ترميز موضعية متعلمة إلى تمثيلات التوكنات، مما يسمح للنموذج بمعرفة موضع كل توكن في السلسلة.
ب. تطبيع الطبقة المسبق (Pre-Layer Normalization / Pre-LN)
على عكس بنية Transformer الأصلية، التي طبقت تطبيع الطبقة بعد الجمع المتبقي (Post-LN)، تطبق بنيات GPT الحديثة تطبيع الطبقة قبل طبقات الانتباه والتمرير الأمامي:
$$x_{l+1} = x_l + \text{Attention}(\text{LayerNorm}(x_l))$$
يساعد Pre-LN في استقرار الانحدارات (Gradients) أثناء التدريب، مما يسمح بتدريب نماذج عميقة جدًا تحتوي على مئات المليارات من المعاملات بشكل مستقر.
ج. شبكة التمرير الأمامي (Feed-Forward Network / FFN)
بعد كتلة الانتباه، يمر تمثيل كل توكن عبر بيرسبترون متعدد الطبقات (MLP) يتكون من تحويلين خطيين ودالة تفعيل (عادةً GeLU):
$$\text{FFN}(x) = \max(0, x W_1 + b_1) W_2 + b_2$$
4. آليات الاختيار والتدريج (من Logits إلى Tokens)
تخرج كتلة فك الترميز النهائية متجهًا من الدرجات الخام يسمى Logits لكل موضع. نقوم بتحويل هذه القيم إلى احتمالات باستخدام دالة softmax. للتحكم في عشوائية النص المولد، نطبق معاملات أثناء التوليد والاختيار:
- درجة الحرارة ($T$): تقوم بتدرج قيم logits قبل الـ softmax. درجة الحرارة المنخفضة (مثلاً $T = 0.2$) تجعل النموذج محددًا ومستهدفًا، بينما تزيد درجة الحرارة المرتفعة (مثلاً $T = 0.8$) من الإبداع والتنوع.
- Top-K: يحصر خيارات التوكن التالي في أعلى $K$ توكنات احتمالاً.
- Top-P (Nucleus Sampling): يجمع توزيع الاحتمالات ويختار من أصغر مجموعة من التوكنات التي يتجاوز احتمالها التراكمي القيمة $P$ (مثلاً $P = 0.9$).
5. كود بلغة بايثون لتنفيذ الانتباه الذاتي السببي باستخدام PyTorch
فيما يلي نموذج برمجي مستقل مكتوب باستخدام مكتبة PyTorch لتوضيح كيفية عمل الانتباه الذاتي السببي مع القناع السببي:
import torch
import torch.nn as nn
import torch.nn.functional as F
class CausalSelfAttention(nn.Module):
def __init__(self, d_model, n_heads):
super().__init__()
assert d_model % n_heads == 0
self.d_model = d_model
self.n_heads = n_heads
self.d_k = d_model // n_heads
# إسقاطات لـ Query و Key و Value
self.q_proj = nn.Linear(d_model, d_model)
self.k_proj = nn.Linear(d_model, d_model)
self.v_proj = nn.Linear(d_model, d_model)
self.out_proj = nn.Linear(d_model, d_model)
def forward(self, x):
batch_size, seq_len, d_model = x.size()
# 1. إسقاط المدخلات إلى Q, K, V
Q = self.q_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
K = self.k_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
V = self.v_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
# 2. حساب درجات الانتباه الخام
scores = torch.matmul(Q, K.transpose(-2, -1)) / (self.d_k ** 0.5)
# 3. إنشاء وتطبيق القناع السببي
# قناع مثلثي علوي مملوء بسالب ما لا نهاية
mask = torch.triu(torch.ones(seq_len, seq_len, device=x.device), diagonal=1).bool()
scores = scores.masked_fill(mask, float('-inf'))
# 4. دالة Softmax تحول سالب ما لا نهاية إلى احتمال 0
attn_weights = F.softmax(scores, dim=-1)
# 5. حساب المجموع الموزون للقيم والمخرجات
context = torch.matmul(attn_weights, V)
context = context.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)
return self.out_proj(context)
# تشغيل سريع للتحقق
if __name__ == "__main__":
# حجم الحزمة = 1، طول السلسلة = 4، أبعاد النموذج = 8، رأسان انتباه
x = torch.randn(1, 4, 8)
attention_layer = CausalSelfAttention(d_model=8, n_heads=2)
output = attention_layer(x)
print("أبعاد المدخلات:", x.shape)
print("أبعاد المخرجات:", output.shape)
6. مقارنة هيكلية للنماذج
| الميزة | BERT (Encoder-only) | GPT (Decoder-only) | Transformer الأصلي |
|---|---|---|---|
| المهمة الرئيسية | الفهم والاستخلاص | التوليد والتركيب | الترجمة ومعالجة السلاسل |
| نوع الانتباه | انتباه ذاتي ثنائي الاتجاه | انتباه ذاتي مقنع سببي | انتباه متقاطع ثنائي الاتجاه وسببي |
| آلية المقنعة | توكنات مقنعة ([MASK]) |
قناع مثلثي سببي | قناع سببي في وحدة فك الترميز |
| طريقة المعالجة | يعالج السلسلة كاملة دفعة واحدة | توليد تكراري تلقائي للتوكنات | يحلل المرمز النص مرة واحدة، ويفك المرمز توليداً |
خاتمة
من خلال التخلي عن المرمز والتركيز بالكامل على الانتباه الذاتي السببي المقنع، مهد GPT الطريق لتوسيع النماذج التوليدية بشكل هائل. إن القاعدة البسيطة المتمثلة في التنبؤ بالتوكن التالي، إلى جانب التدريب المتوازي الضخم، تسمح لنماذج GPT بالتقاط تمثيلات غنية للمنطق، الأكواد البرمجية، واللغات الطبيعية، مما يشكل حجر الأساس للذكاء الاصطناعي المعرفي الحديث.