GPT ट्रांसफॉर्मर कैसे काम करता है? कॉज़ल सेल्फ-अटेंशन की व्याख्या
GPT ट्रांसफॉर्मर कैसे काम करता है? कॉज़ल सेल्फ-अटेंशन की व्याख्या
मूल रूप से, जीपीटी एक ऑटोरेग्रेसिव मॉडल है। इसका मतलब है कि टेक्स्ट की एक श्रृंखला तैयार करने के लिए, यह एक-एक करके अगले टोकन की भविष्यवाणी करता है, और जिन टोकन को यह पहले ही तैयार कर चुका है उन्हें अगली भविष्यवाणी के लिए संदर्भ (context) के रूप में उपयोग करता है।
इसका कार्यप्रवाह इन चरणों पर आधारित होता है:
- इनपुट (Input): मॉडल को एक संकेत (prompt) मिलता है:
"Deep learning is"। - भविष्यवाणी (Prediction): मॉडल इस इनपुट को संसाधित करता है और अपनी पूरी शब्दावली पर एक संभावित वितरण (probability distribution) आउटपुट करता है। यह अगला टोकन चुनता है:
"awesome"। - लूप (Loop): नया टोकन इनपुट के साथ जोड़ दिया जाता है, जिससे वाक्य बन जाता है:
"Deep learning is awesome"। अब यह श्रृंखला अगले चरण के लिए इनपुट बन जाती है। - समाप्ति (Termination): यह प्रक्रिया तब तक दोहराई जाती है जब तक कि मॉडल एक विशेष एंड-ऑफ-सीक्वेंस टोकन (
[EOS]) आउटपुट नहीं करता या पहले से निर्धारित लंबाई की सीमा तक नहीं पहुंच जाता।
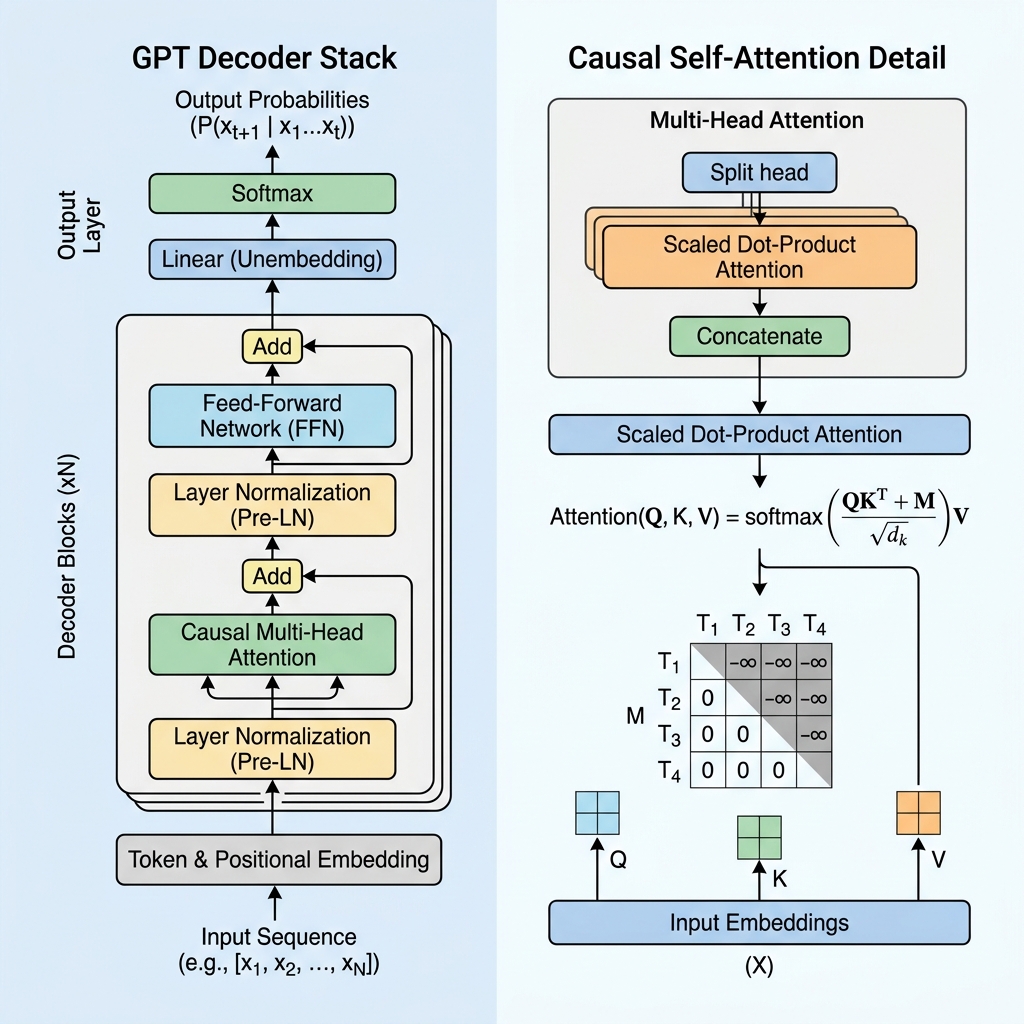
2. कॉज़ल मास्किंग (Causal Masking): डिकोडर का दिल
BERT जैसे एन्कोडर-ओनली मॉडल में, प्रत्येक टोकन अतीत और भविष्य दोनों ओर देखकर वाक्य के हर दूसरे टोकन पर ध्यान केंद्रित कर सकता है। हालांकि, एक ऐसे जेनरेटिव मॉडल के लिए जो अगले टोकन की भविष्यवाणी कर रहा है, ट्रेनिंग के दौरान भविष्य के टोकन को देखना “धोखाधड़ी” माना जाएगा।
मॉडल को भविष्य के टोकन देखने से रोकने के लिए, GPT कॉज़ल सेल्फ-अटेंशन (Causal Self-Attention) या masked सेल्फ-अटेंशन का उपयोग करता है।
कॉज़ल मास्क मैट्रिक्स
सेल्फ-अटेंशन की गणना के दौरान, हम क्वेरीज़ ($Q$) और कीज़ ($K$) का डॉट प्रोडक्ट लेकर टोकन के बीच समानता के स्कोर की गणना करते हैं:
$$\text{Scores} = QK^T$$
कार्यप्रवाह को क्रमबद्ध रखने के लिए, हम एक मास्क मैट्रिक्स $M$ लागू करते हैं जहाँ विकर्ण (diagonal) से ऊपर के सभी मानों को $-\infty$ (ऋणात्मक अनंत) पर सेट किया जाता है, और विकर्ण पर तथा उसके नीचे के मान 0 होते हैं। हम सॉफ्टमैक्स (softmax) फ़ंक्शन को लागू करने से पहले इस मास्क को स्कोर में जोड़ते हैं:
$$\text{Masked Scores} = \frac{QK^T}{\sqrt{d_k}} + M$$
$$M = \begin{pmatrix} 0 & -\infty & -\infty & \dots & -\infty \\ 0 & 0 & -\infty & \dots & -\infty \\ 0 & 0 & 0 & \dots & -\infty \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & 0 & \dots & 0 \end{pmatrix}$$
जब हम सॉफ्टमैक्स फ़ंक्शन को लागू करते हैं, तो $e^{-\infty}$ शून्य (0) बन जाता है। परिणामस्वरूप, भविष्य के किसी भी टोकन के लिए अटेंशन वैल्यू बिल्कुल 0 हो जाती हैं, जिससे भविष्य के टोकन वर्तमान टोकन के लिए अदृश्य हो जाते हैं।
3. जीपीटी लेयर के मुख्य घटक
एक जीपीटी मॉडल ट्रांसफॉर्मर डिकोडर लेयर के एक समूह से मिलकर बना होता है। प्रत्येक लेयर में कई महत्वपूर्ण घटक होते हैं:
क. इनपुट एम्बेडिंग और पोज़िशन कोडिंग (Embeddings & Positional Encoding)
- टोकनाइज़ेशन (Tokenization): कच्चे टेक्स्ट को बाइट पेयर एन्कोडिंग (BPE) का उपयोग करके उप-शब्द टोकन में विभाजित किया जाता है।
- टोकन एम्बेडिंग (Token Embeddings): प्रत्येक टोकन को एक बहुआयामी वेक्टर पर मैप किया जाता है।
- सीखी गई पोज़िशन एम्बेडिंग: चूंकि सेल्फ-अटेंशन में क्रम की कोई सहज भावना नहीं होती है, इसलिए GPT टोकन एम्बेडिंग में सीखे गए पोज़िशन वेक्टर जोड़ता है, जिससे मॉडल को पता चलता है कि श्रृंखला में प्रत्येक टोकन किस स्थान पर है।
ख. प्री-लेयर नॉर्मलाइज़ेशन (Pre-Layer Normalization / Pre-LN)
मूल ट्रांसफॉर्मर आर्किटेक्चर के विपरीत, जो अवशेषों के जोड़ने के बाद लेयर नॉर्मलाइज़ेशन को लागू करता था (Post-LN), आधुनिक जीपीटी मॉडल अटेंशन और फ़ीड फ़ॉरवर्ड लेयर से पहले लेयर नॉर्मलाइज़ेशन लागू करते हैं:
$$x_{l+1} = x_l + \text{Attention}(\text{LayerNorm}(x_l))$$
Pre-LN प्रशिक्षण के दौरान संतुलन को बनाए रखता है, जिससे सैकड़ों अरबों मापदंडों (parameters) वाले बहुत गहरे नेटवर्क का स्थिर प्रशिक्षण संभव होता है।
ग. फ़ीड-फ़ॉरवर्ड नेटवर्क (Feed-Forward Network / FFN)
अटेंशन ब्लॉक के बाद, प्रत्येक टोकन का प्रतिनिधित्व एक मल्टी-लेयर परसेप्ट्रॉन (MLP) से होकर गुज़रता है जिसमें दो रेखीय परिवर्तन (linear transformations) और एक सक्रियण फ़ंक्शन (आमतौर पर GeLU) होते हैं:
$$\text{FFN}(x) = \max(0, x W_1 + b_1) W_2 + b_2$$
4. सैंपलिंग के तरीके (लॉगिट्स से टोकन्स तक)
अंतिम डिकोडर ब्लॉक प्रत्येक पोज़िशन के लिए कच्चे स्कोर का एक वेक्टर आउटपुट करता है जिसे Logits कहा जाता है। हम सॉफ्टमैक्स फ़ंक्शन का उपयोग करके इन लॉगिट्स को संभावनाओं (probabilities) में बदलते हैं। तैयार टेक्स्ट में रचनात्मकता और विविधता को नियंत्रित करने के लिए, हम सैंपलिंग के दौरान विभिन्न मापदंडों का उपयोग करते हैं:
- तापमान ($T$): सॉफ्टमैक्स से पहले लॉगिट्स के स्केल को बदलता है। कम तापमान (जैसे $T = 0.2$) मॉडल को अधिक निश्चित और केंद्रित बनाता है, जबकि अधिक तापमान (जैसे $T = 0.8$) विविधता और रचनात्मकता को बढ़ाता है।
- Top-K: अगले टोकन के विकल्प को सबसे संभावित $K$ टोकन तक सीमित करता है।
- Top-P (Nucleus Sampling): संभावित वितरण को जोड़ता है और उन टोकन के सबसे छोटे सेट में से चुनता है जिनका संचयी संभावना $P$ (जैसे $P = 0.9$) से अधिक हो जाता है।
5. पायथन और PyTorch में कॉज़ल सेल्फ-अटेंशन का कोड
नीचे PyTorch में एक पूर्ण कोड दिया गया है जो कॉज़ल मास्किंग के साथ कॉज़ल सेल्फ-अटेंशन को दर्शाता है:
import torch
import torch.nn as nn
import torch.nn.functional as F
class CausalSelfAttention(nn.Module):
def __init__(self, d_model, n_heads):
super().__init__()
assert d_model % n_heads == 0
self.d_model = d_model
self.n_heads = n_heads
self.d_k = d_model // n_heads
# Query, Key और Value के लिए अनुमान (Projections)
self.q_proj = nn.Linear(d_model, d_model)
self.k_proj = nn.Linear(d_model, d_model)
self.v_proj = nn.Linear(d_model, d_model)
self.out_proj = nn.Linear(d_model, d_model)
def forward(self, x):
batch_size, seq_len, d_model = x.size()
# 1. इनपुट को Q, K, V पर अनुमानित करें
Q = self.q_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
K = self.k_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
V = self.v_proj(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
# 2. अटेंशन स्कोर की गणना करें
scores = torch.matmul(Q, K.transpose(-2, -1)) / (self.d_k ** 0.5)
# 3. कॉज़ल मास्क बनाएं और लागू करें
# ऋणात्मक अनंतता से भरा हुआ ऊपरी त्रिकोणीय मास्क
mask = torch.triu(torch.ones(seq_len, seq_len, device=x.device), diagonal=1).bool()
scores = scores.masked_fill(mask, float('-inf'))
# 4. सॉफ्टमैक्स ऋणात्मक अनंतता को 0 की संभावना में बदल देता है
attn_weights = F.softmax(scores, dim=-1)
# 5. वैल्यू का भारित योग लें और आउटपुट प्राप्त करें
context = torch.matmul(attn_weights, V)
context = context.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)
return self.out_proj(context)
# त्वरित सत्यापन कोड
if __name__ == "__main__":
# बैच आकार = 1, अनुक्रम लंबाई = 4, मॉडल आयाम = 8, 2 अटेंशन हेड्स
x = torch.randn(1, 4, 8)
attention_layer = CausalSelfAttention(d_model=8, n_heads=2)
output = attention_layer(x)
print("इनपुट आकार (Input Shape):", x.shape)
print("आउटपुट आकार (Output Shape):", output.shape)
6. आर्किटेक्चर की तुलना
| विशेषता | BERT (एन्कोडर केवल) | GPT (डिकोडर केवल) | मूल ट्रांसफॉर्मर |
|---|---|---|---|
| प्राथमिक कार्य | समझ / सूचना निकालना | जनरेशन / संश्लेषण | अनुवाद / अनुक्रम-से-अनुक्रम |
| ध्यान का प्रकार | द्विदिशीय सेल्फ-अटेंशन | कॉज़ल मास्कड सेल्फ-अटेंशन | द्विदिशीय और कॉज़ल क्रॉस-अटेंशन |
| मास्किंग | मास्कड टोकन ([MASK]) |
कॉज़ल त्रिकोणीय मास्किंग | डिकोडर में कॉज़ल मास्किंग |
| प्रसंस्करण | एक ही बार में पूरे अनुक्रम को संसाधित करता है | ऑटोरेग्रेसिव टोकन जनरेशन | एन्कोडर एक बार संसाधित करता है, डिकोडर उत्पन्न करता है |
निष्कर्ष
एन्कोडर को छोड़कर और पूरी तरह से कॉज़ल मास्कड सेल्फ-अटेंशन पर ध्यान केंद्रित करके, GPT ने रचनात्मक मॉडलिंग के रास्ते खोल दिए। अगले टोकन की भविष्यवाणी करने का सरल नियम, जब बड़े पैमाने पर समानांतर प्रशिक्षण के साथ जोड़ा जाता है, तो जीपीटी मॉडल को तर्क, कोडिंग और भाषा की समृद्ध आंतरिक छवियों को पकड़ने की अनुमति देता है, जो आज के उन्नत संज्ञानात्मक AI की आधारशिला है।